Systematic risk estimation is widely applied by investors and managers in order to predict risks in the market. One of the most applied measures of risk is the so-called Capital Asset Pricing Model, shortly CAPM. It has been studied empirically focusing on the impact of return interval on the betas. This paper lies in this topic and attempts to estimate the CAPM at different time scales for GCC markets by adapting a wavelet method to examine the relationship between the return of the stock and its systematic risk at different time scales. The main novelty is by applying non-uniform intervals of time. Differently from existing literature, we use random ones. The proposed procedure is acted empirically on a sample corresponding to Saudi Tadawul market as the most important GCC representative market actively traded over the period January 01, 2013 to September 20, 2018, which is characterized by many political, economic and financial movements such as Qatar embargo, Yemen war, NEOM project, 2030 KSA vision and the Arab spring effects. The findings in the present work may be good basis for understanding current and future GCC markets situation and may be thus a basis for investors' decisions in such markets.
Citation: Anouar Ben Mabrouk. Wavelet-based systematic risk estimation: application on GCC stock markets: the Saudi Arabia case[J]. Quantitative Finance and Economics, 2020, 4(4): 542-595. doi: 10.3934/QFE.2020026
Systematic risk estimation is widely applied by investors and managers in order to predict risks in the market. One of the most applied measures of risk is the so-called Capital Asset Pricing Model, shortly CAPM. It has been studied empirically focusing on the impact of return interval on the betas. This paper lies in this topic and attempts to estimate the CAPM at different time scales for GCC markets by adapting a wavelet method to examine the relationship between the return of the stock and its systematic risk at different time scales. The main novelty is by applying non-uniform intervals of time. Differently from existing literature, we use random ones. The proposed procedure is acted empirically on a sample corresponding to Saudi Tadawul market as the most important GCC representative market actively traded over the period January 01, 2013 to September 20, 2018, which is characterized by many political, economic and financial movements such as Qatar embargo, Yemen war, NEOM project, 2030 KSA vision and the Arab spring effects. The findings in the present work may be good basis for understanding current and future GCC markets situation and may be thus a basis for investors' decisions in such markets.

| [1] | Aktan B, Ozturk M, Rhaeim N, et al. (2009) Wavelet-Based Systematic Risk Estimation An Application on Istanbul Stock Exchange. Int Res J Financ Econ 23: 34-45. |
| [2] | Arfaoui S, Rezgui I, Mabrouk AB (2017) Wavelet Analysis On The Sphere, Spheroidal Wavelets, Degryuter, Degruyter, 2017, ISBN 978-3-11-048188-4. |
| [3] | Arfaoui S, Mabrouk AB, Cattani C (2020) New type of Gegenbauer-Hermite monogenic polynomials and associated Clifford wavelets. J Math Imaging Vision 62: 73-97. |
| [4] | Arfaoui S, Mabrouk AB, Cattani C (2020) New type of Gegenbauer-Jacobi-Hermite monogenic polynomials and associated continuous Clifford wavelet transform. Acta Applicandea Math. https://doi.org/10.1007/s10440-020-00322-0. |
| [5] | Aydogan K (1989) Portfolio Theory, Capital Market Board of Turkey Research Report: Ankara. |
| [6] | Banz RW (1981) The relationship between return and market value of common stock. J Financ Econ 9: 3-18. |
| [7] | Basu S (1977) The relationship between earnings' yield, market value and return for NYSE common stocks-further evidence. J Financ 32: 663-681. |
| [8] | Mabrouk AB, Mohamed MLB, Omrani K (2008) Numerical solutions for PDEs modeling binary alloy-solidification dynamics, In: Proceedings of 2007 International Symposium on Nonlinear Dynamics, J Phys, conference series 96 (2008) 012067. |
| [9] | Mabrouk AB, Kortass H, Ammou SB (2008) Wavelet Estimators for Long Memory in Stock Markets. Int J Theor Appl Financ 12: 297-317. |
| [10] | Mabrouk AB, Kahloul I, Hallara SE (2010) Wavelet-Based Prediction for Governance, Diversification and Value Creation Variables. Int Res J Financ Econ 60: 15-28. |
| [11] | Mabrouk AB, Abdallah NB, Hamrita ME (2011) A wavelet method coupled with quasi self similar stochastic processes for time series approximation. Int J Wavelets Multiresolution Inf Process 9: 685-711. |
| [12] | Mabrouk AB, Zaafrane O (2013) Wavelet Fuzzy Hybrid Model For Physico Financial Signals. J Appl Stat 40: 1453-1463. |
| [13] | Mabrouk AB, Rabbouch B, Saadaoui F (2015) A wavelet based methodology for predicting transmembrane segments, In: Poster Session, The International Conference of Engineering Sciences for Biology and Medecine, 1-3 May 2015, Monastir, Tunisie. |
| [14] | Black F, Jensen MC, Scholes M(1972) The capital asset pricing model: Some empirical tests, in Jensen MC (ed), Studies in the theory of Capital, New York: Praeger, 1-54. |
| [15] | Black F (1972) Capital Market Equilibrium with Restricted Borrowing. J Bus 45: 444-455. |
| [16] | Breeden D (1979) An Intertemporal Asset Pricing Model with Stochastic Consumption and Investment Opportunities. J Financ Econ 73: 265-296. |
| [17] | Brennan MJ (1973) Taxes, market valuation and corporate financial policy. Natl tax J 23: 417-427. |
| [18] | Chae J, Yang C (2008) Which idiosyncratic factors can explain the pricing errors from asset pricing models in the Korean stock market? Asia-Pasific J Financ Stud 37: 297-342. |
| [19] | Chan LK, Lakonishok J (1993) Are the reports of beta's death premature? J Portf Manage 19: 51-62. |
| [20] | Cifter A, Ozun A (2007) Multiscale systematic risk: An application on ISE 30, MPRA Paper 2484, University Library of Munich: Germany. |
| [21] | Cifter A, Ozun A (2008) A signal processing model for time series analysis: The effect of international F/X markets on domestic currencies using wavelet networks. Int Rev Electr Eng 3: 580-591. |
| [22] | Cohen K, Hawawin G, Mayer S, et al. (1986) The Microstructure of Securities Markets, Prentice-Hall: Sydney. |
| [23] | Conlon T, Crane M, Ruskin HJ (2008) Wavelet multiscale analysis for hedge funds: Scaling and strategies. Phys A 387: 5197-5204. |
| [24] | Daubechies I (1992) Ten Lectures on Wavelets, Society for Industrial and Applied Mathematics, Philadelphia. |
| [25] | Desmoulins-Lebeault F (2003) Distribution of Returns and the CAPM Empirical Problems. Post-Print halshs-00165099, HAL. |
| [26] | DiSario R, Saroglu H, McCarthy J, et al. (2008) Long memory in the volatility of an emerging equity market: The case of Turkey. Int Mark Inst Money 18: 305-312. |
| [27] | Fama EF (1970) Efficient capital markets: A review of theory and empirical work. J Financ 25: 383-417. |
| [28] | Fama E, French K (1992) The Cross-section of Expected Stock Returns. J Financ 47: 427-465. |
| [29] | Fama E, French K (1993) Common risk factors in returns on stocks and bonds. J Financ Econ 33: 3-56. |
| [30] | Fama E, French KR (1996) The CAPM is Wanted, Dead or Alive. J Financ 51: 1947-1958. |
| [31] | Fama E, French KR (2004) The Capital Asset Pricing Model: Theory and Evidence. J Econo Perspect 18: 25-46. |
| [32] | Fama E, French KR (2006) The Value Premium and the CAPM. J Financ 61: 2163-2185. |
| [33] | Fama E, MacBeth J (1973) Risk, return and equilibrium: Empirical tests. J Polit Econ 81: 607-636. |
| [34] | Fernandez V (2006) The CAPM and value at risk at different time-scales. Int Rev Financ Anal 15: 203-219. |
| [35] | Friend L, Landskroner Y, Losq E (1976) The demand for risky assets and uncertain inflation. J Financ 31: 1287-1297. |
| [36] | Galagedera DUA (2007) A review of capital asset pricing models. Managerial Financ 33: 821-832. |
| [37] | Gençay R, Selçuk F, Whitcher B (2002) An Introduction to Wavelets and Other Filtering Methods in Finance and Economics, Academic Press, San Diego. |
| [38] | Gençay R, Whitcher B, Selçuk F (2003) Systematic Risk and Time Scales. Quant Financ 3: 108-116. |
| [39] | Gençay R, Whitcher B, Selçuk F (2005) Multiscale systematic risk. J Inte Money Financ 24: 55-70. |
| [40] | Gibbons MR (1982) Multivariate tests of financial models: A new approach. J Financ Econ 10: 3-27. |
| [41] | Gursoy CT, Rejepova G (2007) Test of capital asset pricing model in Turkey. J Dogus Univ 8: 47-58. |
| [42] | Handa P, Kothari SP, Wasley C (1989) The relation between the return interval and beta: Implications for size-effect. J Financ Econ 23: 79-100. |
| [43] | Handa P, Kothari SP, Wasley C (1993) Sensitivity of multivariate tests of the CAPM to the return measurement interval. J Financ 48: 1543-1551. |
| [44] | Ho YW, Strange R, Piesse J (2000) CAPM anomalies and the pricing of equity: Evidence from the Hong Kong market. Appl Econ 32: 1629-1636. |
| [45] | Hubbard BB (1998) The world according to wavelets: The story of a mathematical technique in the making, 2e, Ak Peters Ltd., MA. |
| [46] | Mahmoud IMM, Ben Mabrouk A, Hashim MHA (2016) Wavelet multifractal models for transmembrane proteins' series. Int J Wavelets Multires Inf Process 14: 36. |
| [47] | In F, Kim S (2006) The hedge ratio and the empirical relationship between the stock and futures markets: A new approach using wavelet analysis. J Bus 79: 799-820. |
| [48] | In F, Kim S (2007) A note on the relationship between Fama-French risk factors and innovations of ICAPM state variables. Financ Res Lett 4: 165-171. |
| [49] | In F, Kim S, Marisetty V, et al. (2008) Analysing the performance of managed funds using the wavelet multiscaling method. Rev Quant Financ Accounting 31: 55-70. |
| [50] | Karan MB, Karadagli E (2001) Risk return and market equilibrium in Istanbul stock exchange: The test of the capital asset pricing model. J Econ Administrative Sci 19: 165-177. |
| [51] | Kishor NK, Marfatia HA (2013) The time-varying response of foreign stock markets to US monetary policy surprises: Evidence from the Federal funds futures market. J Int Financ Mark Inst Money 24: 1-24. |
| [52] | Kothari S, Shanken J (1998) On defense of beta, J. Stern, and D. Chew, Jr. (Eds.), The Revolution in Corporate Finance, 3e, Blackwell Publishers Inc., 52-57. |
| [53] | Levhari D, Levy H (1977) The Capital Asset Pricing Model and the Investment Horizon. Rev Econ Stat 59: 92-104. |
| [54] | Lévy H (1978) Equilibrium in an imperfect market: a constraint on the number of securities in the portfolio. Am Econ Rev 68: 643-658. |
| [55] | Lintner J (1965a) Security Prices and Maximal Gaines from Diversification. J Financ 20: 587-615. |
| [56] | Lintner J (1965b) The Valuation of Risk Assets and the Selection of Risky Investments in Stock Portfolios and Capital Budgets. Rev Econ Stat 47: 13-37. |
| [57] | Litzenberger RH, Ramaswamy K (1979) The effect of personal taxes and dividends on capital asset prices: Theory and empirical evidence. J Financ Econ 7: 163-195. |
| [58] | Magni CA (2007a) Project selection and equivalent CAPM-based investment criteria. Appl Financ Econ Lett 3: 165-168. |
| [59] | Magni CA (2007b) Project valuation and investment decisions: CAPM versus arbitrage. Appl Financ Econ Lett 3: 137-140. |
| [60] | Marfatia HA (2014) Impact of uncertainty on high frequency response of the US stock markets to the Fed's policy surprises. Q Rev Econ Financ 54: 382-392. |
| [61] | Marfatia HA (2015) Monetary policy's time-varying impact on the US bond markets: Role of financial stress and risks. North Am J Econ Financ 34: 103-123. |
| [62] | Marfatia HA (2017a) A fresh look at integration of risks in the international stock markets: A wavelet approach. Rev Financ Econ 34: 33-49. |
| [63] | Marfatia HA (2017b) Wavelet Linkages of Global Housing Markets and macroeconomy. Available at SSRN 3169424. |
| [64] | Marfatia HA (2020) Investors' Risk Perceptions in the US and Global Stock Market Integration. Res Int Bus Financ 52: 101169. |
| [65] | Markowitz H (1952) Portfolio Selection. J Financ 7: 77-91. |
| [66] | Merton RC (1973) An Intertermporal Capital Asset Pricing Model. Econometrica: J Econometric Society 41: 867-887. |
| [67] | Mossin I (1966) Equilibrium in a Capital Asset Market. Econometrica: J Econometric Society 34: 768-783. |
| [68] | Perold A (2004) The Capital Asset Pricing Model. J Econ Perspect 18: 3-24. |
| [69] | Percival DB, Walden AT (2000) Wavelet methods for time series analysis, Camridge University Press, NY. |
| [70] | Rhaiem R, Ammou SB, Mabrouk AB (2007a) Estimation of the systematic risk at different time scales: Application to French stock market. Int J Appl Econ Financ 1: 79-87. |
| [71] | Rhaiem R, Ammou SB, Mabrouk AB (2007b) Wavelet estimation of systematic risk at different time scales, Application to French stock markets. Int J Appl Econ Financ 1: 113-119. |
| [72] | Roll R (1977) A critique of the asset pricing theory's tests Part I: On past and potential testability of the theory. J Financ Econ 4: 129-176. |
| [73] | Selcuk F (2005) Wavelets: A new analysis method (in Turkish). Bilkent J 3: 12-14. |
| [74] | Sharkasi A, Crane M, Ruskin HJ, et al.(2006) The reaction of stock markets to crashes and events: A comparison study between emerging and mature markets using wavelet transforms. Phys A 368: 511-521. |
| [75] | Sharpe WF (1964) Capital asset prices: A theory of market equilibrium under conditions of risk. J Financ 19: 425-442. |
| [76] | Sharpe WF (1970a) Computer-Assisted Economics. J Financ Quant Anal, 353-366. |
| [77] | Sharpe WF (1970b) Stock market price behavior. A discussion. J Financ 25: 418-420. |
| [78] | Sharpe WF (1970c) Portfolio theory and capital markets, McGraw-Hill College. |
| [79] | Soltani S (2002) On the use of the wavelet decomposition for time series prediction. Neurocomput 48: 267-277. |
| [80] | Soltani S, Modarres R, Eslamian SS (2007) The use of time series modeling for the determination of rainfall climates of Iran. Int J Climatol 27: 819-829. |
| [81] | Vasichek AA, McQuown JA (1972) Le modèle de marché efficace. Analyse financière, 15, 1973, traduit de "The effecient market model". Financ Anal J. |
| [82] | Xiong X, Zhang X, Zhang W, et al. (2005) Wavelet-based beta estimation of China stock market, In: Proceedings of 4th International Conference on Machine Learning and Cybernetic, Guangzhou. IEEE: 0-7803-9091-1. |
| [83] | Yamada H (2005) Wavelet-based beta estimation and Japanese industrial stock prices. Appl Econ Lett 12: 85-88. |
| [84] | Zemni M, Jallouli M, Mabrouk AB, et al. (2019a) Explicit Haar-Schauder multiwavelet filters and algorithms. Part II: Relative entropy-based estimation for optimal modeling of biomedical signals. Int J Wavelets Multiresolution Inf Process 17: 1950038. |
| [85] | Zemni M, Jallouli M, Mabrouk AB, et al. (2019b) ECG Signal Processing with Haar-Schauder Multiwavelet, In: Proceedings of the 9th International Conference on Information Systems and Technologies—Icist 2019. |
 QFE-04-04-026-s001.pdf QFE-04-04-026-s001.pdf |
 |
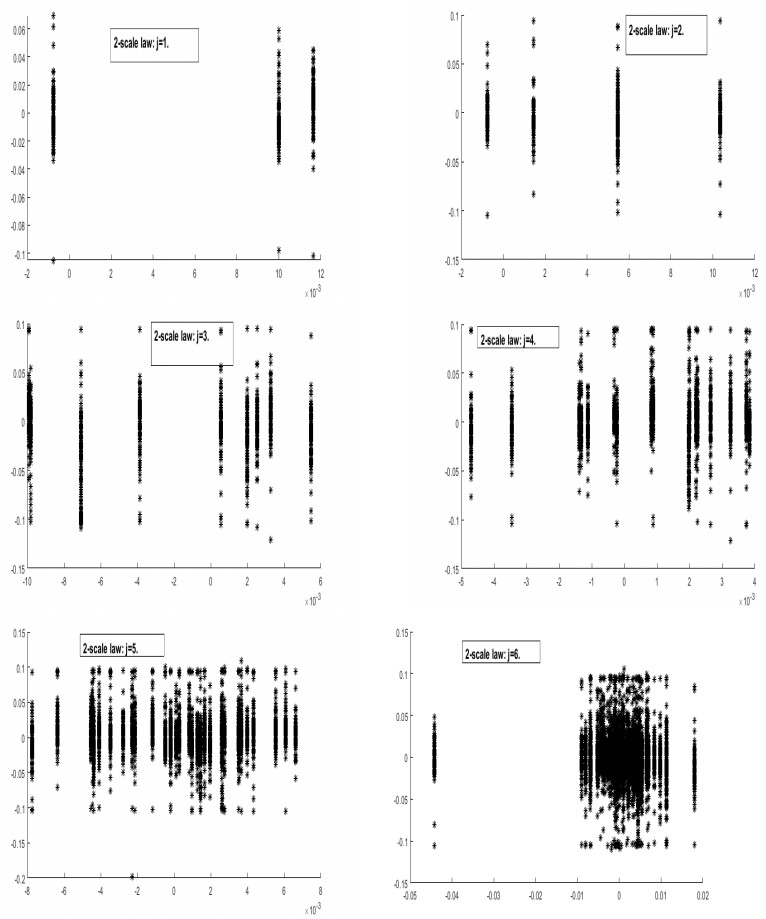
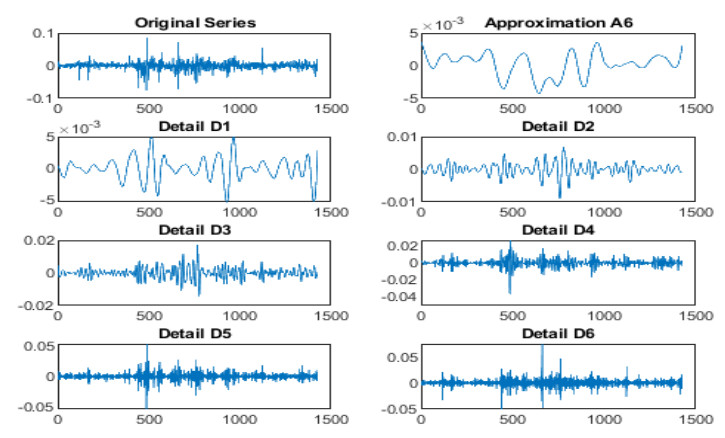
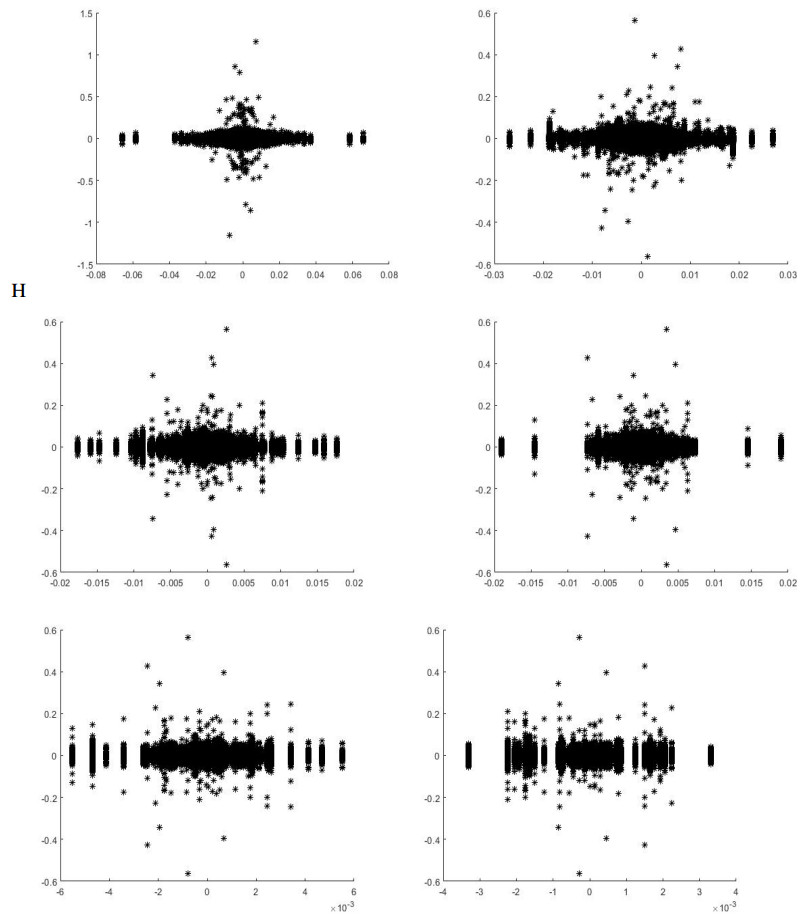
Figures(3) / Tables(9)

Anouar Ben Mabrouk. Wavelet-based systematic risk estimation: application on GCC stock markets: the Saudi Arabia case[J]. Quantitative Finance and Economics, 2020, 4(4): 542-595. doi: 10.3934/QFE.2020026







 DownLoad:
DownLoad: