Citation: H. T. Banks, John E. Banks, Jared Catenacci, Michele Joyner, John Stark. Correctly modeling plant-insect-herbivore-pesticide interactions as aggregate data[J]. Mathematical Biosciences and Engineering, 2020, 17(2): 1743-1756. doi: 10.3934/mbe.2020091

| [1] | B. M. Adams, H. T. Banks, J. E. Banks, J. D. Stark, Population dynamics models in plant-insectherbivore-pesticide interactions, Math. Biosci., 196 (2005), 39-64. |
| [2] | J. E. Banks, J. D. Stark, Aphid response to vegetation diversity and insecticide disturbance, Agric. Ecosyst. Environ., 103 (2004), 595-599. |
| [3] | H. T. Banks, A Functional Analysis Framework for Modeling, Estimation and Control in Science and Engineering, Taylor and Frances Publishing, CRC Press, Boca Raton, FL, 2012. Secs 1.3, 1.4, and 14.4. |
| [4] | H. T. Banks, S. Hu, W. C. Thompson, Modeling and Inverse Problems in the Presence of Uncertainty, Taylor and Frances Publishing, CRC Press, Boca Raton, FL, 2014. Chapter 5. |
| [5] | J. E. Banks, The scale of landscape fragmentation affects herbivore response to vegetation heterogeneity, Oecologia, 117 (1998), 239-246. |
| [6] | J. E. Banks, Effects of weedy field margins on Myzus persicae (Hemiptera: Aphididae) in a broccoli agroecosystem, Pan-Pac. Entomol., 76 (2000), 95-101. |
| [7] | H. T.Banks, J. E. Banks, J. Catenacci, M. L. Joyner, J. D. Stark, Comparison of dynamic models for plant-insect herbivore-pesticide interactions CRSC-TR19-11, Center for Research in Scientific Computation, N. C. State University, Raleigh, NC, July, 2019. |
| [8] | H. T. Banks, J. E. Banks, N. Murad, J. A Rosenheim, K. Tillman, Modelling pesticide treatment effects on Lygus hesperus in cotton fields, Proceedings, 27 th IFIP TC7 Conference 2015 on System Modelling and Optimization, L. Bociu et al (Eds.) CSMO 2015 IFIP AICT 494, p.1-12, 2017, Springer. |
| [9] | H. T. Banks, J. Catenacci, Aggregate data and the Prohorov Metric Framework: Efficient gradient computation, CRSC-TR15-13, Center for Research in Scientific Computation, N. C. State University, Raleigh, NC, November, 2015; Appl. Math. Lett., 56 (2016), 1-9. |
| [10] | H. T. Banks, Jared Catenacci and Shuhua Hu, Asymptotic properties of probability measure estimators in a nonparametric model, CRSC TR14-05, N. C. State University, Raleigh, NC, May, 2014; SIAM/ASA J. Uncertain., 3 (2015), 417-433. |
| [11] | H. T. Banks, K. B. Flores, I. G. Rosen, E. M. Rutter, M. Sirlanci, W. C. Thompson, The Prohorov Metric Framework and aggregate data inverse problems for random PDEs, Commun. Appl. Anal., 22 (2018), 415-446. |
| [12] | H. T. Banks, W. C. Thompson, Least squares estimation of probability measures in the Prohorov Metric Framework, CRSC-TR12-21, N. C. State University, Raleigh, NC, November, 2012. |
| [13] | H. T. Banks, W. C. Thompson, Existence and consistency of a nonparametric estimator of probability measures in the Prohorov metric framework, Int. J. Pure Appl. Math., 103 (2015), 819-843. |
| [14] | H. T. Banks, W. C. Thompson, Random delay differential equations and inverse problems for aggregate data problems, Eurasian J. Math. Computer Appl., 6 (2018), 4-16. |
| [15] | W. E. Boyce, R. C. DiPrima, Elementary Differential Equations and Boundary Value Problems, John Wiley and Sons,Inc., 1997, 6th edition, New York. |
| [16] | H. T. Banks, K. L. Bihari, Modeling and estimating uncertainty in parameter estimation, Inverse Probl., 17 (2001), 95-111. |
| [17] | L. K. Potter, Physiologically based pharmacokinetic models for the systemic transport of trichloroethylene, Ph. D. thesis, North Carolina State University, 2001, www.lib.ncsu.edu. |
| [18] | H. T. Banks, D. M. Bortz, G. A. Pinter, L. K. Potter, Modeling and imaging techniques with potential for application in bioterrorism, Chapter 6 in Bioterrorism: Mathematical Modeling Applications in Homeland Security, (H.T. Banks and C. Castillo-Chavez, eds.), Frontiers in Applied Math, FR28, SIAM, 2003, Philadelphia, PA, 129-154. |
| [19] | H. T. Banks, J. L. Davis, A comparison of approximation methods for the estimation of probability distributions on parameters, Appl. Numer. Math., 57 (2007), 753-777. |
| [20] | H. T. Banks, J. L. Davis, Quantifying uncertainty in the estimation of probability distributions, Math. Biosci. Eng., 5, (2008), 647-667. |
| [21] | H. T. Banks, B. G. Fitzpatrick, Estimation of growth rate distributions in size-structured population models, Q. Appl. Math., 49 (1991), 215-235. |
| [22] | H. T. Banks, B. G. Fitzpatrick, L. K. Potter, Y. Zhang, Estimation of probability distributions for individual parameters using aggregate population data, In Stochastic Analysis, Control, Optimization and Applications, (W. McEneaney, G. Yin and Q. Zhang, eds.), Birkhauser, 1989, Boston. |
| [23] | P. Billingsley, Convergence of Probability Measures, Wiley, New York,1968. |
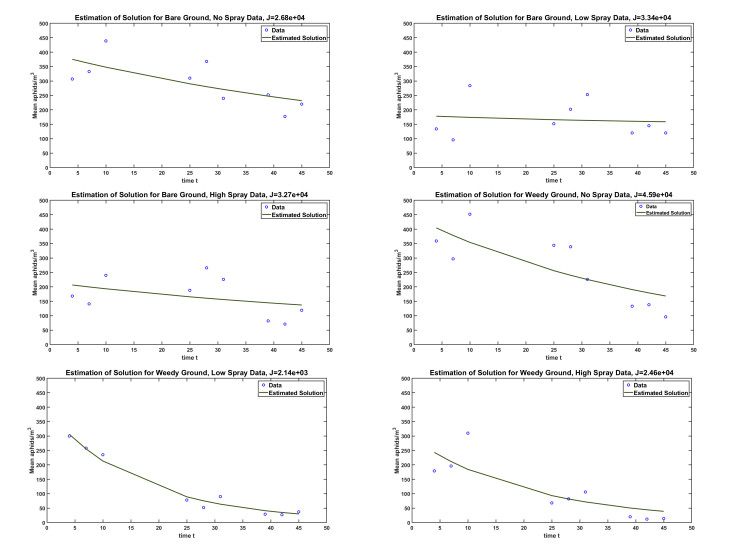
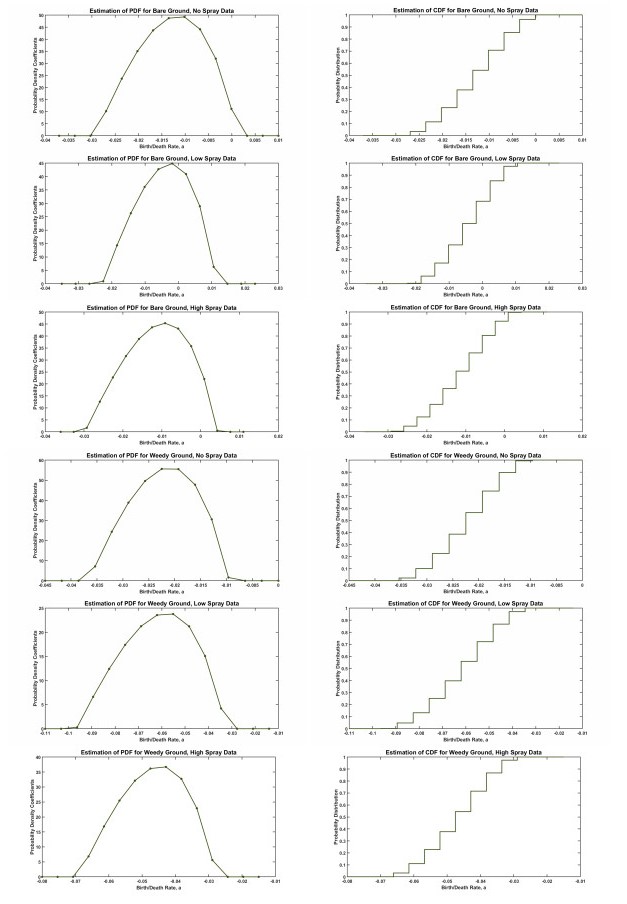
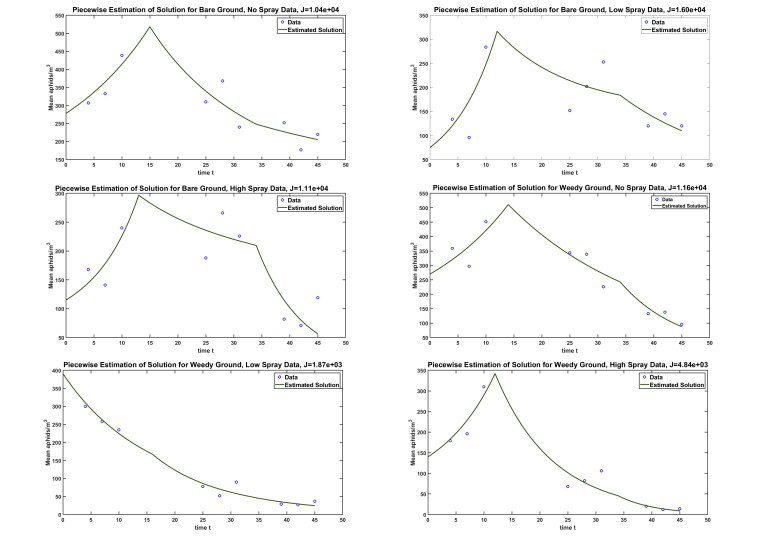
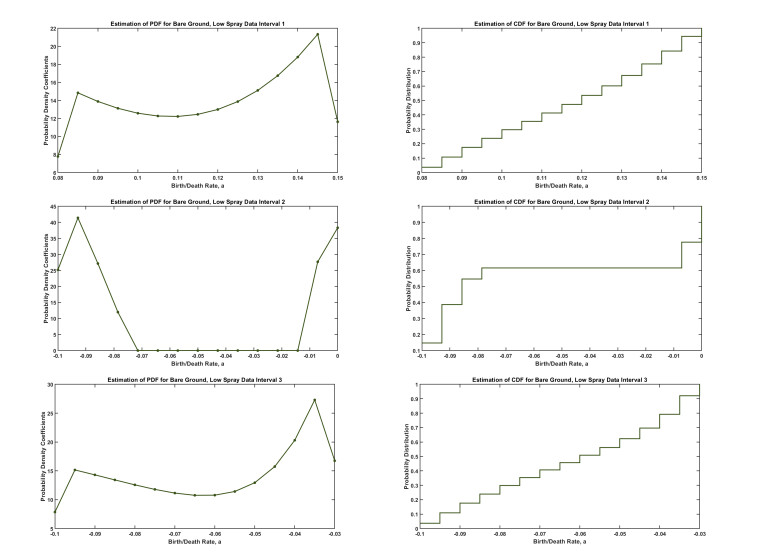
Figures(5) / Tables(1)

H. T. Banks, John E. Banks, Jared Catenacci, Michele Joyner, John Stark. Correctly modeling plant-insect-herbivore-pesticide interactions as aggregate data[J]. Mathematical Biosciences and Engineering, 2020, 17(2): 1743-1756. doi: 10.3934/mbe.2020091







 DownLoad:
DownLoad: