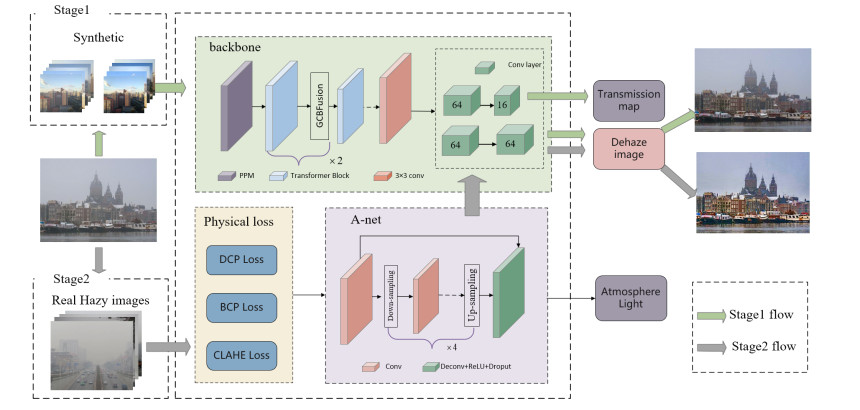
Aiming at the problems of local dehazing distortion and incomplete global dehazing of existing algorithms in real airborne cockpit environments, a two-stage dehazing method PhysiFormer combining physical a priori with a Transformer oriented flight perspective was proposed. The first stage used synthetic pairwise data to pre-train the dehazing model. First, a pyramid pooling module (PPM) was introduced in the Transformer for multiscale feature extraction to solve the problem of poor recovery of local details, then a global context fusion mechanism was used to enable the model to better perceive global information. Finally, considering that combining the physical a priori needs to rely on the estimation of the atmosphere light, an encoding-decoding structure based on the residual blocks was used to estimate the atmosphere light, which was then used for dehazing through the atmospheric scattering model for dehazing. The second stage used real images combined with physical priori to optimize the model to better fit the real airborne environment. The experimental results show that the proposed method has better naturalness image quality evaluator (NIQE) and blind/referenceless image spatial quality evaluator (BRISQUE) indexes and exhibits the best dehazing visual effect in the tests of dense haze, non-uniform haze and real haze images, which effectively improves the problems of color distortion and haze residue.
Citation: Tian Ma, Huimin Zhao, Xue Qin. A dehazing method for flight view images based on transformer and physical priori[J]. Mathematical Biosciences and Engineering, 2023, 20(12): 20727-20747. doi: 10.3934/mbe.2023917
Aiming at the problems of local dehazing distortion and incomplete global dehazing of existing algorithms in real airborne cockpit environments, a two-stage dehazing method PhysiFormer combining physical a priori with a Transformer oriented flight perspective was proposed. The first stage used synthetic pairwise data to pre-train the dehazing model. First, a pyramid pooling module (PPM) was introduced in the Transformer for multiscale feature extraction to solve the problem of poor recovery of local details, then a global context fusion mechanism was used to enable the model to better perceive global information. Finally, considering that combining the physical a priori needs to rely on the estimation of the atmosphere light, an encoding-decoding structure based on the residual blocks was used to estimate the atmosphere light, which was then used for dehazing through the atmospheric scattering model for dehazing. The second stage used real images combined with physical priori to optimize the model to better fit the real airborne environment. The experimental results show that the proposed method has better naturalness image quality evaluator (NIQE) and blind/referenceless image spatial quality evaluator (BRISQUE) indexes and exhibits the best dehazing visual effect in the tests of dense haze, non-uniform haze and real haze images, which effectively improves the problems of color distortion and haze residue.

| [1] | S. K. Nayar, S. G. Narasimhan, Vision in bad weather, in Proceedings of the Seventh IEEE International Conference on Computer Vision, 2 (1999), 820–827. https://doi.org/10.1109/ICCV.1999.790306 |
| [2] | K. He, J. Sun, X. Tang, Single image haze removal using dark channel prior, in 2009 IEEE Conference on Computer Vision and Pattern Recognition, (2009), 1956–1963. https://doi.org/10.1109/CVPR.2009.5206515 |
| [3] |
Q. Zhu, J. Mai, L. Shao, A fast single image haze removal algorithm using color attenuation prior, IEEE Trans. Image Process., 24 (2015), 3522–3533. https://doi.org/10.1109/TIP.2015.2446191 doi: 10.1109/TIP.2015.2446191

|
| [4] | R. Fattal, Dehazing using color-lines, ACM Trans. Graphics, 34 (2014), 1–14. |
| [5] | D. Berman, T. Treibitz, S. Avidan, Non-local image dehazing, in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 34 (2016), 1674–1682. https://doi.org/10.1109/CVPR.2016.185 |
| [6] | H. Zhang, V. M. Patel, Densely connected pyramid dehazing network, in 2018 IEEE/CVF Con-ference on Computer Vision and Pattern Recognition, (2018), 3194–3203. https://doi.org/10.1109/CVPR.2018.00337 |
| [7] | D. Chen, M. He, Q. Fan, J. Liao, L. Zhang, D. Hou, et al., Gated context aggregation network for image dehazing and deraining, in 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), (2019), 1375–1383. https://doi.org/10.1109/WACV.2019.00151 |
| [8] | X. Qin, Z. Wang, Y. Bai, X. Xie, H. Jia, FFA-Net: Feature fusion attention network for single image dehazing, in Proceedings of the AAAI Conference on Artificial Intelligence, 34 (2020), 11908–11915. |
| [9] |
G. Gao, J. Cao, C. Bao, Q. Hao, A. Ma, A novel transformer-based attention network for image dehazing, Sensors, 22 (2022), 3428. https://doi.org/10.3390/s22093428 doi: 10.3390/s22093428
|
| [10] |
S. Li, Q. Yuan, Y. Zhang, B. Lv, F. Wei, Image dehazing algorithm based on deep learning coupled local and global features, Appl. Sci., 12 (2022), 8552. https://doi.org/10.3390/app12178552 doi: 10.3390/app12178552
|
| [11] |
Y. Song, Z. He, H. Qian, X. Du, Vision transformers for single image dehazing, IEEE Trans. Image Process., 32 (2023), 1927–1941. https://doi.org/10.1109/TIP.2023.3256763 doi: 10.1109/TIP.2023.3256763
|
| [12] | Z. Liu, Y. Lin, Y. Gao, H. Hu, Y. Wei, Z. Zhang, et al., Swin transformer: Hierarchical vision transformer using shifted windows, in 2021 IEEE/CVF International Conference on Computer Vision (ICCV), (2021), 9992–10002. https://doi.org/10.1109/ICCV48922.2021.00986 |
| [13] | W. Huang, J. Li, C. Qi, A defogging algorithm for dense fog images via low-rank and dictionary expression decomposition, J. Xi'an Jiaotong Univ., 54 (2020), 118–125. |
| [14] | T. Gao, M. Liu, T. Chen, S. Wang, S. Jiang, A far and near scene fusion defogging algorithm based on the prior of dark-light channel, J. Xi'an Jiaotong Univ., 55 (2021), 78–86. |
| [15] | Y. Yang, X. Chen, An image dehazing method combining adaptive brightness transformation inequality to estimate transmittance, J. Xi'an Jiaotong Univ., 55 (2021), 69–76. |
| [16] | H. Huang, K. Hu, J. Song, H. Huang, A twice optimization method for solving transmittance with haze-lines, J. Xi'an Jiaotong Univ., 55 (2021), 130–138. |
| [17] |
T. Ma, C. Fu, J. Yang, J. Zhang, C. Yang, RF-Net: Unsupervised low-light image enhancement based on retinex and exposure fusion, Comput. Mater. Continua, 77 (2023), 1103–1122. https://doi.org/10.32604/cmc.2023.042416 doi: 10.32604/cmc.2023.042416
|
| [18] |
B. Cai, X. Xu, K. Jia, C. Qing, D. Tao, Dehazenet: An end-to-end system for single image haze removal, IEEE Trans. Image Process., 25 (2016), 5187–5198. https://doi.org/10.1109/TIP.2016.2598681 doi: 10.1109/TIP.2016.2598681
|
| [19] | B. Li, X. Peng, Z. Wang, J. Xu, D. Feng, AOD-Net: All-in-one dehazing network, in International Conference on Computer Vision (ICCV), (2017), 4780–4788. https://doi.org/10.1109/ICCV.2017.511 |
| [20] | Y. Qu, Y. Chen, J. Huang, Y. Xie, Enhanced pix2pix dehazing network, in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 8182–8160. https://doi.org/10.1109/CVPR.2019.00835 |
| [21] |
X. Zhu, S. Li, Y. Gan, Y. Zhang, B. Sun, Multi-stream fusion network with generalized smooth L1 loss for single image dehazing, IEEE Trans. Image Process., 30 (2021), 7620–7635. https://doi.org/10.1109/TIP.2021.3108022 doi: 10.1109/TIP.2021.3108022
|
| [22] | C. Long, X. Li, Y. Jing, H. Shen, Bishift networks for thick cloud removal with multitemporal remote sensing images, Int. J. Intell. Syst., 2023 (2023). https://doi.org/10.1155/2023/9953198 |
| [23] |
W. Liu, X. Hou, J. Duan, G. Qiu, End-to-end single image fog removal using enhanced cycle consistent adversarial networks, IEEE Trans. Image Process., 29 (2020), 7819–7833. https://doi.org/10.1109/TIP.2020.3007844 doi: 10.1109/TIP.2020.3007844
|
| [24] | J. Dong, J. Pan, Physics-based feature dehazing networks, in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, (2020), 188–204. https://doi.org/10.1007/978-3-030-58577-8_12 |
| [25] | Q. Deng, Z. Huang, C. C. Tsai, C. W. Lin, Hardgan: A haze-aware representation distillation GAN for single image dehazing, in European Conference on Computer Vision, (2020), 722–738. |
| [26] | H. Dong, J. Pan, L. Xiang, Z. Hu, X. Zhang, F. Wang, et al., Multi-scale boosted dehazing network with dense feature fusion, in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition 14 CMES, (2020), 2154–2164. https://doi.org/10.1109/CVPR42600.2020.00223 |
| [27] | X. Liu, Y. Ma, Z. Shi, J. Chen, Griddehazenet: Attention-based multi-scale network for image dehazing, in Proceedings of the IEEE/CVF International Conference on Computer Vision, (2019), 7314–7323. |
| [28] | H. Wu, Y. Qu, S. Lin, J. Shou, R. Qiao, Z. Zhang, et al., Contrastive learning for compact single image dehazing, in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2021), 10546–10555. https://doi.org/10.1109/CVPR46437.2021.01041 |
| [29] |
C. Wang, H. Z. Shen, F. Fan, M. W. Shao, C. S, Yang, J. C. Luo, et al., EAA-Net: A novel edge assisted attention network for single image dehazing, Knowledge-Based Syst., 228 (2021), 107279. https://doi.org/10.1016/j.knosys.2021.107279 doi: 10.1016/j.knosys.2021.107279
|
| [30] | A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, et al., Attention is all you need, in Advances in Neural Information Processing Systems, 30 (2017). |
| [31] | A. Dosovitskiy, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, et al., An image is worth 16x16 words: Transformers for image recognition at scale, preprint, arXiv: 2010.11929. |
| [32] |
T. Ma, J. An, R. Xi, J. Yang, J. Lyu, F. Li, TPE: Lightweight transformer photo enhancement based on curve adjustment, IEEE Access, 10 (2022), 74425–74435. https://doi.org/10.1109/ACCESS.2022.3191416 doi: 10.1109/ACCESS.2022.3191416
|
| [33] | L. Yuan, Y. Chen, T. Wang, W. Yu, Y. Shi, Z. H. Jiang, et al., Tokens-to-token vit: Training vision trans-formers from scratch on imagenet, in Proceedings of the IEEE/CVF International Conference on Computer Vision, (2021), 558–567. |
| [34] | S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, M. Yang, Restormer: Efficient transformer for high-resolution image restoration, in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2022), 5718–5729. https://doi.org/10.1109/CVPR52688.2022.00564 |
| [35] | Y. Qiu, K. Zhang, C. Wang, W. Luo, H. Li, Z. Jin, MB-TaylorFormer: Multi-branch efficient transformer expanded by Taylor formula for image dehazing, in Proceedings of the IEEE/CVF International Conference on Computer Vision, (2023), 12802–12813. |
| [36] |
B. Li, W. Ren, D. Fu, D. Tao, D. Feng, W. Zeng, et al., Benchmarking single-image dehazing and beyond, IEEE Trans. Image Process., 28 (2019), 492–505. https://doi.org/10.1109/TIP.2018.2867951 doi: 10.1109/TIP.2018.2867951
|
| [37] | C. O. Ancuti, C. Ancuti, R. Timofte, NH-HAZE: An image dehazing benchmark with nonhomogeneous hazy and haze-free images, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, (2020), 444–445. |
| [38] | H. Dong, J. Pan, L. Xiang, Z. Hu, X. Zhang, F. Wang, et al., Multi-scale boosted dehazing network with dense feature fusion, in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), (2020), 2154–2164. https://doi.org/10.1109/CVPR42600.2020.00223 |
| [39] | H. B. Ji, X. Feng, W. J. Pei, J. X. Li, G. M. Lu, U2-Former: A Nested U-shaped transformer for image restoration, preprint, arXiv: 2112.02279. |
| [40] | Z. Yu, Z. Wang, J. Yu, D. Liu, H. Song, Z. Li, Cybersecurity of unmanned aerial vehicles: A survey, IEEE Aerosp. Electron. Syst. Mag., 2023 (2023). https://doi.org/10.1109/MAES.2023.3318226 |











Figures(12) / Tables(5)

Tian Ma, Huimin Zhao, Xue Qin. A dehazing method for flight view images based on transformer and physical priori[J]. Mathematical Biosciences and Engineering, 2023, 20(12): 20727-20747. doi: 10.3934/mbe.2023917







 DownLoad:
DownLoad: