Random forests are notable learning algorithms introduced by Breiman in 2001. They are widely used for classification and regression tasks and their mathematical properties are under ongoing research. We consider a specific class of random forest algorithms related to kernel methods, the so-called Kernel Random Forests (KeRF). In particular, we investigate thoroughly two explicit algorithms, designed independently of the data set, the centered KeRF and the uniform KeRF. In the present article, we provide an improvement in the rate of convergence for both algorithms and we explore the related reproducing kernel Hilbert space defined by the explicit kernel of the centered random forest.
Citation: Iakovidis Isidoros, Nicola Arcozzi. Improved convergence rates for some kernel random forest algorithms[J]. Mathematics in Engineering, 2024, 6(2): 305-338. doi: 10.3934/mine.2024013
Random forests are notable learning algorithms introduced by Breiman in 2001. They are widely used for classification and regression tasks and their mathematical properties are under ongoing research. We consider a specific class of random forest algorithms related to kernel methods, the so-called Kernel Random Forests (KeRF). In particular, we investigate thoroughly two explicit algorithms, designed independently of the data set, the centered KeRF and the uniform KeRF. In the present article, we provide an improvement in the rate of convergence for both algorithms and we explore the related reproducing kernel Hilbert space defined by the explicit kernel of the centered random forest.

| [1] | J. Agler, J. E. McCarthy, Pick interpolation and Hilbert function spaces, 2002. |
| [2] |
Y. Amit, D. Geman, Shape quantization and recognition with randomized trees, Neural Comput., 9 (1997), 1545–1588. https://doi.org/10.1162/neco.1997.9.7.1545 doi: 10.1162/neco.1997.9.7.1545

|
| [3] | L. Arnould, C. Boyer, E. Scornet, Is interpolation benign for random forest regression? Proceedings of The 26th International Conference on Artificial Intelligence and Statistics, 206 (2023), 5493–5548. |
| [4] | N. Aronszajn, Theory of reproducing kernels, Trans. Amer. Math. Soc., 68 (1950), 337–404. |
| [5] | G. Biau, Analysis of a random forests model, J. Mach. Learn. Res., 13 (2012), 1063–1095. |
| [6] |
G. Biau, L. Devroye, On the layered nearest neighbour estimate, the bagged nearest neighbour estimate and the random forest method in regression and classification, J. Multivariate Anal., 101 (2010), 2499–2518. https://doi.org/10.1016/j.jmva.2010.06.019 doi: 10.1016/j.jmva.2010.06.019
|
| [7] | G. Biau, L. Devroye, G. Lugosi, Consistency of random forests and other averaging classifiers, J. Mach. Learn. Res., 9 (2008), 2015–2033. |
| [8] |
G. Biau, E. Scornet, A random forest guided tour, TEST, 25 (2016), 197–227. https://doi.org/10.1007/s11749-016-0481-7 doi: 10.1007/s11749-016-0481-7
|
| [9] | S. Boucheron, G. Lugosi, P. Massart, Concentration inequalities: a nonasymptotic theory of independence, Oxford University Press, 2013. |
| [10] |
A. Boulesteix, S. Janitza, J. Kruppa, I. R. König, Overview of random forest methodology and practical guidance with emphasis on computational biology and bioinformatics, Wiley Interdiscip. Rev.: Data Min. Knowl. Discovery, 2 (2012), 493–507. https://doi.org/10.1002/widm.1072 doi: 10.1002/widm.1072
|
| [11] | L. Breiman, Some infinity theory for predictor ensembles, Technical Report 579, Statistics Dept. UCB, 2000. |
| [12] |
L. Breiman, Random forests, Mach. Learn., 45 (2001), 5–32. https://doi.org/10.1023/A:1010933404324 doi: 10.1023/A:1010933404324
|
| [13] | L. Breiman, J. H. Friedman, R. A. Olshen, C. J. Stone, Classification and regression trees, 1 Ed., New York: Chapman and Hall/CRC, 1984. https://doi.org/10.1201/9781315139470 |
| [14] | M. Denil, D. Matheson, N. Freitas, Consistency of online random forests, Proceedings of the 30th International Conference on Machine Learning, Atlanta, Georgia, 2013, 1256–1264. |
| [15] | D. J. Dittman, T. M. Khoshgoftaar, A. Napolitano, The effect of data sampling when using random forest on imbalanced bioinformatics data, 2015 IEEE International Conference on Information Reuse and Integration, IEEE, 2015,457–463. https://doi.org/10.1109/IRI.2015.76 |
| [16] | R. Genuer, J. M. Poggi, C. Tuleau, Random forests: some methodological insights, arXiv, 2008. https://doi.org/10.48550/arXiv.0811.3619 |
| [17] |
P. Geurts, D. Ernst, L. Wehenkel, Extremely randomized trees, Mach. Learn., 63 (2006), 3–42. https://doi.org/10.1007/s10994-006-6226-1 doi: 10.1007/s10994-006-6226-1
|
| [18] |
S. T. Gries, On classification trees and random forests in corpus linguistics: some words of caution and suggestions for improvement, Corpus Linguist. Ling. Theory, 16 (2019), 617–647. https://doi.org/10.1515/cllt-2018-0078 doi: 10.1515/cllt-2018-0078
|
| [19] | T. K. Ho, Random decision forests, Proceedings of 3rd International Conference on Document Analysis and Recognition, IEEE, 1 (1995), 278–282. https://doi.org/10.1109/ICDAR.1995.598994 |
| [20] | J. M. Klusowski, Sharp analysis of a simple model for random forests, Proceedings of The 24th International Conference on Artificial Intelligence and Statistics, 130 (2021), 757–765. |
| [21] | A. Liaw, M. Wiener, Classification and regression by randomForest, R News, 2 (2002), 18–22. |
| [22] |
Y. Lin, Y. Jeon, Random forests and adaptive nearest neighbors, J. Amer. Stat. Assoc., 101 (2006), 578–590. https://doi.org/10.1198/016214505000001230 doi: 10.1198/016214505000001230
|
| [23] | L. K. Mentch, G. Hooker, Ensemble trees and CLTs: statistical inference for supervised learning, arXiv, 2014. https://doi.org/10.48550/arXiv.1404.6473 |
| [24] | W. Rudin, Fourier analysis on groups, Courier Dover Publications, 2017. |
| [25] |
E. Scornet, On the asymptotics of random forests, J. Multivariate Anal., 146 (2016), 72–83. https://doi.org/10.1016/j.jmva.2015.06.009 doi: 10.1016/j.jmva.2015.06.009
|
| [26] |
E. Scornet, Random forests and kernel methods, IEEE Trans. Inf. Theory, 62 (2016), 1485–1500. https://doi.org/10.1109/TIT.2016.2514489 doi: 10.1109/TIT.2016.2514489
|
| [27] |
E. Scornet, G. Biau, J. P. Vert, Consistency of random forests, Ann. Statist., 43 (2015), 1716–1741. https://doi.org/10.1214/15-AOS1321 doi: 10.1214/15-AOS1321
|
| [28] | S. Wager, Asymptotic theory for random forests, arXiv, 2014. https://doi.org/10.48550/arXiv.1405.0352 |
| [29] | Y. Yang, A. Barron, Information-theoretic determination of minimax rates of convergence, Ann. Statist., 27 (1999), 1564–1599. |
| [30] |
J. Yoon, Forecasting of real GDP growth using machine learning models: gradient boosting and random forest approach, Comput. Econ., 57 (2021), 247–265. https://doi.org/10.1007/s10614-020-10054-w doi: 10.1007/s10614-020-10054-w
|
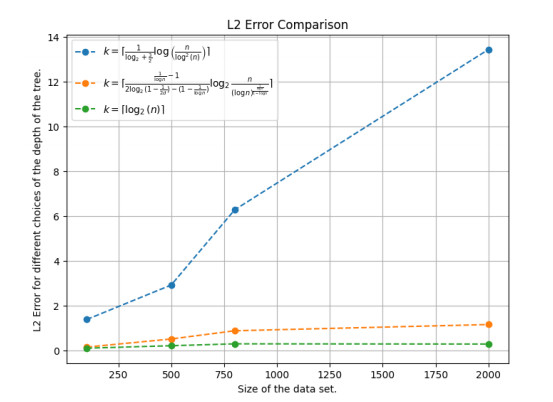
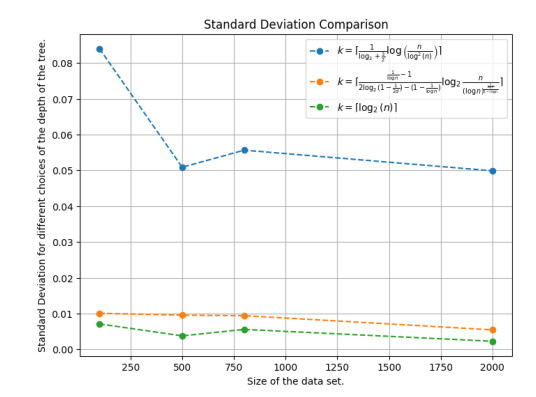
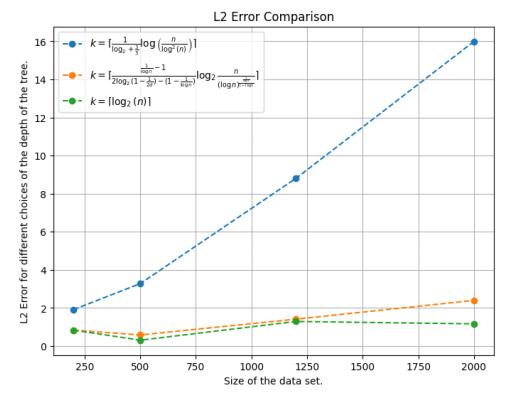
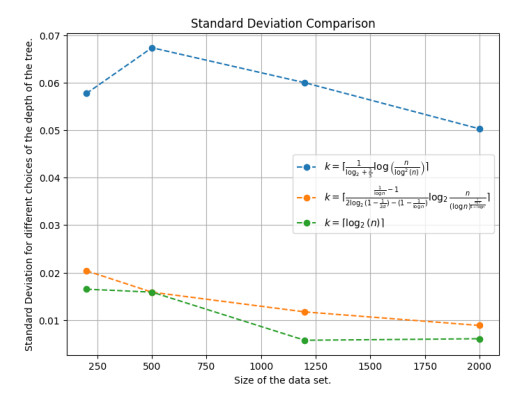
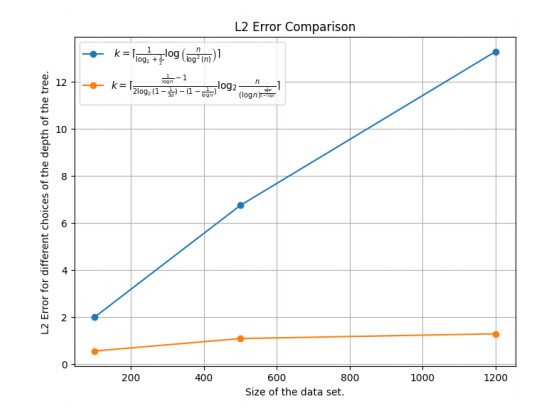
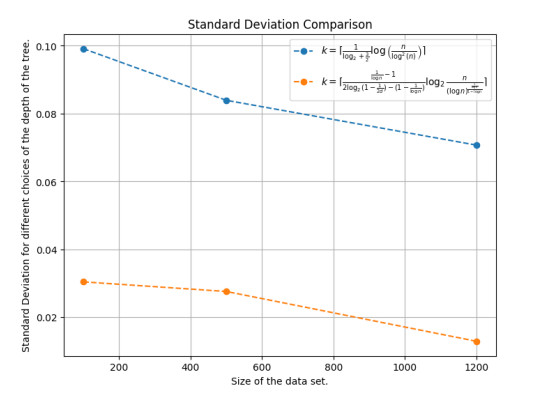
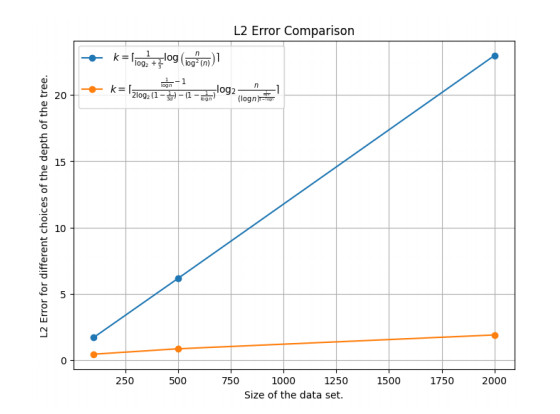
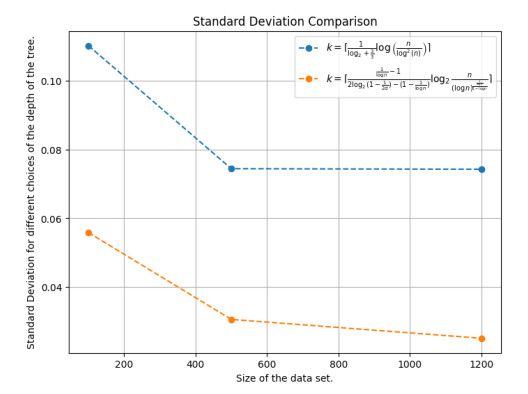
Figures(12)

Iakovidis Isidoros, Nicola Arcozzi. Improved convergence rates for some kernel random forest algorithms[J]. Mathematics in Engineering, 2024, 6(2): 305-338. doi: 10.3934/mine.2024013







 DownLoad:
DownLoad: