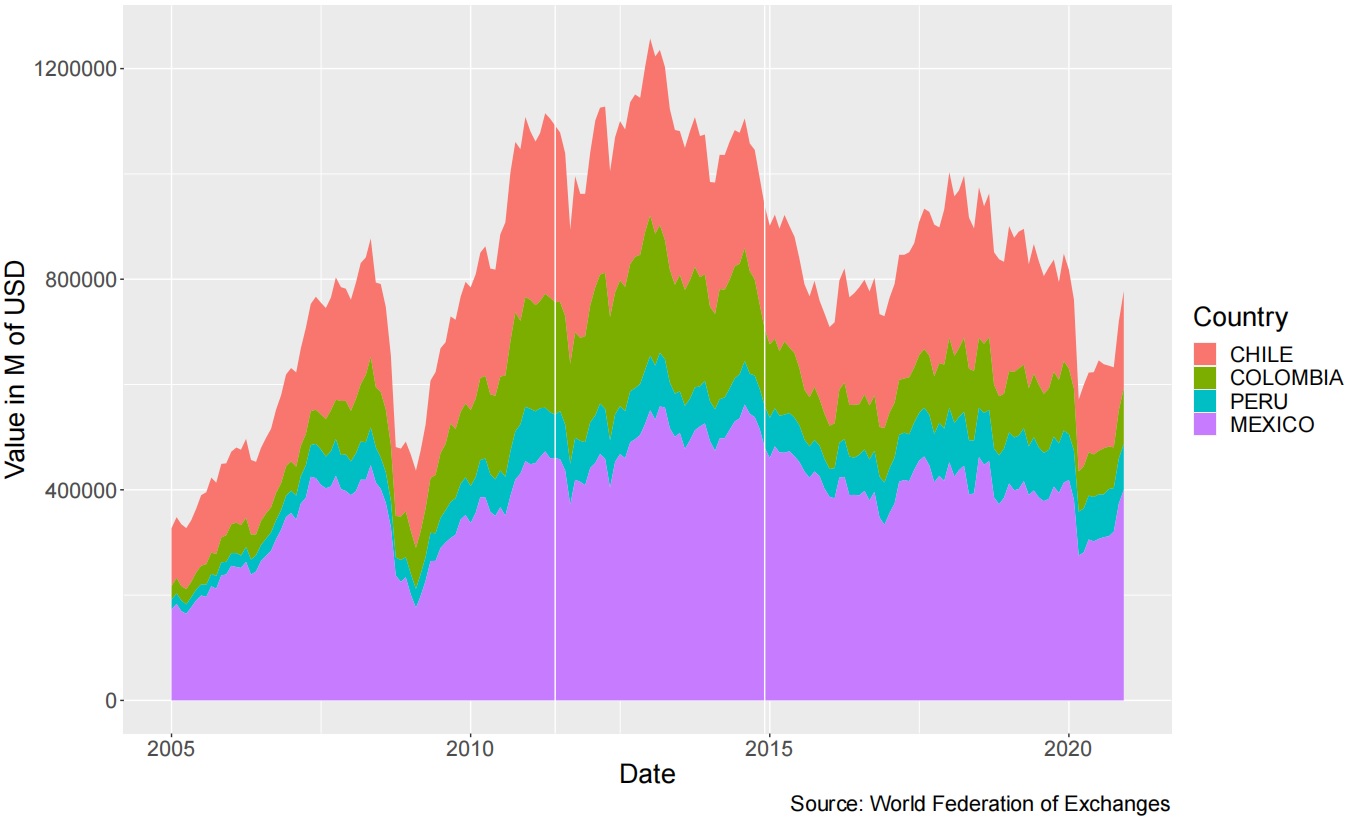
The FeldsteinHorioka1980 study on investment flows through the correlation of domestic saving and investment concluded that liberalization of capital markets does not necessarily lead to a movement of capital looking for a better allocation of resources, as classical theory would suggest. Ever since, literature has been prolific regarding this "puzzle", with arguments for and against this conclusion. This paper aims to analyze the issue from a different perspective. In recent years, the stock markets of Chile, Colombia, Mexico and Peru joined the Latin American Integrated Market through an agreement that allows investors in any of the participating markets to invest in the others as if they were investing locally. Compositional methods are used to assess the hypothesis of a potential flow of capital between markets generated by the creation of the joint market. First, cross-sectional methods for compositional data were used to test the hypothesis. As a result, it was not possible to find a change in the composition of the investment in the four markets produced by the creation of the joint market. Secondly, vector autoregressive models were estimated and tested for structural breaks in the parameters. However, these models were not found to be informative. In conclusion, it was not possible to reject the Felstein-Horioka hypothesis, supporting the idea that liberalization is not enough to generate capital flows between markets.
Citation: Juan David Vega Baquero, Miguel Santolino. Capital flows in integrated capital markets: MILA case[J]. Quantitative Finance and Economics, 2022, 6(4): 622-639. doi: 10.3934/QFE.2022027
The FeldsteinHorioka1980 study on investment flows through the correlation of domestic saving and investment concluded that liberalization of capital markets does not necessarily lead to a movement of capital looking for a better allocation of resources, as classical theory would suggest. Ever since, literature has been prolific regarding this "puzzle", with arguments for and against this conclusion. This paper aims to analyze the issue from a different perspective. In recent years, the stock markets of Chile, Colombia, Mexico and Peru joined the Latin American Integrated Market through an agreement that allows investors in any of the participating markets to invest in the others as if they were investing locally. Compositional methods are used to assess the hypothesis of a potential flow of capital between markets generated by the creation of the joint market. First, cross-sectional methods for compositional data were used to test the hypothesis. As a result, it was not possible to find a change in the composition of the investment in the four markets produced by the creation of the joint market. Secondly, vector autoregressive models were estimated and tested for structural breaks in the parameters. However, these models were not found to be informative. In conclusion, it was not possible to reject the Felstein-Horioka hypothesis, supporting the idea that liberalization is not enough to generate capital flows between markets.

| [1] | Aitchison J (1986) The statistical analysis of compositional data. Chapman & Hall, London. |
| [2] |
Belles-Sampera J, Guillen M, Santolino M (2016) Compositional methods applied to capital allocation problems. J Risk 19: 1–15. https://doi.org/10.21314/JOR.2016.345 doi: 10.21314/JOR.2016.345

|
| [3] | Bellod-Redondo JF (1996) Ahorro e inversión en el largo plazo: El caso de la América Latina. El Trimest Econ 43: 1113–1137. |
| [4] |
Boonen TJ, Guillen M, Santolino M (2019) Forecasting compositional risk allocations. Insur Math Econ 84: 79–86. https://doi.org/10.1016/j.insmatheco.2018.10.002 doi: 10.1016/j.insmatheco.2018.10.002
|
| [5] |
Chen S, Dong H (2020) Dynamic network connectedness of Bitcoin markets: Evidence from realized volatility. Front Phys 8: 582817. https://doi.org/10.3389/fphy.2020.582817 doi: 10.3389/fphy.2020.582817
|
| [6] |
Coakley J, Kulasi F, Smith S (1996) Current account solvency and the Feldstein-Horioka puzzle. Econ J 106: 620–627. https://doi.org/10.2307/2235567 doi: 10.2307/2235567
|
| [7] | Comas-Cufí M, Martín-Fernández JA, Mateu-Figueras (2016) Log-ratio methods in mixture models for compositional data sets. SORT-STAT OPER RES T 1: 349–374. |
| [8] |
Dong H, Chen L, Zhang X, et al. (2020) The asymmetric effect of volatility spillover in global virtual financial asset markets: The case of Bitcoin. Emerg Mark Finance Trade 56: 1293–1311. https://doi.org/10.1080/1540496X.2019.1671819 doi: 10.1080/1540496X.2019.1671819
|
| [9] |
Drakos AA, Kouretas GP, Stavroyiannis S, et al. (2017) Is the Feldstein-Horioka puzzle still with us? national saving-investment dynamics and international capital mobility: A panel data analysis across EU member countries. J INT FINANC MARK I 47: 76–88. https://doi.org/10.1016/j.intfin.2016.11.006 doi: 10.1016/j.intfin.2016.11.006
|
| [10] |
Egozcue J, Pawlowsky-Glahn V, Mateu-Figueras G, et al. (2003) Isometric logratio transformations for compositional data analysis. Math Geol 35: 279–300. https://doi.org/10.1023/A:1023818214614 doi: 10.1023/A:1023818214614
|
| [11] |
Feldstein M, Horioka C (1980) Domestic saving and international capital flows. Econ J 90: 314–329. https://doi.org/10.2307/2231790 doi: 10.2307/2231790
|
| [12] |
Ford N, Horioka C (2017) The 'real' explanation of the Feldstein-Horioka puzzle. Appl Econ Lett 24: 95–97. https://doi.org/10.1080/13504851.2016.1164814 doi: 10.1080/13504851.2016.1164814
|
| [13] |
Fouquau J, Hurlin C, Rabaud I (2008) The Feldstein-Horioka puzzle: A panel smooth transition regression approach. Econ Model 25: 284–299. https://doi.org/10.1016/j.econmod.2007.06.008 doi: 10.1016/j.econmod.2007.06.008
|
| [14] | Fuller WA (1996) Introduction to Statistical Time Series. John Wiley and Sons, New York. |
| [15] |
Granger CWJ (1969) Investigating causal relations by econometric models and cross-spectral methods. Econometrica 37: 424–438. https://doi.org/10.2307/1912791 doi: 10.2307/1912791
|
| [16] |
Ibarra-Yunez A (2008) Capital mobility and mexico's challenge toward financial integration. Lat Am Econ Rev 9: 256–27. https://doi.org/10.1080/10978520902873250 doi: 10.1080/10978520902873250
|
| [17] |
Jia S, Dong H, Yang H (2021) Asymmetric risk spillover of the international crude oil market in the perspective of crude oil dual attributes. Front Environ Sci 9: 720278. https://doi.org/10.3389/fenvs.2021.720278 doi: 10.3389/fenvs.2021.720278
|
| [18] | Martín-Fernádez JA, Bren M, Barcelo-Vidal C, et al. (1999) A measure of difference for compositional data based on measures of divergence. |
| [19] | McLachlan G, Peel D (2004) Finite Mixture Models. Wiley Series in Probability and Statistics, John Wiley and Sons, New York. |
| [20] |
Narayan P (2005) The saving and investment nexus for China: Evidence from cointegration tests. Appl Econ 37: 1979–1990. https://doi.org/10.1080/00036840500278103 doi: 10.1080/00036840500278103
|
| [21] | Pawlowsky-Glahn V, Egozcue JJ, Tolosana-Delgado R (2007) Lecture notes on compositional data analysis. |
| [22] |
Said SE, Dickey DA (1984) Testing for unit roots in autoregressive-moving average models of unknown order. Biometrika 71: 599–607. https://doi.org/10.1093/biomet/71.3.599 doi: 10.1093/biomet/71.3.599
|
| [23] |
Sinha D, Sinha T (1998) An exploration of the long-run relationship between saving and investment in the developing economies: A tale of latin american countries. J Post Keynesian Econ 20: 435–443. https://doi.org/10.1080/01603477.1998.11490162 doi: 10.1080/01603477.1998.11490162
|
| [24] | Thomas P, Lovell D (2014) Compositional data analysis (CoDA) approaches to distance in information retrieval. In: Geva, S., et al., The 37th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR '14, Gold Coast, QLD, Australia, 991–994. https://doi.org/10.1145/2600428.2609492 |






Figures(7) / Tables(5)

Juan David Vega Baquero, Miguel Santolino. Capital flows in integrated capital markets: MILA case[J]. Quantitative Finance and Economics, 2022, 6(4): 622-639. doi: 10.3934/QFE.2022027







 DownLoad:
DownLoad: