Dynamic cumulative residual entropy is a recent measure of uncertainty which plays a substantial role in reliability and survival studies. This article comes up with Bayesian estimation of the dynamic cumulative residual entropy of Pareto Ⅱ distribution in case of non-informative and informative priors. The Bayesian estimator and the corresponding credible interval are obtained under squared error, linear exponential (LINEX) and precautionary loss functions. The Metropolis-Hastings algorithm is employed to generate Markov chain Monte Carlo samples from the posterior distribution. A simulation study is done to implement and compare the accuracy of considered estimates in terms of their relative absolute bias, estimated risk and the width of credible intervals. Regarding the outputs of simulation study, Bayesian estimate of dynamic cumulative residual entropy under LINEX loss function is preferable than the other estimates in most of situations. Further, the estimated risks of dynamic cumulative residual entropy decrease as the value of estimated entropy decreases. Eventually, inferential procedure developed in this paper is illustrated via a real data.
Citation: Abdullah Ali H. Ahmadini, Amal S. Hassan, Ahmed N. Zaky, Shokrya S. Alshqaq. Bayesian inference of dynamic cumulative residual entropy from Pareto Ⅱ distribution with application to COVID-19[J]. AIMS Mathematics, 2021, 6(3): 2196-2216. doi: 10.3934/math.2021133
Dynamic cumulative residual entropy is a recent measure of uncertainty which plays a substantial role in reliability and survival studies. This article comes up with Bayesian estimation of the dynamic cumulative residual entropy of Pareto Ⅱ distribution in case of non-informative and informative priors. The Bayesian estimator and the corresponding credible interval are obtained under squared error, linear exponential (LINEX) and precautionary loss functions. The Metropolis-Hastings algorithm is employed to generate Markov chain Monte Carlo samples from the posterior distribution. A simulation study is done to implement and compare the accuracy of considered estimates in terms of their relative absolute bias, estimated risk and the width of credible intervals. Regarding the outputs of simulation study, Bayesian estimate of dynamic cumulative residual entropy under LINEX loss function is preferable than the other estimates in most of situations. Further, the estimated risks of dynamic cumulative residual entropy decrease as the value of estimated entropy decreases. Eventually, inferential procedure developed in this paper is illustrated via a real data.

| [1] | C. E. Shannon, A mathematical theory of communication. Bell Syst. Tech. J., 27 (1948), 379–432. |
| [2] | A. Özçam, Entropy estimation and interpretation of the inter-sectoral linkages of Turkish economy based on Leontief input/output model, J. Econ. Stud., 36 (2009), 490–507. |
| [3] |
R. Gençay, N. Gradojevic, The tale of two financial crises: An entropic perspective, Entropy, 19 (2017), 244. doi: 10.3390/e19060244

|
| [4] |
S. Rashidi, S. Akar, M. Bovand, R. Ellahi, Volume of fluid model to simulate the nanofluid flow and entropy generation in a single slope solar still, Renew. Energ., 115 (2018), 400–410. doi: 10.1016/j.renene.2017.08.059
|
| [5] |
C. Zhang, F. Cong, T. Kujala, W. Liu, J. Liu, T. Parviainen, et al. Network entropy for the sequence analysis of functional connectivity graphs of the brain, Entropy, 20 (2018), 311. doi: 10.3390/e20050311
|
| [6] |
F. H. A. De Araujo, L. Bejan, O. A. Rosso, T. Stosic, Permutation entropy and statistical complexity analysis of Brazilian agricultural commodities, Entropy, 21 (2019), 1220. doi: 10.3390/e21121220
|
| [7] |
M. K. Shakhatreh, S. Dey, M. T. Alodat, Objective Bayesian analysis for the differential entropy of the Weibull distribution, Appl. Math. Model., 89 (2021), 314–332. doi: 10.1016/j.apm.2020.07.016
|
| [8] | I. Klein, M. Doll, (Generalized) Maximum cumulative direct, residual, and paired Φ entropy approach, Entropy, 22 (2020), 91. |
| [9] | J. I. Seo, H. J. Lee, S. B. Kan, Estimation for generalized half logistic distribution based on records, J. Korea Inf. Sci. Soc., 23 (2012), 1249–1257. |
| [10] | Y. Cho, H. Sun, K. Lee, Estimating the entropy of a Weibull distribution under generalized progressive hybrid censoring, Entropy, 17 (2015), 101–122. |
| [11] |
M. Chacko, P. S. Asha, Estimation of entropy for generalized exponential distribution based on record values. J. Indian Soc. Probab. Stat., 19 (2018), 79–96. doi: 10.1007/s41096-018-0033-4
|
| [12] |
A. S. Hassan, A. N. Zaky, Estimation of entropy for inverse Weibull distribution under multiple censored data. J. Taibah Univ. Sci., 13 (2019), 331–337. doi: 10.1080/16583655.2019.1576493
|
| [13] | A. S. Hassan, A. N. Zaky, Entropy Bayesian estimation for Lomax distribution based on record. Thail. Stat., (in press). |
| [14] | N. Ebrahimi, How to measure uncertainty in the residual lifetime distribution. Sankhya A., 58 (1996), 48–56. |
| [15] | M. Rao, Y. Chen, B. C. Vemuri, F. Wang, Cumulative residual entropy: a new measure of information. IEEE. Trans. Inf. Theory., 50 (2004), 1220–1228. |
| [16] |
M. Asadi, Y. Zohrevand, On the dynamic cumulative residual entropy. J. Stat. Plan. Infer., 137 (2007), 1931–1941. doi: 10.1016/j.jspi.2006.06.035
|
| [17] |
K. R. Renjini, E. I. Abdul-Sathar, G. Rajesh, Bayes estimation of dynamic cumulative residual entropy for Pareto distribution under Type-Ⅱ right censored data. Appl. Math. Model., 40 (2016), 8424–8434. doi: 10.1016/j.apm.2016.04.017
|
| [18] |
K. R. Renjini, E. I. Abdul-Sathar, G. Rajesh, A study of the effect of loss functions on the Bayes estimates of dynamic cumulative residual entropy for Pareto distribution under upper record values. J. Stat. Comput. Sim., 86 (2016), 324–339. doi: 10.1080/00949655.2015.1007986
|
| [19] | K. Lee, Estimation of entropy of the inverse Weibull distribution under generalized progressive hybrid censored data. J. Korea Inf. Sci. Soc., 28 (2017), 659–668. |
| [20] | K. R. Renjini, E. I. Abdul-Sathar, G. Rajesh, Bayesian estimation of dynamic cumulative residual entropy for classical Pareto distribution. AM. J. MATH-S., 37 (2018), 1–13. |
| [21] |
K. S. Lomax, Business failures. Another example of the analysis of failure data. J. Am. Stat. Assoc., 49 (1954), 847–852. doi: 10.1080/01621459.1954.10501239
|
| [22] | A. B. Atkinson, A. J. Harrison, Distribution of Personal Wealth in Britain. Cambridge: Cambridge Univ. Press: New York, NY, USA, 1978. |
| [23] | C. M. Harris, The Pareto distribution as a queue service discipline. Oper. Res., 16 (1968), 307–313. |
| [24] | A. S. Hassan, A. Al-Ghamdi, Optimum step stress accelerated life testing for Lomax distribution. J. Appl. Sci. Res., 5 (2009), 2153–2164. |
| [25] | A. S. Hassan, S. M. Assar, A. Shelbaia, Optimum step-stress accelerated life test plan for Lomax distribution with an adaptive type-Ⅱ progressive hybrid censoring. J. Adv. Math. Comp. Sci., 13 (2016), 1–19. |
| [26] |
A. S. Hassan, R. E. Mohamed, Parameter estimation for inverted exponentiated Lomax distribution with right censored data. Gazi Univ. J. Sci., 32 (2019), 1370–1386. doi: 10.35378/gujs.452885
|
| [27] | A. S. Hassan, M. Elgarhy, R. E. Mohamed, Statistical properties and estimation of type Ⅱ half logistic Lomax distribution. Thail. Stat., 18 (2020), 290–305. |
| [28] |
A. S. Hassan, M. A. Sabry, A. M. Elsehetry, Truncated power Lomax distribution with application to flood data. J. Stat. Appl. Prob., 9 (2020), 347–359. doi: 10.18576/jsap/090214
|
| [29] | R. Bantan, A. S. Hassan, M. Elsehetry, Zubair Lomax distribution: properties and estimation based on ranked set sampling. CMC-Comput. Mater. Con., 65 (2020), 2169–2187. |
| [30] | A. S. Hassan, M. A. Sabry, A. M. Elsehetry, A new family of upper-truncated distributions: properties and estimation. Thail. Stat., 18 (2020), 196–214. |
| [31] | M. H. Chen, Q. M. Shao, Monte Carlo estimation of Bayesian credible and HPD Intervals. J. Comput. Graph. Stat., 8 (1999), 69–92. |
| [32] |
A. Pak, M. R. Mahmoudi, Estimating the parameters of Lomax distribution from imprecise information. J. Stat. Theory Appl., 17 (2018), 122–135. doi: 10.2991/jsta.2018.17.1.9
|
| [33] | M. M. Z. Abd El-Monsef, N. H. Sweilam, M. A. Sabry, The exponentiated power Lomax distribution and its applications. Qual. Reliab. Engng. Int., (2020), 1–24. |
| [34] |
J. Simpson, Use of the gamma distribution in single-cloud rainfall analysis, Mon. Weather Rev., 100 (1972), 309–312. doi: 10.1175/1520-0493(1972)100<0309:UOTGDI>2.3.CO;2
|
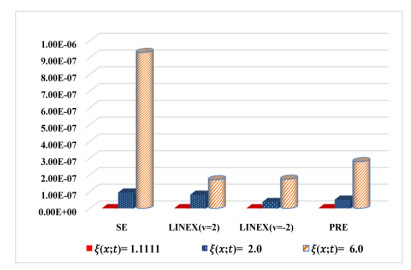
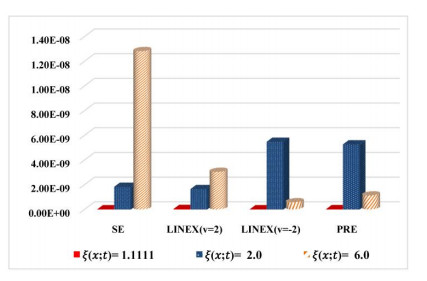
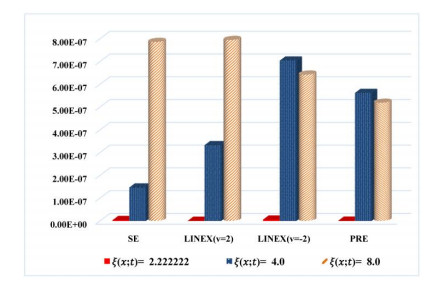
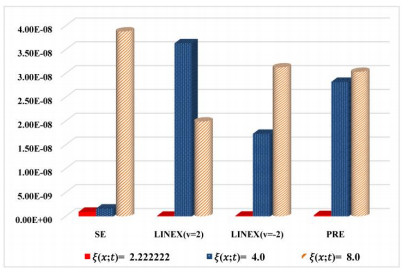
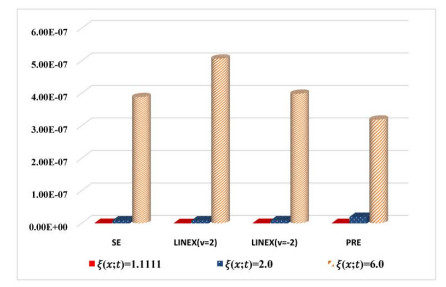
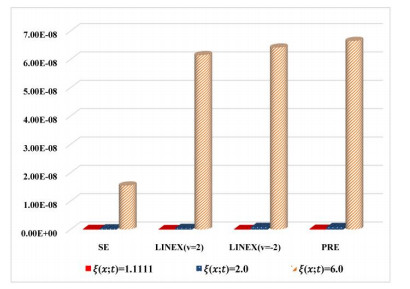
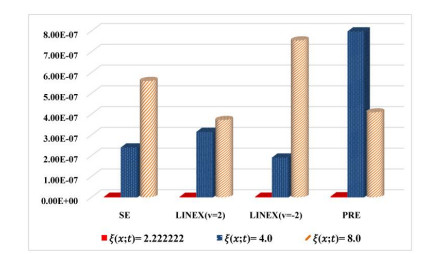
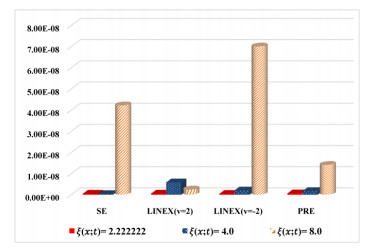
Figures(8) / Tables(14)

Abdullah Ali H. Ahmadini, Amal S. Hassan, Ahmed N. Zaky, Shokrya S. Alshqaq. Bayesian inference of dynamic cumulative residual entropy from Pareto Ⅱ distribution with application to COVID-19[J]. AIMS Mathematics, 2021, 6(3): 2196-2216. doi: 10.3934/math.2021133







 DownLoad:
DownLoad: