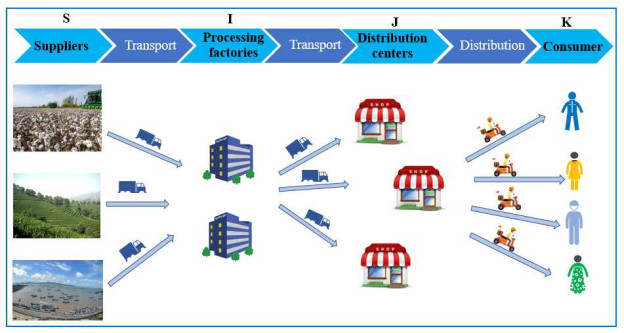
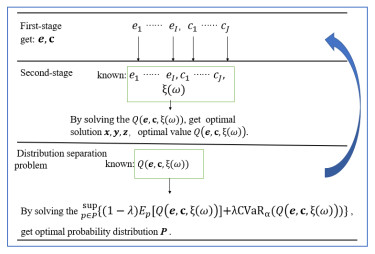
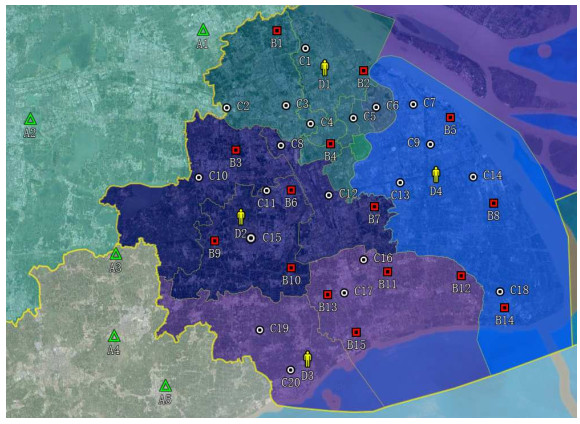
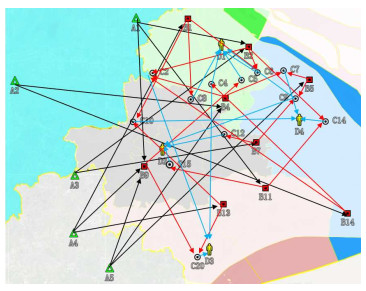
Robust optimization is a new modeling method to study uncertain optimization problems, which is to find a solution with good performance for all implementations of uncertain input. This paper studies the optimal location allocation of processing plants and distribution centers in uncertain supply chain networks under the worst case. Considering the uncertainty of the supply chain and the risk brought by the uncertainty, a data-driven two-stage sparse distributionally robust risk mixed integer optimization model is established. Based on the complexity of the model, a distribution-separation hybrid particle swarm optimization algorithm (DS-HPSO) is proposed to solve the model, so as to obtain the optimal location allocation scheme and the maximum expected return under the worst case. Then, taking the fresh-food supply chain under the COVID-19 as an example, the impact of uncertainty on location allocation is studied. This paper compares the data-driven two-stage sparse distributionally robust risk mixed integer optimization model with the two-stage sparse risk optimization model, and the data results show the robustness of this model. Moreover, this paper also discusses the impact of different risk weight on decision-making. Different decision makers can choose different risk weight and obtain corresponding benefits and optimal decisions. In addition, the DS-HPSO is compared with distribution-separation hybrid genetic algorithm and distributionally robust L-shaped method to verify the effectiveness of the algorithm.
Citation: Zhimin Liu. Data-driven two-stage sparse distributionally robust risk optimization model for location allocation problems under uncertain environment[J]. AIMS Mathematics, 2023, 8(2): 2910-2939. doi: 10.3934/math.2023152
Robust optimization is a new modeling method to study uncertain optimization problems, which is to find a solution with good performance for all implementations of uncertain input. This paper studies the optimal location allocation of processing plants and distribution centers in uncertain supply chain networks under the worst case. Considering the uncertainty of the supply chain and the risk brought by the uncertainty, a data-driven two-stage sparse distributionally robust risk mixed integer optimization model is established. Based on the complexity of the model, a distribution-separation hybrid particle swarm optimization algorithm (DS-HPSO) is proposed to solve the model, so as to obtain the optimal location allocation scheme and the maximum expected return under the worst case. Then, taking the fresh-food supply chain under the COVID-19 as an example, the impact of uncertainty on location allocation is studied. This paper compares the data-driven two-stage sparse distributionally robust risk mixed integer optimization model with the two-stage sparse risk optimization model, and the data results show the robustness of this model. Moreover, this paper also discusses the impact of different risk weight on decision-making. Different decision makers can choose different risk weight and obtain corresponding benefits and optimal decisions. In addition, the DS-HPSO is compared with distribution-separation hybrid genetic algorithm and distributionally robust L-shaped method to verify the effectiveness of the algorithm.

| [1] |
L. Cooper, Location-allocation problems, Oper. Res., 11 (1963), 331–343. https://doi.org/10.1287/opre.11.3.331 doi: 10.1287/opre.11.3.331

|
| [2] |
L. F. Gelders, L. M. Pintelon, L. N. V. Wassenhove, A location-allocation problem in a large Belgian brewery, Eur. J. Oper. Res., 28 (1987), 196–206. https://doi.org/10.1016/0377-2217(87)90218-9 doi: 10.1016/0377-2217(87)90218-9
|
| [3] |
L. Nick, A. V. Felipe, Points of distribution location and inventory management model for post-disaster humanitarian logistics, Transport. Res. Part E: Logist. Transport. Rev., 116 (2018), 1–24. https://doi.org/10.1016/j.tre.2018.05.003 doi: 10.1016/j.tre.2018.05.003
|
| [4] |
A. Moreno, D. Alem, D. Ferreira, A. Clark, An effective two-stage stochastic multi-trip location-transportation model with social concerns in relief supply chains, Eur. J. Oper. Res., 269 (2018), 1050–1071. https://doi.org/10.1016/j.ejor.2018.02.022 doi: 10.1016/j.ejor.2018.02.022
|
| [5] |
C. A. Irawan, D. Jones, Formulation and solution of a two-stage capacitated facility location problem with multilevel capacities, Ann. Oper. Res., 272 (2019), 41–67. https://doi.org/10.1007/s10479-017-2741-7 doi: 10.1007/s10479-017-2741-7
|
| [6] |
Z. M. Liu, R. P. Huang, S. T. Shao, Data-driven two-stage fuzzy random mixed integer optimization model for facility location problems under uncertain environment, AIMS Math., 7 (2022), 13292–13312. https://doi.org/10.3934/math.2022734 doi: 10.3934/math.2022734
|
| [7] |
N. Noyan, Risk-averse two-stage stochastic programming with an application to disaster management, Comput. Oper. Res., 39 (2012), 541–559. https://doi.org/10.1016/j.cor.2011.03.017 doi: 10.1016/j.cor.2011.03.017
|
| [8] |
N. Ricciardi, R. Tadei, A. Grosso, Optimal facility location with random throughput costs, Comput. Oper. Res., 29 (2002), 593–607. https://doi.org/10.1016/S0305-0548(99)00090-8 doi: 10.1016/S0305-0548(99)00090-8
|
| [9] |
S. Baptista, M. I. Gomes, A. P. Barbosa-Povoa, A two-stage stochastic model for the design and planning of a multi-product closed loop supply chain, Comput. Aided Chem. Eng., 30 (2012), 412–416. https://doi.org/10.1016/B978-0-444-59519-5.50083-6 doi: 10.1016/B978-0-444-59519-5.50083-6
|
| [10] |
J. Qin, H. Xiang, Y. Ye, L. L. Ni, A simulated annealing methodology to multiproduct capacitated facility location with stochastic demand, Sci. World J., 2015, 1–9. https://doi.org/10.1155/2015/826363 doi: 10.1155/2015/826363
|
| [11] | I. Litvinchev, M. Mata, L. Ozuna, Lagrangian heuristic for the two-stage capacitated facility location problem, Appl. Comput. Math., 11 (2012), 137–146. |
| [12] |
Z. M. Liu, S. J. Qu, Z. Wu, D. Q. Qu, J. H. Du, Two-stage mean-risk stochastic mixed integer optimization model for location-allocation problems under uncertain environment, J. Ind. Manag. Optim., 17 (2021), 2783–2804. https://doi.org/10.3934/jimo.2020094 doi: 10.3934/jimo.2020094
|
| [13] | A. L. Soyster, Convex programming with set-inclusive constraints and applications to inexact linear programming, Oper. Res., 21 (1973), 1154–1157. |
| [14] | A. Ben-Tal, L. E. Ghaoui, A. Nemirovski, Robust optimization, Princeton: Princeton University Press, 2009. |
| [15] |
D. Bertsimas, D. B. Brown, C. Caramanis, Theory and applications of robust optimization, SIAM Rev., 53 (2011), 464–501. https://doi.org/10.1137/080734510 doi: 10.1137/080734510
|
| [16] |
Z. Liu, Z. Wu, Y. Ji, S. J. Qu, H. Raza, Two-stage distributionally robust mixed-integer optimization model for three-level location-allocation problems under uncertain environment, Phys. A: Stat. Mech. Appl., 572 (2021), 125872. https://doi.org/10.1016/j.physa.2021.125872 doi: 10.1016/j.physa.2021.125872
|
| [17] |
X. J. Chen, A. Shapiro, H. L. Sun, Convergence analysis of sample average approximation of two-stage stochastic generalized equation, SIAM J. Optim., 29 (2019), 135–161. https://doi.org/10.1137/17M1162822 doi: 10.1137/17M1162822
|
| [18] |
X. J. Chen, H. L. Sun, H. F. Xu, Discrete approximation of two-stage stochastic and distributionally robust linear complementarity problems, Math. Program., 177 (2019), 255–289. https://doi.org/10.1007/s10107-018-1266-4 doi: 10.1007/s10107-018-1266-4
|
| [19] |
R. P. Huang, S. J. Qu, X. G. Yang, Z. M. Liu, Multi-stage distributionally robust optimization with risk aversion, J. Ind. Manag. Optim., 17 (2021), 233–259. https://doi.org/10.3934/jimo.2019109 doi: 10.3934/jimo.2019109
|
| [20] |
A. Klose, An LP-based heuristic for two-stage capacitated facility location problems, J. Oper. Res. Soc., 50 (1999), 157–166. https://doi.org/10.1057/palgrave.jors.2600675 doi: 10.1057/palgrave.jors.2600675
|
| [21] |
B. Li, Q. Xun, J. Sun, K. L. Teo, C. J. Yu, A model of distributionally robust two-stage stochastic convex programming with linear recourse, Appl. Math. Model., 58 (2018), 86–97. https://doi.org/10.1016/j.apm.2017.11.039 doi: 10.1016/j.apm.2017.11.039
|
| [22] |
B. Li, J. Sun, H. L. Xu, M. Zhang, A class of two-stage distributionally robust games, J. Ind. Manag. Optim., 15 (2019), 387–400. https://doi.org/10.3934/jimo.2018048 doi: 10.3934/jimo.2018048
|
| [23] |
Z. M. Liu, S. J. Qu, M. Goh, Z. Wu, R. P. Huang, G. Ma, Two-stage mean-risk stochastic optimization model for port cold storage capacity under pelagic fishery yield uncertainty, Phys. A: Stat. Mech. Appl., 541 (2020), 123338. https://doi.org/10.1016/j.physa.2019.123338 doi: 10.1016/j.physa.2019.123338
|
| [24] |
V. Rico-Ramirez, G. A. Iglesias-Silva, F. Gomez-De la Cruz, S. Hernandez-Castro, Two-stage stochastic approach to the optimal location of booster disinfection stations, Ind. Eng. Chem. Res., 46 (2007), 6284–6292. https://doi.org/10.1021/ie070141a doi: 10.1021/ie070141a
|
| [25] |
J. Sun, L. Z. Liao, B. Rodrigues, Quadratic two-stage stochastic optimization with coherent measures of risk, Math. Program., 168 (2018), 599–613. https://doi.org/10.1007/s10107-017-1131-x doi: 10.1007/s10107-017-1131-x
|
| [26] |
M. Dillon, F. Oliveira, B. Abbasi, A two-stage stochastic programming model for inventory management in the blood supply chain, Int. J. Prod. Econ., 187 (2017), 27–41. https://doi.org/10.1016/j.ijpe.2017.02.006 doi: 10.1016/j.ijpe.2017.02.006
|
| [27] |
K. L. Liu, Q. F. Li, Z. H. Zhang, Distributionally robust optimization of an emergency medical service station location and sizing problem with joint chance constraints, Transport. Res. Part B-Meth., 119 (2019), 79–101. https://doi.org/10.1016/j.trb.2018.11.012 doi: 10.1016/j.trb.2018.11.012
|
| [28] |
F. Maggioni, F. A. Potra, M. Bertocchi, A scenario-based framework for supply planning under uncertainty: stochastic programming versus robust optimization approaches, Comput. Manag. Sci., 14 (2017), 5–44. https://doi.org/10.1007/s10287-016-0272-3 doi: 10.1007/s10287-016-0272-3
|
| [29] |
R. Venkitasubramony, G. K. Adil, Designing a block stacked warehouse for dynamic and stochastic product flow: a scenario-based robust approach, Int. J. Prod. Res., 57 (2019), 1345–1365. https://doi.org/10.1080/00207543.2018.1472402 doi: 10.1080/00207543.2018.1472402
|
| [30] |
C. L. Hu, X. Liu, J. Lu, A bi-objective two-stage robust location model for waste-to-energy facilities under uncertainty, Decis. Support Syst., 99 (2017), 37–50. https://doi.org/10.1016/j.dss.2017.05.009 doi: 10.1016/j.dss.2017.05.009
|
| [31] |
S. Mišković, Z. Stanimirović, I. Grujičić, Solving the robust two-stage capacitated facility location problem with uncertain transportation costs, Optim. Lett., 11 (2017), 1169–1184. https://doi.org/10.1007/s11590-016-1036-2 doi: 10.1007/s11590-016-1036-2
|
| [32] |
J. Portilla, Image restoration through $l_0$ analysis-based sparse optimization in tight frames, 2009 16th IEEE International Conference on Image Processing (ICIP), 2009, 3909–3912. https://doi.org/10.1109/ICIP.2009.5413975 doi: 10.1109/ICIP.2009.5413975
|
| [33] |
M. Zibulevsky, M. Elad, L1-L2 optimization in signal and image processing, IEEE Signal Proc. Mag., 27 (2010), 76–88. https://doi.org/10.1109/MSP.2010.936023 doi: 10.1109/MSP.2010.936023
|
| [34] | L. Xu, S. C. Zheng, J. Y. Jia, Unnatural $l_0$ sparse representation for natural image deblurring, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2013, 1107–1114. |
| [35] | B. Y. Liu, L. Yang, J. Z. Huang, P. Meer, L. G. Gong, C. Kulikowski, Robust and fast collaborative tracking with two stage sparse optimization, In: K. Daniilidis, P. Maragos, N. Paragios, Computer vision–ECCV 2010, Lecture Notes in Computer Science, Vol. 6314, Springer, Berlin, Heidelberg, 2010. https://doi.org/10.1007/978-3-642-15561-1_45 |
| [36] |
X. F. Zhu, X. L. Li, S. C. Zhang, Block-row sparse multiview multilabel learning for image classification, IEEE Trans. Cybern., 46 (2016), 450–461. https://doi.org/10.1109/TCYB.2015.2403356 doi: 10.1109/TCYB.2015.2403356
|
| [37] |
H. Zhang, V. M. Patel, Convolutional sparse and low-rank coding-based image decomposition, IEEE Trans. Image Proc., 27 (2018), 2121–2133. https://doi.org/10.1109/TIP.2017.2786469 doi: 10.1109/TIP.2017.2786469
|
| [38] |
D. Bertsimas, R. Cory-Wright, A scalable algorithm for sparse portfolio selection, INFORMS J. Comput., 34 (2022), 1489–1511. https://doi.org/10.1287/ijoc.2021.1127 doi: 10.1287/ijoc.2021.1127
|
| [39] |
M. Dyer, L. Stougie, Computational complexity of stochastic programming problems, Math. Program., 106 (2006), 423–432. https://doi.org/10.1007/s10107-005-0597-0 doi: 10.1007/s10107-005-0597-0
|
| [40] |
M. Bansal, K. L. Huang, S. Mehrotra, Decomposition algorithms for two-stage distributionally robust mixed binary programs, SIAM J. Optim., 28 (2018), 2360–2383. https://doi.org/10.1137/17M1115046 doi: 10.1137/17M1115046
|
| [41] |
M. Bansal, S. Mehrotra, On solving two-stage distributionally robust disjunctive programs with a general ambiguity set, Eur. J. Oper. Res., 279 (2019), 296–307. https://doi.org/10.1016/j.ejor.2019.05.033 doi: 10.1016/j.ejor.2019.05.033
|
| [42] | L. R. Medsker, Hybrid intelligent systems, Boston: Kluwer Academic Publishers, 1995. |
| [43] |
M. Rahman, N. S. Chen, M. M. Islam, A. Dewand, H. R. Pourghasemie, R. M. A. Washakh, et al., Location-allocation modeling for emergency evacuation planning with GIS and remote sensing: a case study of Northeast Bangladesh, Geosci. Front., 12 (2021), 101095. https://doi.org/10.1016/j.gsf.2020.09.022 doi: 10.1016/j.gsf.2020.09.022
|
| [44] |
M. Y. Qi, R. W. Jiang, S. Q. Shen, Sequential competitive facility location: exact and approximate algorithms, Oper. Res., 2022. https://doi.org/10.1287/opre.2022.2339 doi: 10.1287/opre.2022.2339
|
| [45] | M. Rahbari, S. H. R. Hajiagha, H. A. Mahdiraji, F. R. Dorcheh, J. A. Garza-Reyes, A novel location-inventory-routing problem in a two-stage red meat supply chain with logistic decisions: evidence from an emerging economy, Int. J. Syst. Cybern., 4 (2022), 1498–1531. |
| [46] |
Y. J. Yang, Y. Q. Yin, D. J. Wang, J. Ignatius, T. C. E. Cheng, L. Dhamotharan, Distributionally robust multi-period location-allocation with multiple resources and capacity levels in humanitarian logistics, Eur. J. Oper. Res., 2022. https://doi.org/10.1016/j.ejor.2022.06.047 doi: 10.1016/j.ejor.2022.06.047
|
| [47] |
T. Q. Liu, F. Saldanha-da-Gama, S. M. Wang, Y. C. Mao, Robust stochastic facility location: sensitivity analysis and exact solution, INFORMS J. Comput., 34 (2022), 2776–2803. https://doi.org/10.1287/ijoc.2022.1206 doi: 10.1287/ijoc.2022.1206
|
| [48] |
K. S. Shehadeh, Distributionally robust optimization approaches for a stochastic mobile facility fleet sizing, routing, and scheduling problem, Transport. Sci., 2022. https://doi.org/10.1287/trsc.2022.1153 doi: 10.1287/trsc.2022.1153
|
| [49] |
H. Soleimani, P. Chhetri, A. M. Fathollahi-Fard, S. M. J. Mirzapour Al-e-Hashem, S. Shahparvari, Sustainable closed-loop supply chain with energy efficiency: lagrangian relaxation, reformulations, and heuristics, Ann. Oper. Res., 318 (2022), 531–556. https://doi.org/10.1007/s10479-022-04661-z doi: 10.1007/s10479-022-04661-z
|
| [50] |
S. Kim, S. Weber, Simulation methods for robust risk assessment and the distorted mix approach, Eur. J. Oper. Res., 298 (2022), 380–398. https://doi.org/10.1016/j.ejor.2021.07.005 doi: 10.1016/j.ejor.2021.07.005
|
| [51] |
P. Embrechts, A. Schied, R. D. Wang, Robustness in the optimization of risk measures, Oper. Res., 70 (2021), 95–110. https://doi.org/10.1287/opre.2021.2147 doi: 10.1287/opre.2021.2147
|
| [52] |
W. Liu, L. Yang, B. Yu, Distributionally robust optimization based on kernel density estimation and mean-Entropic value-at-risk, INFORMS J. Optim., 2022. https://doi.org/10.1287/ijoo.2022.0076 doi: 10.1287/ijoo.2022.0076
|
| [53] |
A. M. Fathollahi-Fard, M. A. Dulebenets, M. Hajiaghaei-Keshteli, R. Tavakkoli-Moghaddam, M. Safaeian, H. Mirzahosseinian, Two hybrid meta-heuristic algorithms for a dual-channel closed-loop supply chain network design problem in the tire industry under uncertainty, Adv. Eng. Inform., 50 (2021), 101418. https://doi.org/10.1016/j.aei.2021.101418 doi: 10.1016/j.aei.2021.101418
|
| [54] |
N. Noyan, Risk-Averse stochastic modeling and optimization, INFORMS TutORials Oper. Res., 2018,221–254. https://doi.org/10.1287/educ.2018.0183 doi: 10.1287/educ.2018.0183
|
| [55] |
P. Artzner, F. Delbaen, J. M. Eber, D. Heath, Coherent measures of risk, Math. Finance, 9 (1999), 203–228. https://doi.org/10.1111/1467-9965.00068 doi: 10.1111/1467-9965.00068
|
| [56] |
W. Ogryczak, A. Ruszczynski, Dual stochastic dominance and related mean-risk models, SIAM J. Optim., 13 (2002), 60–78. https://doi.org/10.1137/S1052623400375075 doi: 10.1137/S1052623400375075
|
| [57] | R. T. Rockafellar, S. Uryasev, Optimization of conditional value-at-risk, J. Risk, 2 (2000), 21–41. |
| [58] |
P. M. Esfahani, D. Kuhn, Data-driven distributionally robust optimization using the Wasserstein metric: performance guarantees and tractable reformulations, Math. Program., 171 (2018), 115–166. https://doi.org/10.1007/s10107-017-1172-1 doi: 10.1007/s10107-017-1172-1
|
| [59] |
M. Clerc, The swarm and queen: towards a deterministic and adaptive particle swarm optimization, Proceedings of the 1999 Congress on Evolutionary Computation-CEC99, 3 (1999), 1951–1957. https://doi.org/10.1109/CEC.1999.785513 doi: 10.1109/CEC.1999.785513
|
| [60] |
M. Clerc, J. Kennedy, The particle swarm-explosion, stability, and convergence in a multidimensional complex space, IEEE T. Evolut. Comput., 6 (2002), 58–73. https://doi.org/10.1109/4235.985692 doi: 10.1109/4235.985692
|
| [61] |
J. Kennedy, R. C. Eberhart, A discrete binary version of the particle swarm algorithm, 1997 IEEE International Conference on Systems, Man, and Cybernetics. Computational Cybernetics and Simulation, 5 (1997), 4104–4108. https://doi.org/10.1109/ICSMC.1997.637339 doi: 10.1109/ICSMC.1997.637339
|
| [62] | Z. Ji, H. L. Liao, Q. H. Wu, Particle swarm optimization algorithm and its application, Science Press, 2009. |
| [63] | S. Gao, K. Tang, X. Jiang, J. Yang, Convergence analysis of particle swarm optimization algorithm, Sci. Technol. Eng., 6 (2006), 1625–1627. |
| [64] | J. Nocedal, S. Wright, Numerical optimization, Springer, 2006. |
| [65] |
J. Moosavi, A. M. Fathollahi-Fard, M. A. Dulebenets, Supply chain disruption during the COVID-19 pandemic: recognizing potential disruption management strategies, Int. J. Disast. Risk Re., 75 (2022), 102983. https://doi.org/10.1016/j.ijdrr.2022.102983 doi: 10.1016/j.ijdrr.2022.102983
|
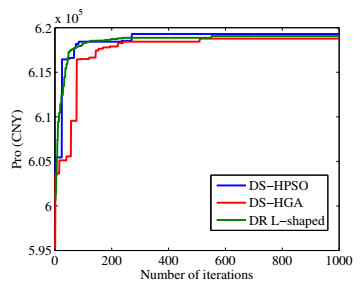
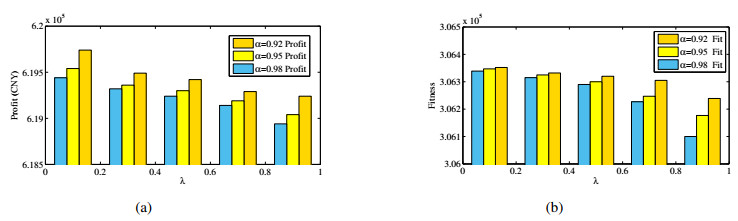
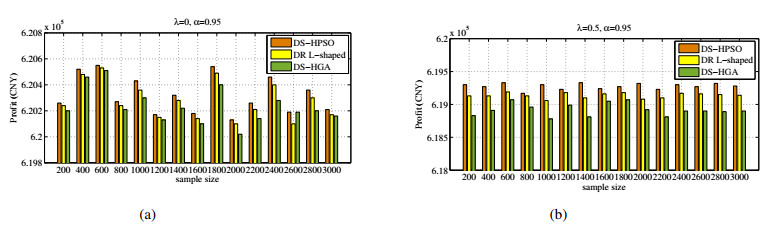
Figures(7) / Tables(11)

Zhimin Liu. Data-driven two-stage sparse distributionally robust risk optimization model for location allocation problems under uncertain environment[J]. AIMS Mathematics, 2023, 8(2): 2910-2939. doi: 10.3934/math.2023152







 DownLoad:
DownLoad: