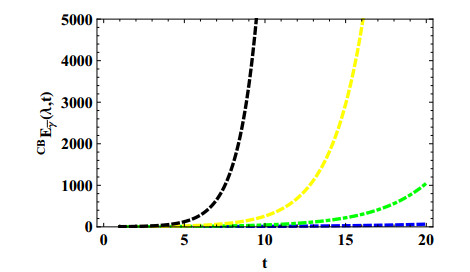
Nabla discrete fractional Mittag-Leffler (ML) functions are the key of discrete fractional calculus within nabla analysis since they extend nabla discrete exponential functions. In this article, we define two new nabla discrete ML functions depending on the Cayley-exponential function on time scales. While, the nabla discrete ML function $ E_{\overline{\gamma}} (\lambda, t) $ converges for $ |\lambda| < 1 $, both of the defined discrete functions converge for more relaxed $ \lambda $. The nabla discrete Laplace transforms of the newly defined functions are calculated and confirmed as well. Some illustrative graphs for the two extensions are provided.
Citation: Thabet Abdeljawad. Two discrete Mittag-Leffler extensions of the Cayley-exponential function[J]. AIMS Mathematics, 2023, 8(6): 13543-13555. doi: 10.3934/math.2023687
Nabla discrete fractional Mittag-Leffler (ML) functions are the key of discrete fractional calculus within nabla analysis since they extend nabla discrete exponential functions. In this article, we define two new nabla discrete ML functions depending on the Cayley-exponential function on time scales. While, the nabla discrete ML function $ E_{\overline{\gamma}} (\lambda, t) $ converges for $ |\lambda| < 1 $, both of the defined discrete functions converge for more relaxed $ \lambda $. The nabla discrete Laplace transforms of the newly defined functions are calculated and confirmed as well. Some illustrative graphs for the two extensions are provided.

| [1] |
B. Abdalla, On the oscillation of $q$-fractional difference equations, Adv. Differ. Equ., 2017 (2017), 254. https://doi.org/10.1186/s13662-017-1316-x doi: 10.1186/s13662-017-1316-x

|
| [2] |
T. Abdeljawad, On Riemann and Caputo fractional differences, Comput. Math. Appl., 62 (2011), 1602–1611. https://doi.org/10.1016/j.camwa.2011.03.036 doi: 10.1016/j.camwa.2011.03.036
|
| [3] |
T. Abdeljawad, F. M. Atici, On the definitions of nabla fractional differences, Abstr. Appl. Anal., 2012 (2012), 1–13. https://doi.org/10.1155/2012/406757 doi: 10.1155/2012/406757
|
| [4] |
T. Abdeljawad, On delta and nabla Caputo fractional differences and dual identities, Discrete Dyn. Nat. Soc., 2013 (2013), 1–12. https://doi.org/10.1155/2013/406910 doi: 10.1155/2013/406910
|
| [5] |
T. Abdeljawad, F. Jarad, D. Baleanu, A semigroup-like property for discrete Mittag-Leffler functions, Adv. Differ. Equ., 2012 (2012), 72. https://doi.org/10.1186/1687-1847-2012-72 doi: 10.1186/1687-1847-2012-72
|
| [6] |
T. Abdeljawad, Different type kernel $h$-fractional differences and their fractional $h$-sums, Chaos Solitons Fract., 116 (2018), 146–156. https://doi.org/10.1016/j.chaos.2018.09.022 doi: 10.1016/j.chaos.2018.09.022
|
| [7] |
N. Acar, F. M. Atıcı, Exponential functions of discrete fractional calculus, Appl. Anal. Discrete Math., 7 (2013), 343–353. https://doi.org/10.2298/AADM130828020A doi: 10.2298/AADM130828020A
|
| [8] |
J. Alzabut, S. R. Grace, J. M. Jonnalagadda, E. Thandapani, Bounded non-oscillatory solutions of nabla forced fractional difference equations with positive and negative terms, Qual. Theory Dyn. Syst., 22 (2023), 28. https://doi.org/10.1007/s12346-022-00729-0 doi: 10.1007/s12346-022-00729-0
|
| [9] | F. M. Atıcı, P. W. Eloe, Discrete fractional calculus with the nabla operator, Electr. J. Qual. Theory Differ. Equ., 2009, 1–12. |
| [10] | M. Bohner, A. Peterson, Advances in dynamic equations on time scales, Birkhäuser, Boston, 2003. https://doi.org/10.1007/978-0-8176-8230-9 |
| [11] |
J. L. Cieslinski, Some implications of a new approach to exponential functions on time scales, Discrete Cont. Dyn. Syst., 2011 (2011), 302–311. https://doi.org/10.3934/proc.2011.2011.302 doi: 10.3934/proc.2011.2011.302
|
| [12] | C. Goodrich, A. Peterson, Discrete fractional calculus, Springer, 2015. https://doi.org/10.1007/978-3-319-25562-0 |
| [13] |
M. T. Holm, The Laplace transform in discrete fractional calculus, Comput. Math. Appl., 62 (2011), 1591–1601. https://doi.org/10.1016/j.camwa.2011.04.019 doi: 10.1016/j.camwa.2011.04.019
|
| [14] | A. Kilbas, H. M. Srivastava, J. J. Trujillo, Theory and application of fractional differential equations, North Holland Mathematics Studies, 2006. |
| [15] |
A. A. Kilbas, M. Saigo, R. K. Saxena, Generalized Mittag-Leffler function and generalized fractional calculus operators, Integr. Transf. Spec. Funct., 15 (2004), 31–49. https://doi.org/10.1080/10652460310001600717 doi: 10.1080/10652460310001600717
|
| [16] |
N. Mlaiki, Integral-type fractional equations with a proportional Riemann-Liouville derivative, J. Math., 2021 (2021), 1–7. https://doi.org/10.1155/2021/9990439 doi: 10.1155/2021/9990439
|
| [17] | I. Podlubny, Fractional differential equations, Academic Press, San Diego CA, 1999. |
| [18] | T. T. Song, G. C. Wu, J. L. Wei, Hadamard fractional calculus on time scales, Fractals, 30 (2022) 2250145. |
| [19] |
G. C. Wu, D. Baleanu, S. Zeng, W. Luo, Mittag-Leffler function for discrete fractional modelling, J. King Saud Univ. Sci., 28 (2016), 99–102. https://doi.org/10.1016/j.jksus.2015.06.004 doi: 10.1016/j.jksus.2015.06.004
|
| [20] |
G. C. Wu, M. K. Luo, L. L. Huang, S. Banerjee, Short memory fractional differential equations for new neural network and memristor design, Nonlinear Dyn., 100 (2020), 3611–3623. https://doi.org/10.1007/s11071-020-05572-z doi: 10.1007/s11071-020-05572-z
|
| [21] |
D. Baleanu, G. C. Wu, Some further results of the Laplace transform for variable-order fractional difference equations, Fract. Calc. Appl. Anal., 22 (2019), 1641–1654. https://doi.org/10.1515/fca-2019-0084 doi: 10.1515/fca-2019-0084
|
| [22] | G. C. Wu, T. Abdeljawad, J. Liuc, D. Baleanud, K. T. Wu, Mittag-Leffler stability analysis of fractional discrete-time neural networks via fixed point technique, Nonlinear Anal.: Model. Contr., 24 (2019), 919–936. |

Figures(2)

Thabet Abdeljawad. Two discrete Mittag-Leffler extensions of the Cayley-exponential function[J]. AIMS Mathematics, 2023, 8(6): 13543-13555. doi: 10.3934/math.2023687







 DownLoad:
DownLoad: