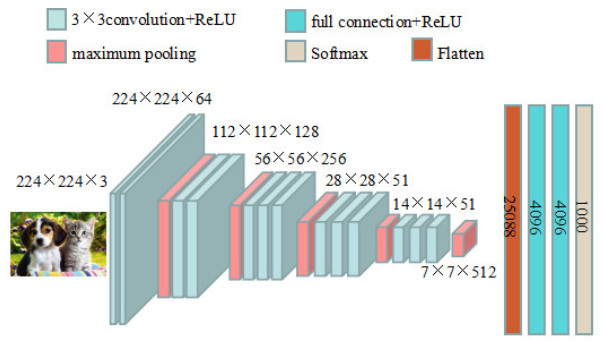
Breast cancer is the cancer with the highest incidence in women worldwide, and seriously threatens the lives and health of women. Mammography, which is commonly used for screening, is considered to be the most effective means of diagnosing breast cancer. Currently, computer-assisted breast mass systems based on mammography can help doctors improve film reading efficiency, but improving the accuracy of assisted diagnostic systems and reducing the false positive rate are still challenging tasks. In the image classification field, convolutional neural networks have obvious advantages over other classification algorithms. Aiming at the very small percentage of breast lesion area in breast X-ray images, in this paper, the classical VGG16 network model is improved by simplifying the network structure, optimizing the convolution form and introducing an attention mechanism. The improved model achieves 99.8 and 98.05% accuracy on the Mammographic Image Analysis Society (MIAS) and The Digital Database for Screening Mammography (DDSM), respectively, which is obviously superior to some methods of recent studies.
Citation: Yi Dong, Jinjiang Liu, Yihua Lan. A classification method for breast images based on an improved VGG16 network model[J]. Electronic Research Archive, 2023, 31(4): 2358-2373. doi: 10.3934/era.2023120
Breast cancer is the cancer with the highest incidence in women worldwide, and seriously threatens the lives and health of women. Mammography, which is commonly used for screening, is considered to be the most effective means of diagnosing breast cancer. Currently, computer-assisted breast mass systems based on mammography can help doctors improve film reading efficiency, but improving the accuracy of assisted diagnostic systems and reducing the false positive rate are still challenging tasks. In the image classification field, convolutional neural networks have obvious advantages over other classification algorithms. Aiming at the very small percentage of breast lesion area in breast X-ray images, in this paper, the classical VGG16 network model is improved by simplifying the network structure, optimizing the convolution form and introducing an attention mechanism. The improved model achieves 99.8 and 98.05% accuracy on the Mammographic Image Analysis Society (MIAS) and The Digital Database for Screening Mammography (DDSM), respectively, which is obviously superior to some methods of recent studies.

| [1] |
J. Tang, R. M. Rangayyan, J. Xu, Y. Yang, I. E. Naqa, Computer-aided breast cancer detection and diagnosis using mammography: recent advance, IEEE Trans. Inf. Technol. Biomed., 13 (2008), 236–251. https://doi.org/10.1109/TITB.2008.2009441 doi: 10.1109/TITB.2008.2009441

|
| [2] |
X. Liu, J. Tang, Mass classification in mammograms using selected geometry and texture features and a new SVM-based feature selection method, IEEE Syst. J., 8 (2014), 910–920. https://doi.org/10.1109/JSYST.2013.2286539. doi: 10.1109/JSYST.2013.2286539
|
| [3] | F. Mohanty, S. Rup, B. Dash, B. Majhi, M. N. S. Swamy, Mammogram classification using contourlet features with forest optimization-based feature selection approach, 78 (2019), 12805–12834. https://doi.org/10.1007/s11042-018-5804-0 |
| [4] |
D. A. Ragab, M. Sharkas, O. Attallah, Breast cancer diagnosis using an efficient CAD system based on multiple classifiers, Diagnostics, 9 (2019), 165–191. https://doi.org/10.3390/diagnostics9040165 doi: 10.3390/diagnostics9040165
|
| [5] |
A. Krizhevsky, I. Sutskever, G. E. Hinton, ImageNet classification with deep convolutional neural networks, Commun. ACM, 60 (2017), 84–90. https://doi.org/10.1145/3065386 doi: 10.1145/3065386
|
| [6] | K. Simonyan, A. Zisserman, Very deep convolutional networks for large-scale image recognition, preprint, arXiv: 1409.1556. |
| [7] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2016), 770–778. Available from: https://openaccess.thecvf.com/content_cvpr_2016/html/He_Deep_Residual_Learning_CVPR_2016_paper.html. |
| [8] | M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, L. Chen, MobileNetV2: inverted residuals and linear bottlenecks, in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2018), 4510–4520. https://doi.org/10.1109/CVPR.2018.00474 |
| [9] | G. Huang, Z. Liu, L. Maaten, K. Weinberger, Densely connected convolutional networks, in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2017), 2261–2269. https://doi.org/10.1109/CVPR.2017.243 |
| [10] | X. Ding, X. Zhang, N. Ma, J. Han, G. Ding, J. Sun, RepVGG: making VGG-style ConvNets great again, in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2021), 13728–13737. https://doi.org/10.1109/CVPR46437.2021.01352 |
| [11] | A. Goyal, A. Bochkovskiy, J. Deng, V. Koltun, Non-deep networks, preprint, arXiv: 2110.07641. |
| [12] | Z. Liu, H. Mao, C. Wu, C. Feichtenhofer, T. Darrell, S. Xie, A ConvNet for the 2020s, in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2022), 11966–11976. https://doi.org/10.1109/CVPR52688.2022.01167 |
| [13] |
A. Pan, S. Xu, S. Cheng, Y. She, Breast mass image recognition based on SVGG16, J. South-Cent. Minzu Univ. (Nat. Sci. Ed.), 40 (2021), 410–416. https://doi.org/10.12130/znmdzk.20210412 doi: 10.12130/znmdzk.20210412
|
| [14] | M. Hu, Breast Disease Image Classification Based on Improved Convolutional Neural Network and Multi-scale Feature Fusion, MD. thesis, Donghua University, 2023. https://doi.org/10.27012/d.cnki.gdhuu.2022.001136 |
| [15] | Y. Yang, M. Liu, X. Wang, Z. Xiao, Y. Jiang, Breast cancer image recognition based on DenseNet and transfer learning, J. Jilin Univ. (Inf. Sci. Ed.), 40 (2022), 213–218. Available from: http://xuebao.jlu.edu.cn/xxb/CN/Y2022/V40/I2/213. |
| [16] |
M. Meng, L. Li, G. He, M. Zhang, D. Shen, C. Pan, et al., A preliminary study of MobileNetV2 to downgrade classification in mammographic BI-RADS 4 lesions, J. Clin. Radiol., 41 (2022), 1868–1873. https://doi.org/10.13437/j.cnki.jcr.2022.10.031 doi: 10.13437/j.cnki.jcr.2022.10.031
|
| [17] | S. Ioffe, C. Szegedy, Batch normalization: accelerating deep network training by reducing internal covariate shift, in Proceedings of the 32nd International Conference on Machine Learning, (2015), 448–456. Available from: http://proceedings.mlr.press/v37/ioffe15.html. |
| [18] | Q. Wang, B. Wu, P. Zhu, P. Li, W. Zuo, Q. Hu, ECA-Net: efficient channel attention for deep convolutional neural networks, in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2020), 11531–11539. https://doi.org/10.1109/CVPR42600.2020.01155 |







Figures(8) / Tables(6)
Yi Dong, Jinjiang Liu, Yihua Lan. A classification method for breast images based on an improved VGG16 network model[J]. Electronic Research Archive, 2023, 31(4): 2358-2373. doi: 10.3934/era.2023120







 DownLoad:
DownLoad: