Citation: Kieran Greer. New ideas for brain modelling 5[J]. AIMS Biophysics, 2021, 8(1): 41-56. doi: 10.3934/biophy.2021003

| [1] | Greer K (2020) New ideas for brain modelling 6. AIMS Biophysics 7: 308-322. |
| [2] | Greer K (2019) New ideas for brain modelling 3. Cogn Syst Res 55: 1-13. |
| [3] | Greer K (2017) New ideas for brain modelling 4. BRAIN. Broad Research in Artificial Intelligence and Neuroscience 9: 155-167. |
| [4] | Greer K (2016) A repeated signal difference for recognising patterns. BRAIN. Broad Research in Artificial Intelligence and Neuroscience 7: 139-147. |
| [5] | Greer K (2014) Concept trees: Building dynamic concepts from semi-structured data using nature-inspired methods. Complex System Modelling and Control through Intelligent Soft Computations, Studies in Fuzziness and Soft Computing Germany: 221-252. |
| [6] | Greer K (2013) Turing: then, now and still key. Artificial Intelligence, Evolutionary Computing and Metaheuristics Berlin: 43-62. |
| [7] | Greer K (2011) Symbolic neural networks for clustering higher-level concepts. NAUN Int J Comput 5: 378-386. |
| [8] | Anderson JA, Silverstein JW, Ritz SA, et al. (1977) Distinctive features, categorical perception, and probability learning: Some applications of a neural model. Psychol Rev 84: 413. |
| [9] | Hawkins J, Blakeslee S (2004) Times books. On Intelligence . |
| [10] | Hinton GE, Osindero S, Teh YW (2006) A fast learning algorithm for deep belief nets. Neural Comput 18: 1527-1554. |
| [11] | Curbera F, Goland Y, Klein J, et al. Business process execution language for web services BPEL (2002) .Available from: https://www.oasis-open.org/committees/download.php/2046/BPEL V1-1 May 5 2003 Final.pdf. |
| [12] | Thiagarajan RK, Srivastava AK, Pujari AK, et al. (2002) BPML: A process modeling language for dynamic business models. Proceedings Fourth IEEE International Workshop on Advanced Issues of E-Commerce and Web-Based Information Systems (WECWIS 2002) IEEE, 222-224. |
| [13] | Rockstrom A, Saracco R (1982) SDL-CCITT specification and description language. IEEE T Commun 30: 1310-1318. |
| [14] | FIPA The foundation for intelligent physical agents Available from: http://www.fipa.org/. |
| [15] | Bellman R (1957) A Markovian decision process. J Math Mech 6: 679-684. |
| [16] | Guigon E, Grandguillaume P, Otto I, et al. (1994) Neural network models of cortical functions based on the computational properties of the cerebral cortex. J Physiol-Paris 88: 291-308. |
| [17] | Dehaene S, Changeux JP, Nadal JP (1987) Neural networks that learn temporal sequences by selection. P Natl Acad Sci 84: 2727-2731. |
| [18] | Hawkins J, Ahmad S (2016) Why neurons have thousands of synapses, a theory of sequence memory in neocortex. Front in Neural Circuit 10: 23. |
| [19] | Yuste R (2011) Dendritic spines and distributed circuits. Neuron 71: 772-781. |
| [20] | Kandel ER (2001) The molecular biology of memory storage: a dialogue between genes and synapses. Science 294: 1030-1038. |
| [21] | Deco G, Jirsa VK, Robinson PA, et al. (2008) The dynamic brain: from spiking neurons to neural masses and cortical fields. PLoS Comput Biol 4: e1000092. |
| [22] | Mastrandrea R, Gabrielli A, Piras F, et al. (2017) Organization and hierarchy of the human functional brain network lead to a chain-like core. Sci Rep 7: 1-13. |
| [23] | Meunier D, Lambiotte R, Bullmore ET (2010) Modular and hierarchically modular organization of brain networks. Front Neurosci 4: 200. |
| [24] | Watts DJ, Strogatz SH (1998) Collective dynamics of ‘small-world’ networks. Nature 393: 440-442. |
| [25] | Rubinov M, Sporns O, van Leeuwen C, et al. (2009) Symbiotic relationship between brain structure and dynamics. BMC Neurosci 10: 1-18. |
| [26] | Gong P, van Leeuwen C (2004) Evolution to a small-world network with chaotic units. EPL (Europhysics Letters) 67: 328. |
| [27] | IBM (2003) An architectural blueprint for autonomic computing. IBM and Autonomic Computing . |
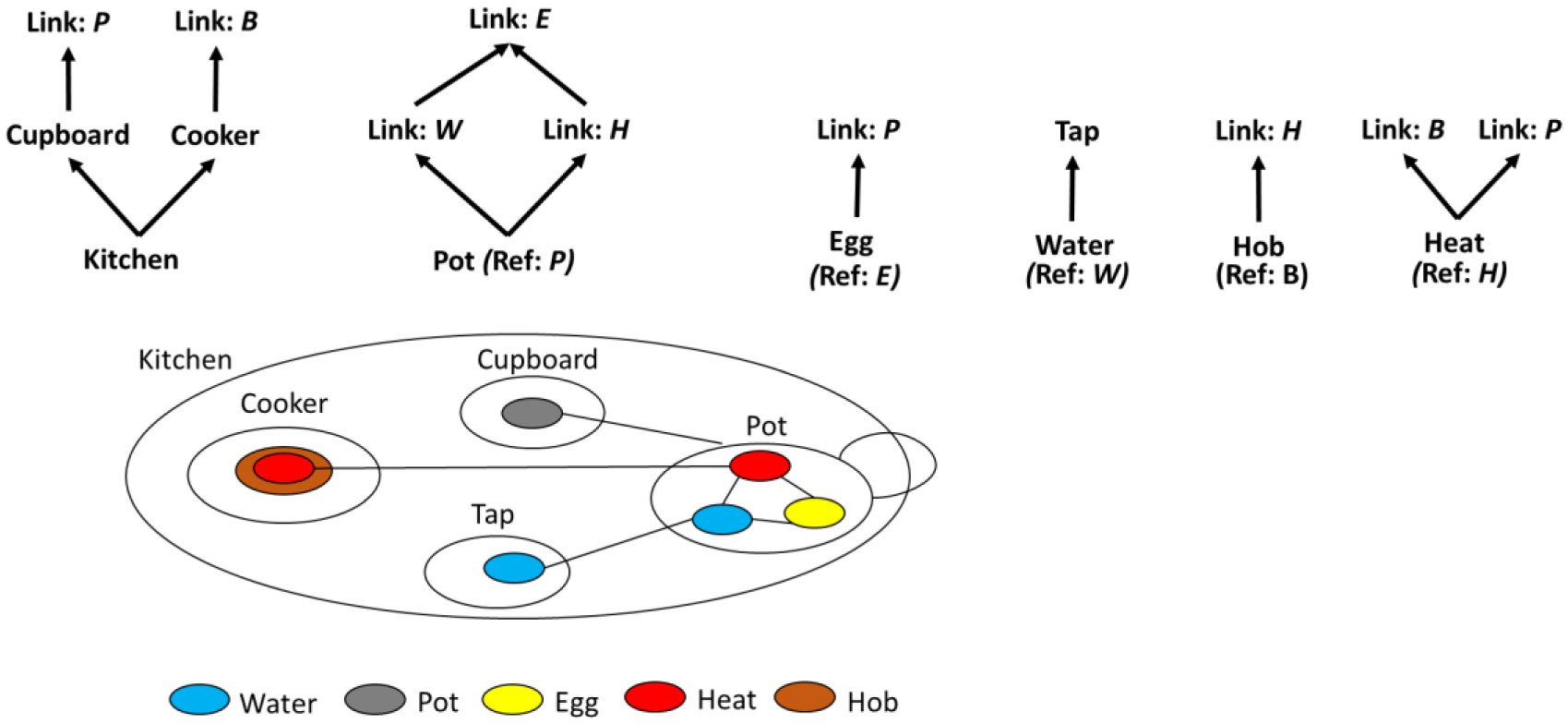
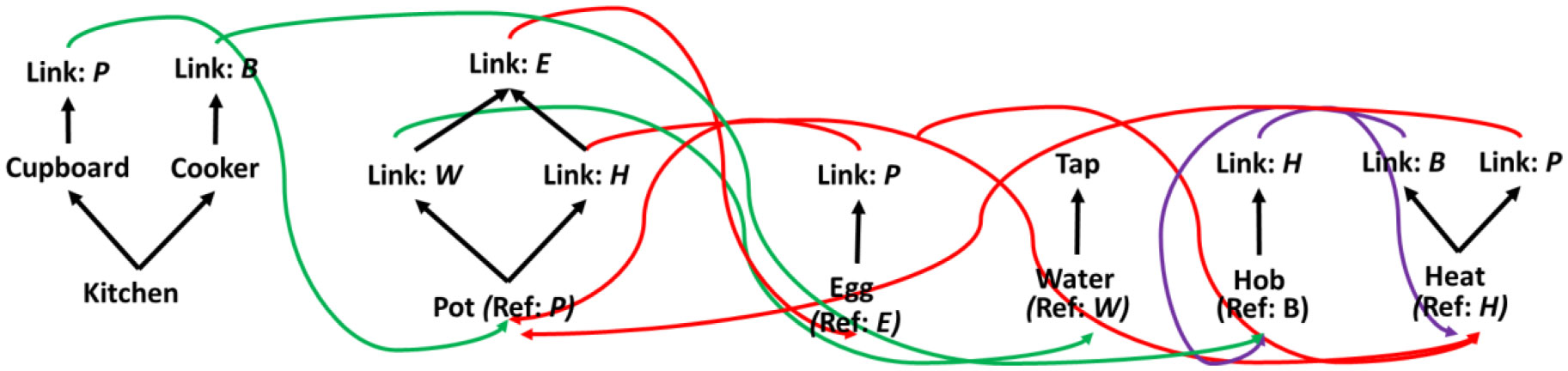
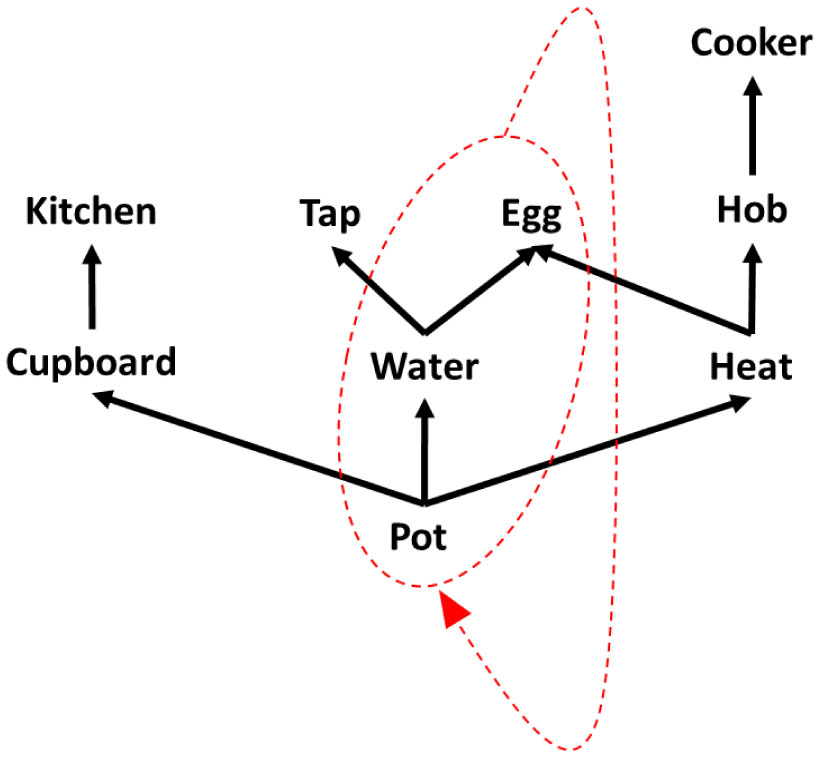
Figures(3) / Tables(1)

Kieran Greer. New ideas for brain modelling 5[J]. AIMS Biophysics, 2021, 8(1): 41-56. doi: 10.3934/biophy.2021003







 DownLoad:
DownLoad: