Citation: Sakander Hayat, Hafiz Muhammad Afzal Siddiqui, Muhammad Imran, Hafiz Muhammad Ikhlaq, Jinde Cao. On the zero forcing number and propagation time of oriented graphs[J]. AIMS Mathematics, 2021, 6(2): 1833-1850. doi: 10.3934/math.2021111

| [1] | A. Aazami, Hardness results and approximation algorithms for some problems on graphs, Thesis (Ph.D.), University of Waterloo, 2008. |
| [2] | F. Barioli, W. Barrett, S. Butler, S. M. Cioabă, D. Cvetković, S. M. Fallat, et al., Zero forcing sets and the minimum rank of graphs, Linear Algebra Appl., 428 (2007), 1628-1648. |
| [3] | F. Barioli, W. Barrett, S. Fallat, H. T. Hall, L. Hogben, B. Shader, et al., Parameters related to tree-width, zero forcing, and maximum nullity of a graph, J. Graph Theory, 72 (2013), 146177. |
| [4] | F. Barioli, S. M. Fallat, H. T. Hall, D. Hershkowitz, L. Hogben, H. van der Holst, et al., On the minimum rank of not necessarily symmetric matrices: a preliminary study, Electron. J. Linear Algebra, 18 (2009), 126-145. |
| [5] | K. F. Benson, D. Ferrero, M. Flagg, V. Furst, L. Hogben, V. Vasilevska, et al., Power domination and zero forcing, arXiv preprint arXiv: 1510.02421, 2015. |
| [6] |
A. Berliner, C. Bozeman, S. Butler, M. Catral, L. Hogben, B. Kroschel, et al., Zero forcing propagation time on oriented graphs, Discrete Appl. Math., 224 (2017), 45-59. doi: 10.1016/j.dam.2017.02.017

|
| [7] |
A. Berliner, C. Brown, J. Carlson, N. Cox, L. Hogben, J. Hu, et al., Path cover number, maximum nullity, and zero forcing number of oriented graphs and other simple digraphs, Involve, 8 (2015), 147-167. doi: 10.2140/involve.2015.8.147
|
| [8] | A. Berliner, M. Catral, L. Hogben, M. Huynh, K. Lied, M. Young. Mini- mum rank, maximum nullity and zero forcing number of simple digraphs, Electron. J. Linear Algebra, 26 (2013), 762- 780. |
| [9] | D. Burgarth, D. D'Alessandro, L. Hogben, S. Severini, M. Young, Zero forcing, linear and quantum controllability for systems evolving on networks, IEEE Trans. Autom. Control, 58 (2013), 2349- 2354. |
| [10] |
D. Burgarth, V. Giovannetti, Full control by locally induced relaxation, Phys. Rev. Lett., 99 (2007), 100501. doi: 10.1103/PhysRevLett.99.100501
|
| [11] | K. B. Chilakamarri, N. Dean, C. X. Kang, E. Yi, Iteration index of a zero forcing set in a graph, Bull. Inst. Combin. Appl., 64 (2012), 57-72. |
| [12] | S. Fallat, L. Hogben, Minimum Rank, maximum nullity, and zero forcing number of graphs. In: Handbook of Linear Algebra, 2nd edition, L. Hogben editor, CRC Press, Boca Raton, 2014. |
| [13] |
S. Fallat, K. Meagher, B. Yang, On the complexity of the positive semidefinite zero forcing number, Linear Algebra Appl., 491 (2016), 101-122. doi: 10.1016/j.laa.2015.03.011
|
| [14] | L. Hogben, Minimum rank problems, Linear Algebra Appl., 432 (2010), 1961-1974. |
| [15] |
L. Hogben, M. Huynh, N. Kingsley, S. Meyer, S. Walker, M. Young, Propagation time for zero forcing on a graph, Discrete Appl. Math., 160 (2012), 1994-2005. doi: 10.1016/j.dam.2012.04.003
|
| [16] |
I. J. Kim, B. P. Barthel, Y. Park, J. R. Tait, J. L. Dobmeier, S. Kim, D. Shin, Network analysis for active and passive propagation models, Networks, 63 (2014), 160-169. doi: 10.1002/net.21532
|
| [17] | M. Perila, K. Rutschke, B. Kroschel, Zero forcing and propagation time of oriented graphs, Submitted. |
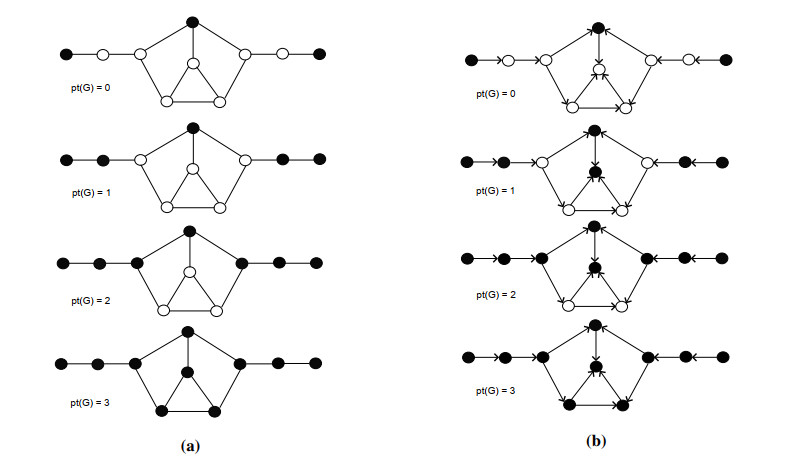
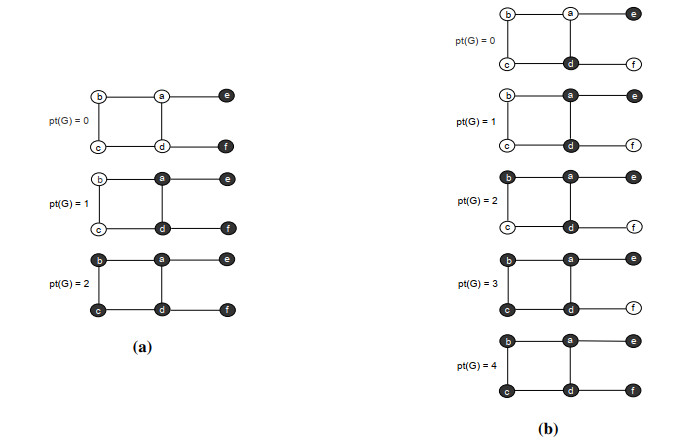
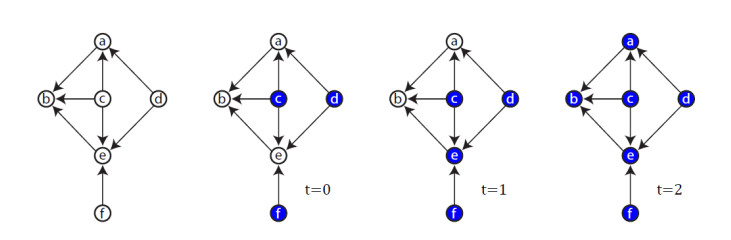

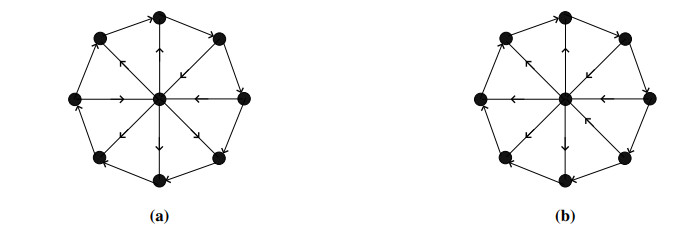
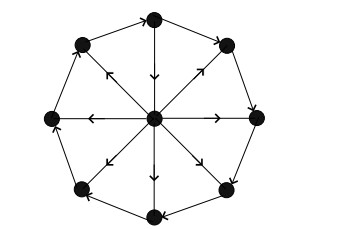
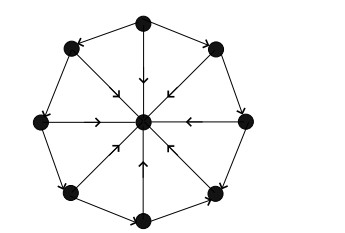
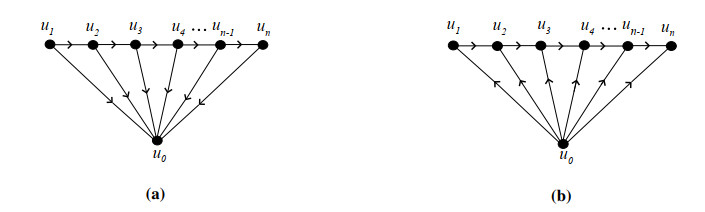
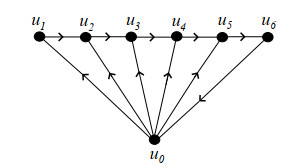


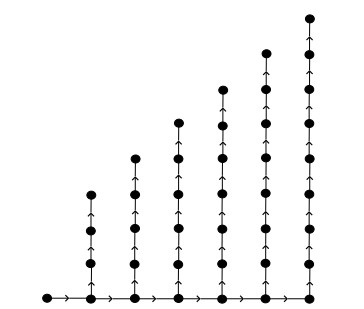
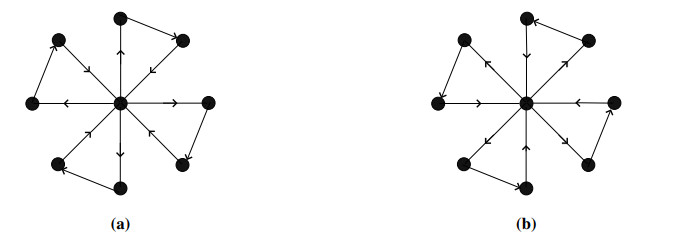
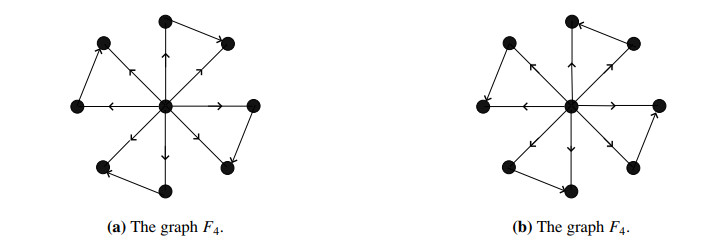
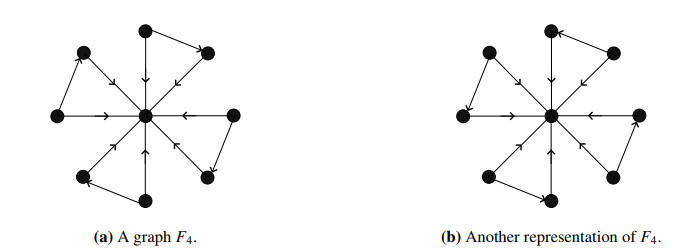
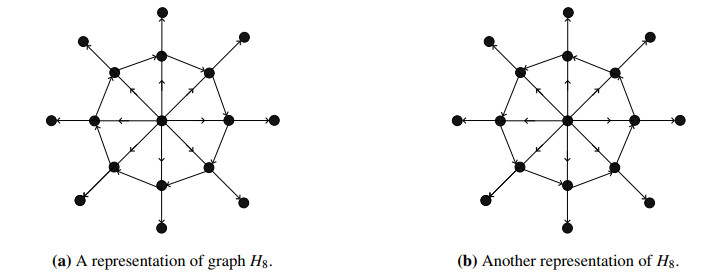
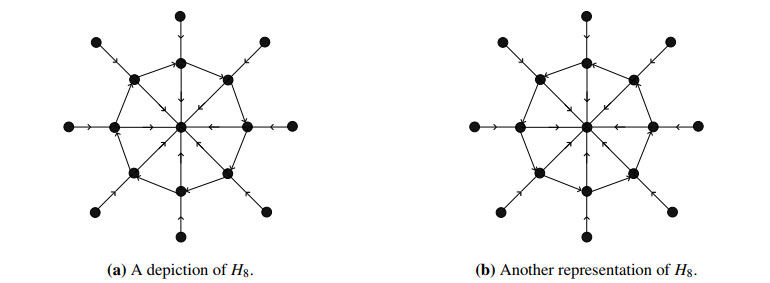
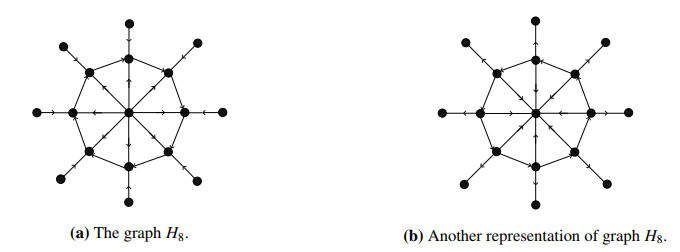
Figures(22)

Sakander Hayat, Hafiz Muhammad Afzal Siddiqui, Muhammad Imran, Hafiz Muhammad Ikhlaq, Jinde Cao. On the zero forcing number and propagation time of oriented graphs[J]. AIMS Mathematics, 2021, 6(2): 1833-1850. doi: 10.3934/math.2021111







 DownLoad:
DownLoad: