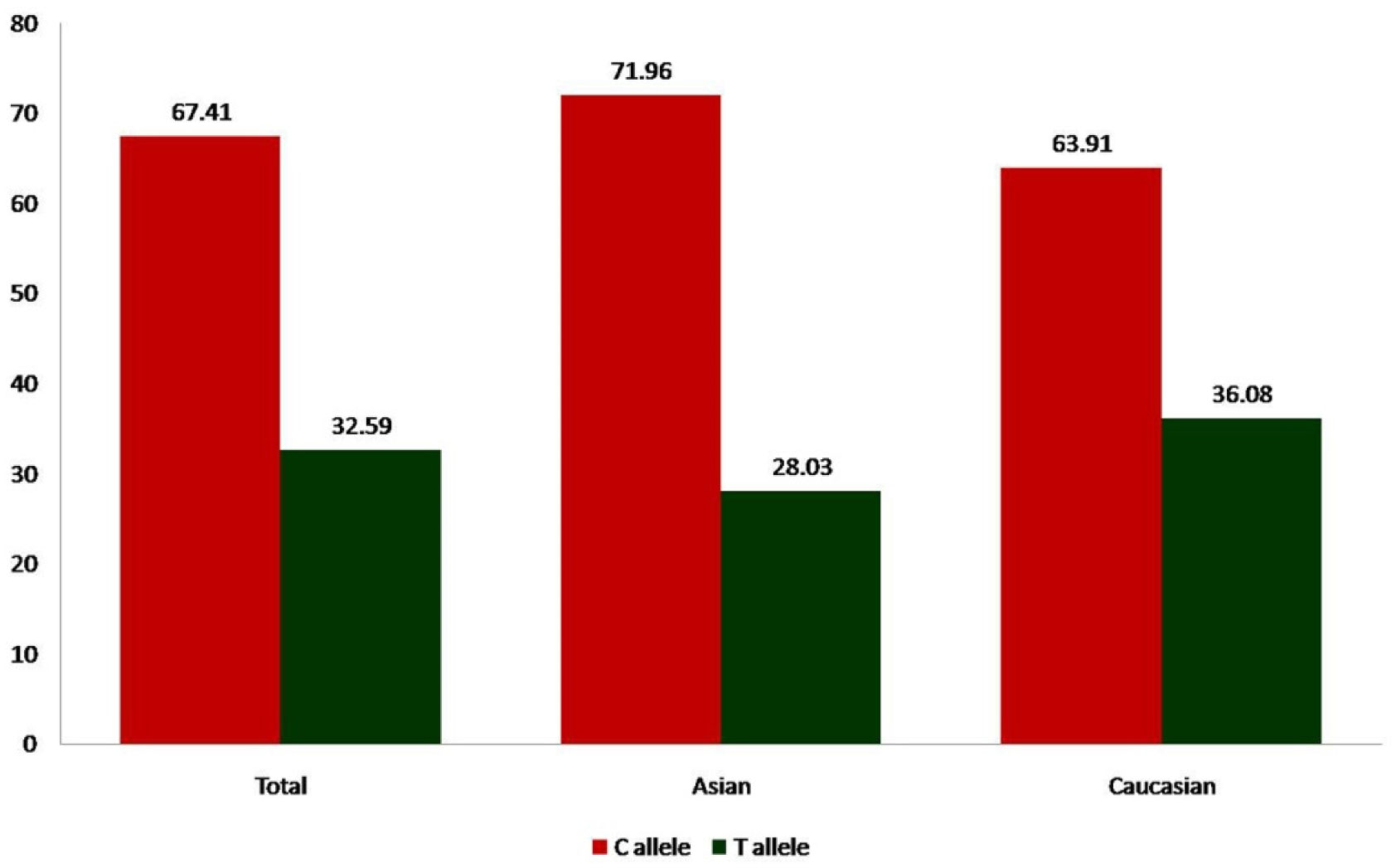
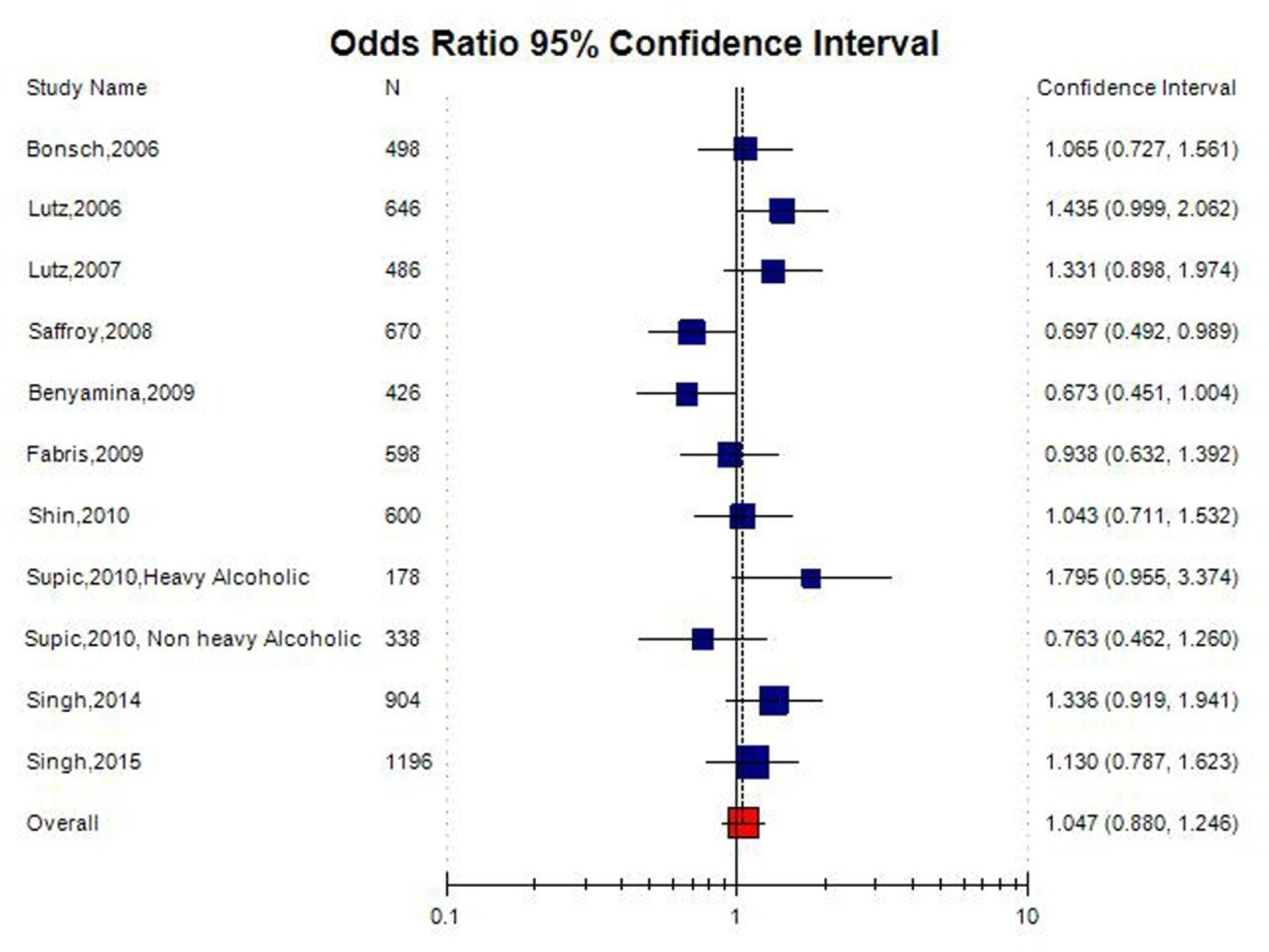
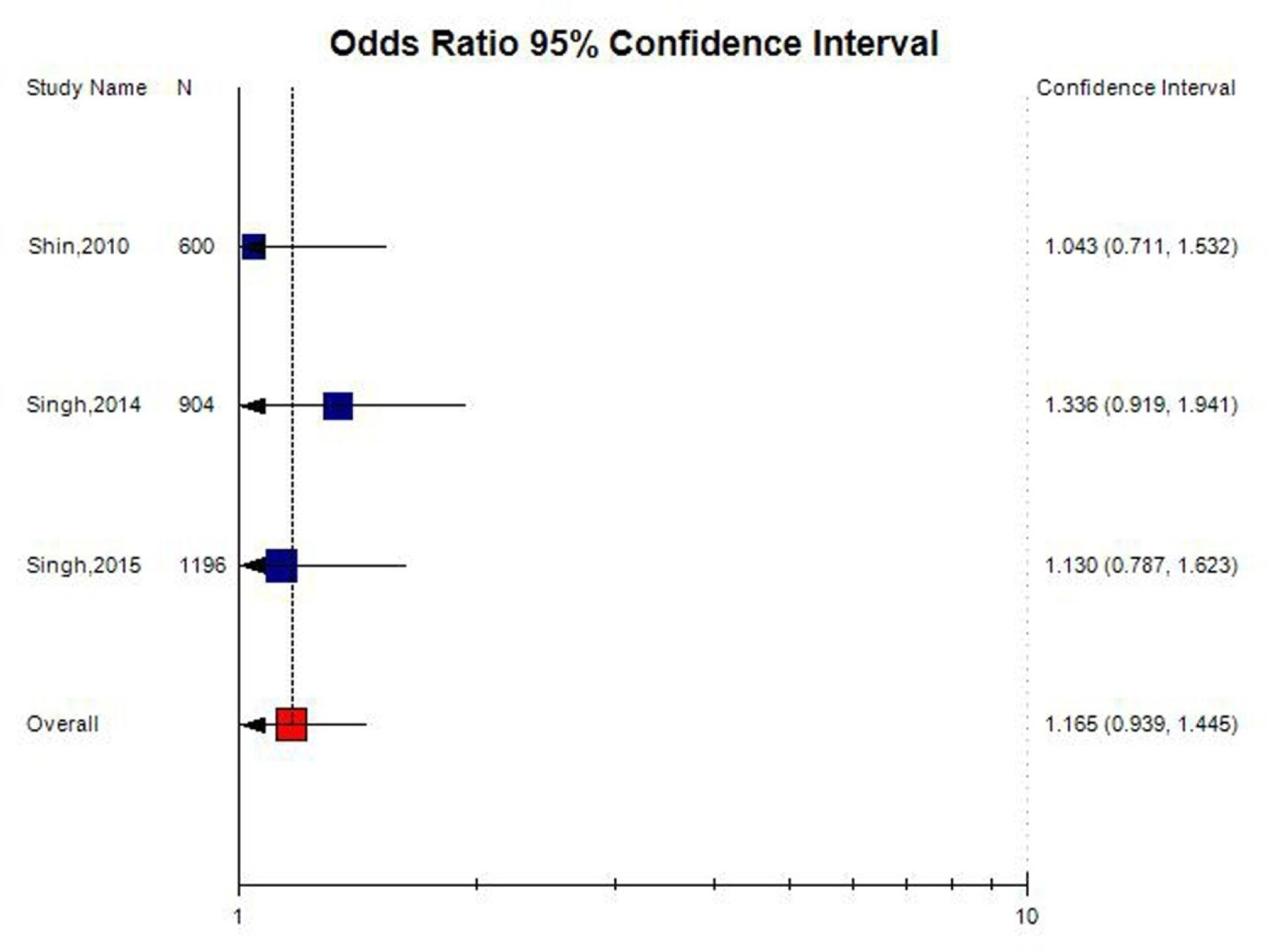
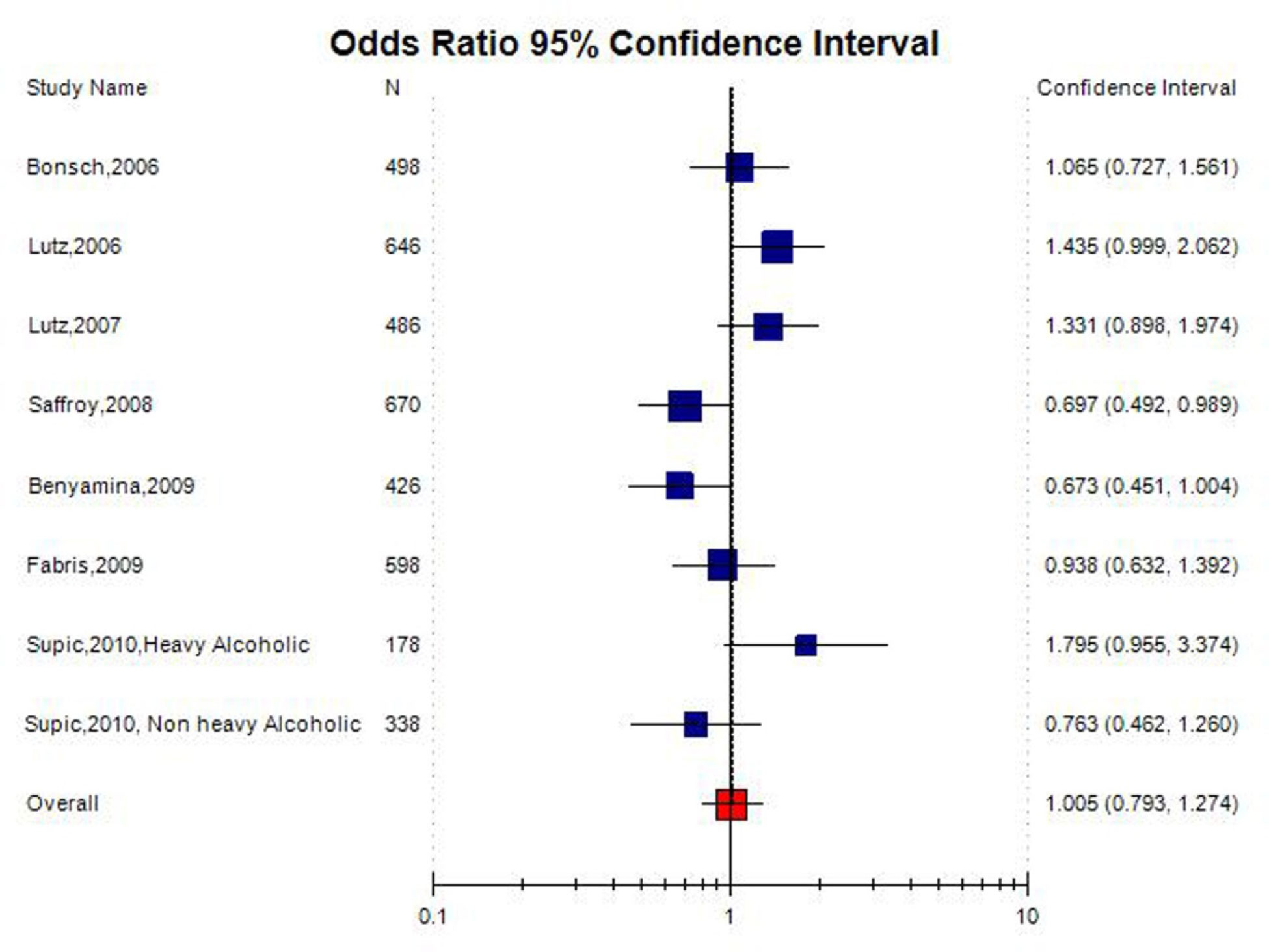
Alcohol dependence is a complex neuropsychiatric disorder. Numerous studies investigated association between MTHFR gene C677T (rs1801133) polymorphism and alcohol dependence (AD), but the results of this association remain conflicting. Accordingly, authors conducted a meta-analysis to further investigate such an association. PubMed, Elsevier Science Direct and Springer Link databases were searched for studies on the association between the MTHFRC677T polymorphism and AD. Pooled odds ratio (OR) with 95% confidence interval (CI) was calculated using the fixed- or random-effects model. Statistical analysis was performed with the software program MetaAnayst and MIX.A total of 11 articles were identified through a search of electronic databases, up to February 28, 2020. The results of the present meta-analysis did not show any association between MTHFR C677T polymorphisms and AD risk (for T vs. C: OR = 1.04, 95% CI = 0.88–1.24; CT vs. CC: OR = 1.02, 95% CI = 0.62–1.68; for TT+CT vs. CC: OR = 1.10, 95% CI = 0.94–1.29; for TT vs. CC: OR = 1.01, 95% CI = 0.66–1.51; for TT vs. CT+CC: OR = 0.97, 95% CI = 0.66–1.40). Results of subgroup analysis showed no significant association between MTHFR C677T polymorphism with AD in Asian as well as in Caucasian population. In conclusion, C677T polymorphism is not a risk factor for alcohol dependence.
Citation: Vandana Rai, Pradeep Kumar. Methylenetetrahydrofolate reductase (MTHFR) gene C677T (rs1801133) polymorphism and risk of alcohol dependence: a meta-analysis[J]. AIMS Neuroscience, 2021, 8(2): 212-225. doi: 10.3934/Neuroscience.2021011
Alcohol dependence is a complex neuropsychiatric disorder. Numerous studies investigated association between MTHFR gene C677T (rs1801133) polymorphism and alcohol dependence (AD), but the results of this association remain conflicting. Accordingly, authors conducted a meta-analysis to further investigate such an association. PubMed, Elsevier Science Direct and Springer Link databases were searched for studies on the association between the MTHFRC677T polymorphism and AD. Pooled odds ratio (OR) with 95% confidence interval (CI) was calculated using the fixed- or random-effects model. Statistical analysis was performed with the software program MetaAnayst and MIX.A total of 11 articles were identified through a search of electronic databases, up to February 28, 2020. The results of the present meta-analysis did not show any association between MTHFR C677T polymorphisms and AD risk (for T vs. C: OR = 1.04, 95% CI = 0.88–1.24; CT vs. CC: OR = 1.02, 95% CI = 0.62–1.68; for TT+CT vs. CC: OR = 1.10, 95% CI = 0.94–1.29; for TT vs. CC: OR = 1.01, 95% CI = 0.66–1.51; for TT vs. CT+CC: OR = 0.97, 95% CI = 0.66–1.40). Results of subgroup analysis showed no significant association between MTHFR C677T polymorphism with AD in Asian as well as in Caucasian population. In conclusion, C677T polymorphism is not a risk factor for alcohol dependence.

| [1] |
Koob GF (2003) Alcoholism: allostasis and beyond. Alcohol Clin Exp Res 27: 232-243. doi: 10.1097/01.ALC.0000057122.36127.C2

|
| [2] |
Volkow ND, Fowler JS, Wang GJ, et al. (2009) Imaging dopamine's role in drug abuse and addiction. Neuropharmacology 56: 3-8. doi: 10.1016/j.neuropharm.2008.05.022
|
| [3] | (2011) WHOGlobal Status Report on Alcohol and Health. Geneva, Switzerland: WHO. Available from: https://www.who.int/substance_abuse/publications/global_alcohol_report/msbgsruprofiles.pdf |
| [4] |
Comings DE, Blum K (2000) Reward deficiency syndrome: genetic aspects of behavioral disorders. Prog Brain Res 126: 325-341. doi: 10.1016/S0079-6123(00)26022-6
|
| [5] |
Parry CD, Patra J, Rehm J (2011) Alcohol consumption and non-communicable diseases: epidemiology and policy implications. Addiction 106: 1718-1724. doi: 10.1111/j.1360-0443.2011.03605.x
|
| [6] |
Prescott CA, Kendler KS (1999) Genetic and environmental contributions to alcohol abuse and dependence in a population-based sample of male twins. Am J Psychiatry 156: 34-40. doi: 10.1176/ajp.156.1.34
|
| [7] |
Kendler KS, Myers J, Prescott CA (2007) Specificity of genetic and environmental risk factors for symptoms of cannabis, cocaine, alcohol, caffeine, and nicotine dependence. Arch Gen Psychiatry 64: 1313-1320. doi: 10.1001/archpsyc.64.11.1313
|
| [8] |
Begleiter H, Reich T, Nurnberger J, et al. (1999) Description of the genetic analysis workshop 11 collaborative study on the genetics of alcoholism. Genet Epidemiol 17: S25-30. doi: 10.1002/gepi.1370170705
|
| [9] |
Goldman D, Oroszi G, Ducci F (2005) The genetics of addictions: uncovering the genes. Nat Rev Genet 6: 521-532. doi: 10.1038/nrg1635
|
| [10] |
Heath AC, Bucholz KK, Madden PA, et al. (1997) Genetic and environmental contributions to alcohol dependence risk in a national twin sample: consistency of findings in women and men. Psychol Med 27: 1381-1396. doi: 10.1017/S0033291797005643
|
| [11] |
Bleich S, Carl M, Bayerlein K, et al. (2005) Evidence of increased homocysteine levels in alcoholism: the Franconian alcoholism research studies (FARS). Alcohol Clin Exp Res 29: 334-336. doi: 10.1097/01.ALC.0000156083.91214.59
|
| [12] |
Ganji V, Kafai MR (2003) Demographic, health, lifestyle, and blood vitamin determinants of serum total homocysteine concentrations in the third National Health and Nutrition Examination Survey, 1988–1994. Am J Clin Nutr 77: 826-833. doi: 10.1093/ajcn/77.4.826
|
| [13] |
Seshadri S, Beiser A, Selhub J, et al. (2002) Plasma homocysteine as a risk factor for dementia and Alzheimer's disease. N Eng J Med 346: 476-483. doi: 10.1056/NEJMoa011613
|
| [14] |
Gudnason V, Stansbie D, Scott J, et al. (1998) C677T (thermolabile alanine/valine) polymorphism in methylenetetrahydrofolate reductase (MTHFR): its frequency and impact on plasma homocysteine concentration in different European populations. Atherosclerosis 136: 347-354. doi: 10.1016/S0021-9150(97)00237-2
|
| [15] |
Frosst P, Blom HJ, Milos R, et al. (1995) A candidate genetic risk factor for vascular disease: a common mutation in methylenetetrahydrofolate reductase. Nat Genet 10: 111-113. doi: 10.1038/ng0595-111
|
| [16] |
Goyette P, Pai A, Milos R, et al. (1998) Gene structure of human and mouse methylenetetrahydrofolate reductase (MTHFR). Mamm Genome 9: 652-656. doi: 10.1007/s003359900838
|
| [17] |
Rozen R (1997) Genetic predisposition to hyperhomocysteinemia: deficiency of methylenetetrahydrofolate reductase (MTHFR). Thromb Haemost 78: 523-526. doi: 10.1055/s-0038-1657581
|
| [18] |
Chango A, Boisson F, Barbe F, et al. (2000) The effect of 677C→T and 1298A→C mutations on plasma homocysteine and 5,10-methylenetetrahydrofolate reductase activity in healthy subjects. Br J Nutr 83: 593-596. doi: 10.1017/S0007114500000751
|
| [19] |
Rady PL, Szucs S, Grady J, et al. (2002) Genetic polymorphisms of methylenetetrahydrofolate reductase (MTHFR) and methionine synthase reductase (MTRR) in ethnic populations in Texas; a report of a novel MTHFR polymorphic site, G1793A. Am J Med Genet 107: 162-168. doi: 10.1002/ajmg.10122
|
| [20] |
Wilcken B, Bamforth F, Li Z, et al. (2003) Geographical and ethnic variation of the 677C>T allele of 5,10 methylenetetrahydrofolate reductase (MTHFR): findings from over 7000 newborns from 16 areas world-wide. J Med Genet 40: 619-625. doi: 10.1136/jmg.40.8.619
|
| [21] |
Rai V, Yadav U, Kumar P, et al. (2010) Methylenetetrahydrofolate reductase polymorphism (C677T) in muslim population of Eastern Uttar Pradesh, India. Indian J Med Sci 64: 219-223. doi: 10.4103/0019-5359.98949
|
| [22] |
Rai V, Yadav U, Kumar P (2012) Prevalence of methylenetetrahydrofolate reductase C677T polymorphism in Eastern Uttar Pradesh. Indian J Hum Genet 18: 43-46. doi: 10.4103/0971-6866.96645
|
| [23] |
Yadav U, Kumar P, Gupta S, et al. (2018) Distribution of MTHFR C677T gene polymorphism in healthy north indian population and an updated Meta-analysis. Ind J Clin Biochem 32: 399-410. doi: 10.1007/s12291-016-0619-0
|
| [24] |
Lutz UC, Batra A, Kolb W, et al. (2006) Methylenetetrahydrofolate reductase C677T-polymorphism and its association with alcohol withdrawal seizure. Alcohol Clin Exp Res 30: 1966-1971. doi: 10.1111/j.1530-0277.2006.00242.x
|
| [25] |
Saffroy R, Benyamina A, Pham P, et al. (2008) Protective effect against alcohol dependence of the thermolabile variant of MTHFR. Drug Alcohol Depend 96: 30-36. doi: 10.1016/j.drugalcdep.2008.01.016
|
| [26] |
Benyamina A, Saffroy R, Blecha L, et al. (2009) Association between MTHFR 677C-T polymorphism and alcohol dependence according to Lesch and Babor typology. Addict Biol 14: 503-505. doi: 10.1111/j.1369-1600.2009.00169.x
|
| [27] |
Rai V, Yadav U, Kumar P, et al. (2014) Maternal methylenetetrahydrofolate reductase C677T polymorphism and down syndrome risk: a meta-analysis from 34 studies. PLoS One 9: e108552. doi: 10.1371/journal.pone.0108552
|
| [28] | Mantel N, Haenszel W (1959) Statistical aspects of the analysis of data from retrospective studies of disease. J Natl Cancer Inst 22: 719-748. |
| [29] |
DerSimonian R, Laird N (1986) Meta-analysis in clinical trials. Control Clin Trials 7: 177-188. doi: 10.1016/0197-2456(86)90046-2
|
| [30] |
Higgins JP, Thompson SE (2002) Quantifying heterogeneity in a meta-analysis. Stat Med 21: 1539-1558. doi: 10.1002/sim.1186
|
| [31] |
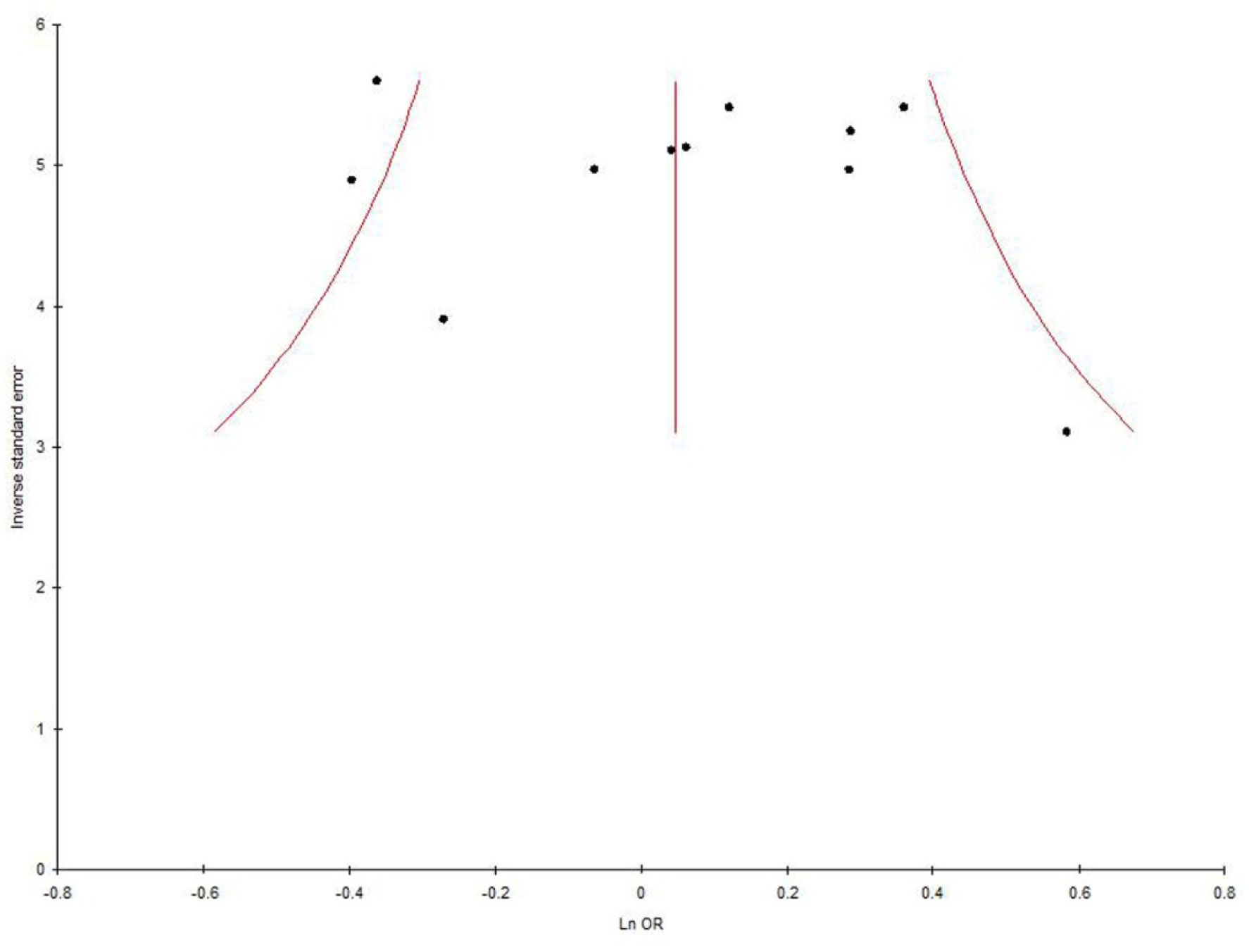
Egger M, Smith GD, Schneider M, et al. (1997) Bias in meta-analysis detected by a simple, graphical test. BMJ 315: 629-634. doi: 10.1136/bmj.315.7109.629
|
| [32] |
Bax L, Yu LM, Ikeda N, et al. (2006) Development and validation of MIX: comprehensive free software for meta-analysis of causal research data. BMC Med Res Methodol 6: 50-58. doi: 10.1186/1471-2288-6-50
|
| [33] | Wallace BC, Dahabreh IJ, Trikalinos TA, et al. (2013) Closing the gap between methodologists and end-users: R as a computational back-end. J Stat Softw 49: 1-15. |
| [34] |
Bonsch D, Bayerlein K, Reulbach U, et al. (2006) Different allele-distribution of Mthfr 677 C → T and Mthfr- 393 C→ a in patients classified according to subtypes of Lesch's typology. Alcohol Alcohol 41: 364-367. doi: 10.1093/alcalc/agl024
|
| [35] |
Lutz UC, Batra A, Wiatr G, et al. (2007) Significant impact of MTHFR C677T polymorphism on plasma homovanillic acid (HVA) levels among alcohol-dependent patients. Addict Biol 12: 100-105. doi: 10.1111/j.1369-1600.2006.00046.x
|
| [36] |
Fabris C, Toniutto P, Falleti E, et al. (2009) MTHFR C677T polymorphism and risk of HCC in patients with liver cirrhosis: role of male gender and alcohol consumption. Alcohol Clin Exp Res 33: 102-107. doi: 10.1111/j.1530-0277.2008.00816.x
|
| [37] |
Shin S, Stewart R, Ferri CP, et al. (2010) An investigation of associations between alcohol use disorder and polymorphisms on ALDH2, BDNF, 5-HTTLPR, and MTHFR genes in older Korean men. Int J Geriatr Psychiatry 25: 441-448. doi: 10.1002/gps.2358
|
| [38] |
Supic G, Jovic N, Kozomara R, et al. (2011) Interaction between the MTHFR C677T polymorphism and alcohol—impact on oral cancer risk and multiple DNA methylation of tumor-related genes. J Dent Res 90: 65-70. doi: 10.1177/0022034510385243
|
| [39] | Singh HK, Salam K, Saraswathy KN (2014) A study on MTHFR C677T gene polymorphism and alcohol dependence among Meiteis of Manipur, India. J Biomark . |
| [40] |
Singh HS, Devi S, Saraswathy K (2015) Methylenetetrahydrofolate reductase (MTHFR) C677T gene polymorphism and alcohol consumption in hyperhomocysteinaemia: a population-based study from northeast India. J Genet 94: 121-124. doi: 10.1007/s12041-015-0476-2
|
| [41] |
Cravo ML, Camilo ME (2000) Hyperhomocysteinemia in chronic alcoholism: relations to folic acid and vitamins B(6) and B(12) status. Nutrition 16: 296-302. doi: 10.1016/S0899-9007(99)00297-X
|
| [42] |
Amin F, Davidson M, Davis KL (1992) Homovanillic acid measurement in clinical research: a review of methodology. Schizophr Bull 18: 123-148. doi: 10.1093/schbul/18.1.123
|
| [43] |
Lee ES, Chen H, Soliman KF, et al. (2005) Effects of homocysteine on the dopaminergic system and behavior in rodents. Neurotoxicology 26: 361-371. doi: 10.1016/j.neuro.2005.01.008
|
| [44] |
Ioannidis JP, Rosenberg PS, Goedert JJ, et al. (2002) International meta-analysis of HIV host genetics. Commentary: meta-analysis of individual participants' data in genetic epidemiology. Am J Epidemiol 156: 204-210. doi: 10.1093/aje/kwf031
|
| [45] |
Rai V (2018) Strong association of C677T polymorphism of methylenetetrahydrofolate reductase gene with nosyndromic cleft lip/palate (nsCL/P). Indian J Clin Biochem 33: 5-15. doi: 10.1007/s12291-017-0673-2
|
| [46] | Rai V (2011) Polymorphism in folate metabolic pathway gene as maternal risk factor for Down syndrome. Int J Biol Med Res 2: 1055-1060. |
| [47] |
Rai V, Yadav U, Kumar P (2017) Null association of maternal MTHFR A1298C polymorphism with Down syndrome pregnancy: an updated meta-analysis. Egypt J Med Hum Genet 18: 9-18. doi: 10.1016/j.ejmhg.2016.04.003
|
| [48] |
Rai V, Kumar P (2018) Fetal MTHFR C677T polymorphism confers no susceptibility to Down Syndrome: evidence from meta-analysis. Egyptian J Med Hum Genet 19: 53-58. doi: 10.1016/j.ejmhg.2017.06.006
|
| [49] |
Rai V, Kumar P (2017) Methylenetetrahydrofolate reductase C677T polymorphism and risk for male infertility in Asian population. Indian J Clin Biochem 32: 253-260. doi: 10.1007/s12291-017-0640-y
|
| [50] | Rai V (2011) Evaluation of methylenetetrahydrofolate reductase gene variant (C677T) as risk factor for bipolar disorder. Cell Mo Bio 57: 1558-1566. |
| [51] |
Yadav U, Kumar P, Gupta S, et al. (2016) Role of MTHFR C677T gene polymorphism in the susceptibility of schizophrenia: an updated meta-analysis. Asian J Psychiatry 20: 41-51. doi: 10.1016/j.ajp.2016.02.002
|
| [52] | Rai V, Yadav U, Kumar P, et al. (2017) Methylenetetrahydrofolate reductase A1298C genetic variant & risk of schizophrenia: a meta-analysis. Indian J Med Res 145: 437-447. |
| [53] |
Rai V (2017) Association of C677T polymorphism (rs1801133) in MTHFR gene with depression. Cell Mol Biol 63: 60-67. doi: 10.14715/cmb/2017.63.6.13
|
| [54] |
Kumar P, Rai V (2020) Catechol-O-methyltransferase gene Val158Met polymorphism and obsessive compulsive disorder susceptibility: a meta-analysis. Metab Brain Dis 35: 241-251. doi: 10.1007/s11011-019-00495-0
|
| [55] | Rai V (2016) The MTHFR C677T polymorphism and hyperuricemia risk: a meta-analysis of 558 cases and 912 controls. Metabolomics 6: 2153-0769.1000166. |
| [56] |
Rai V, Kumar P (2018) Methylenetetrahydrofolate reductase C677T polymorphism and susceptibility to epilepsy. Neurol Sci 39: 2033-2041. doi: 10.1007/s10072-018-3583-z
|
| [57] |
Rai V (2016) Folate pathway gene methylenetetrahydrofolate reductase C677T polymorphism and Alzheimer disease risk in Asian population. Indian J Clin Biochem 31: 245-252. doi: 10.1007/s12291-015-0512-2
|
| [58] |
Kumar P, Rai V (2018) MTHFR C677T polymorphism and risk of esophageal cancer: an updated meta-analysis. Egypt J Med Hum Genet 19: 273-284. doi: 10.1016/j.ejmhg.2018.04.003
|
| [59] | Rai V (2016) Methylenetetrahydrofolate reductase gene C677T polymorphism and its association with ovary cancer. J Health Med Informat 7: 2. |
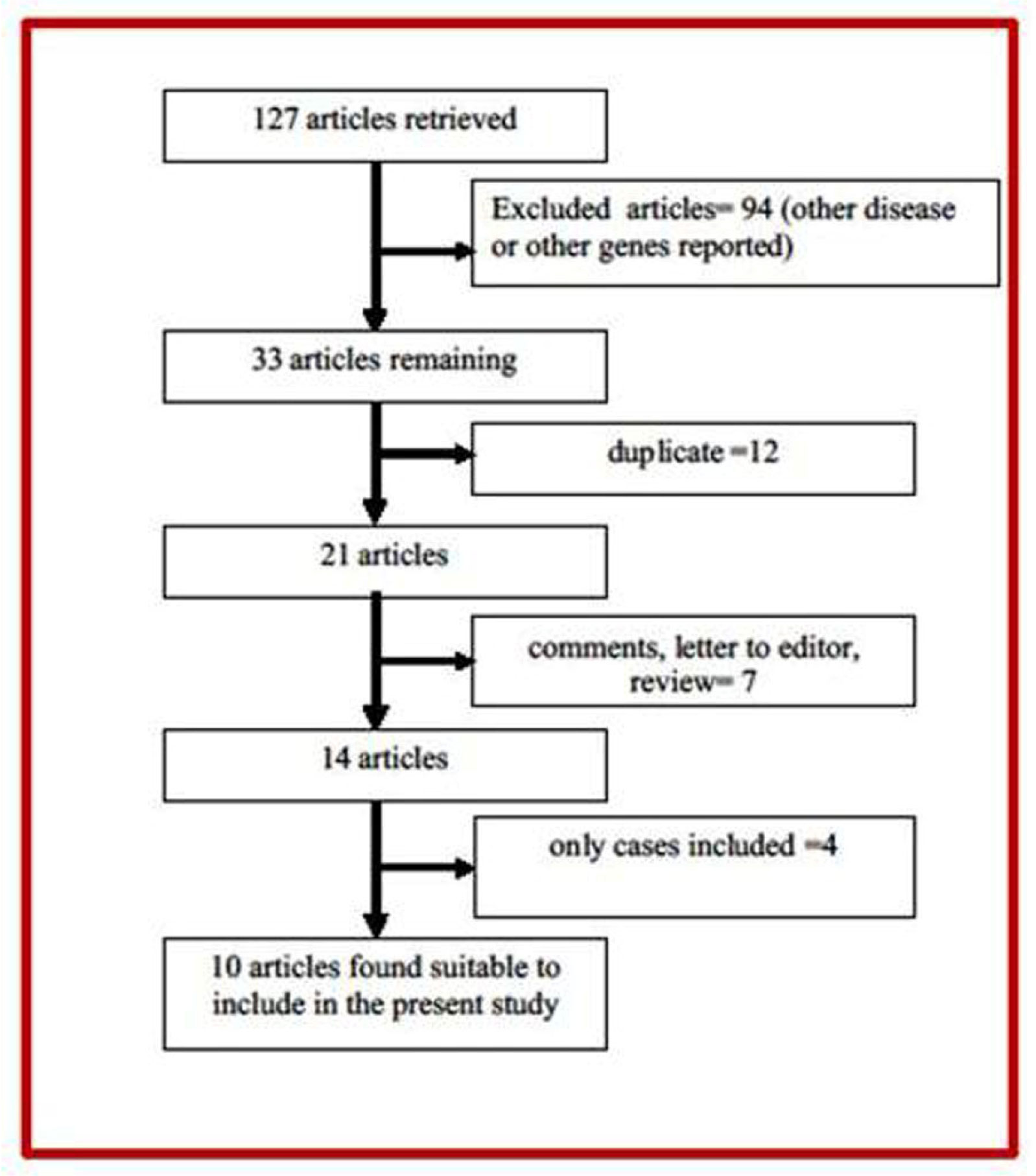
Figures(6) / Tables(2)

Vandana Rai, Pradeep Kumar. Methylenetetrahydrofolate reductase (MTHFR) gene C677T (rs1801133) polymorphism and risk of alcohol dependence: a meta-analysis[J]. AIMS Neuroscience, 2021, 8(2): 212-225. doi: 10.3934/Neuroscience.2021011







 DownLoad:
DownLoad: