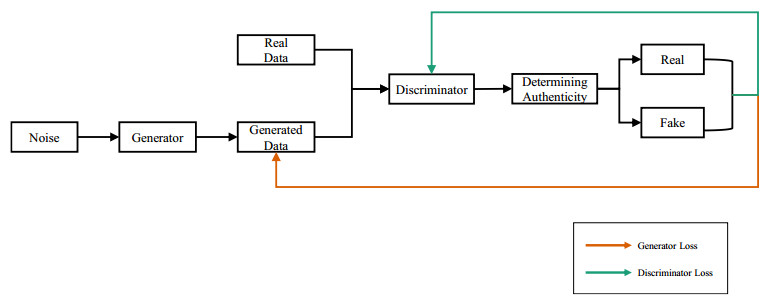
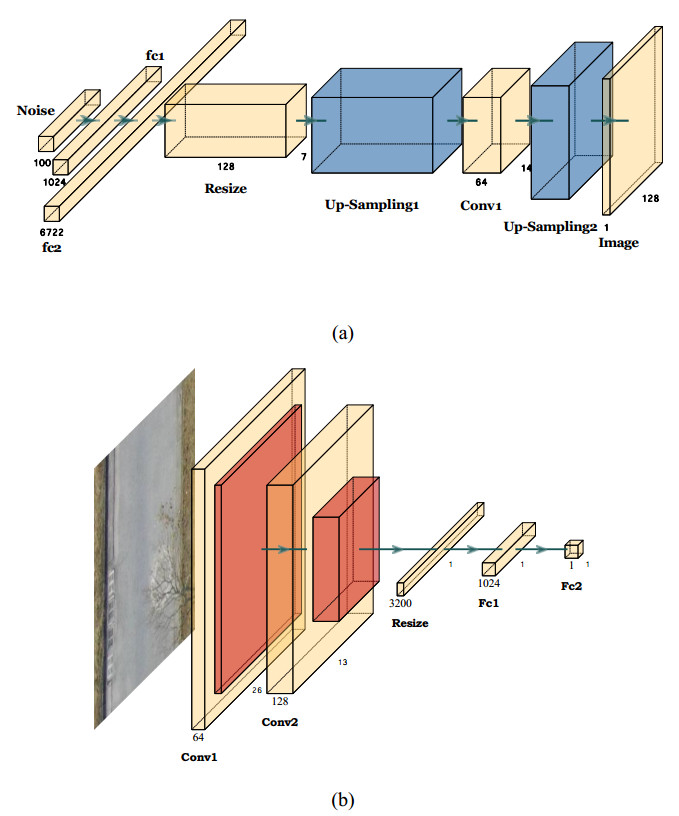
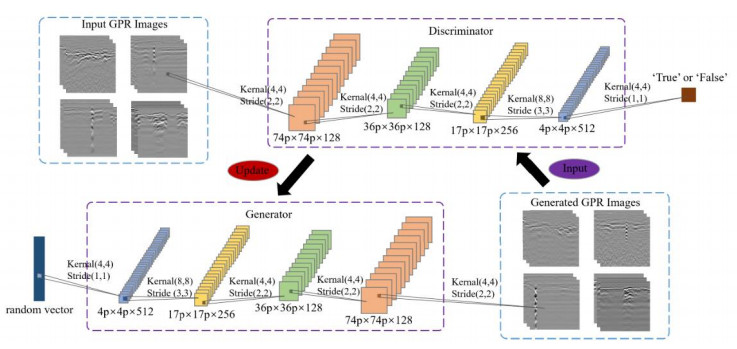
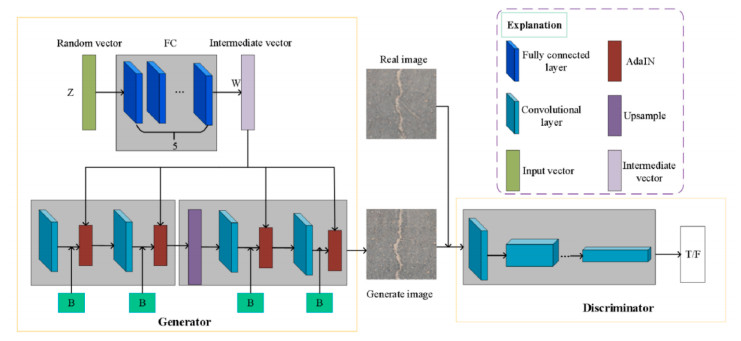
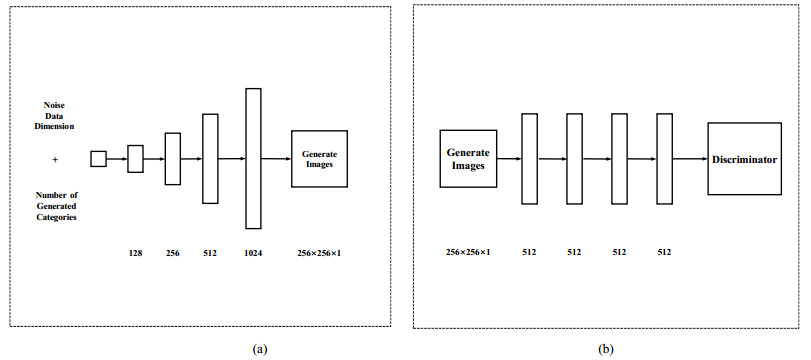
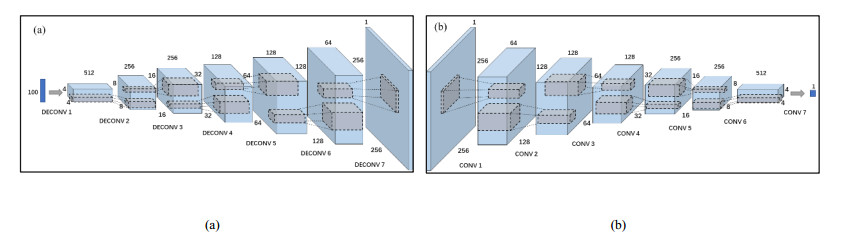
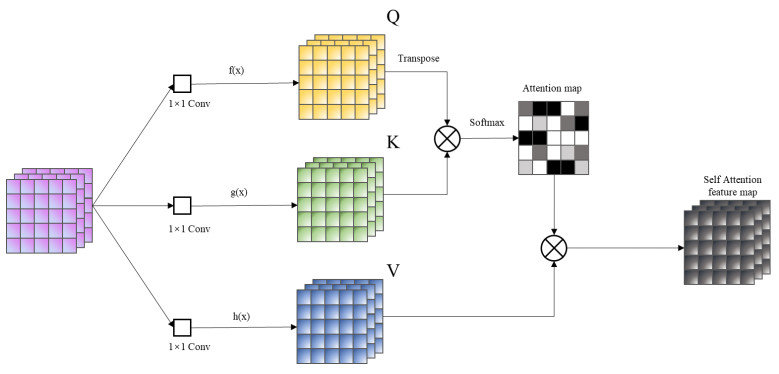
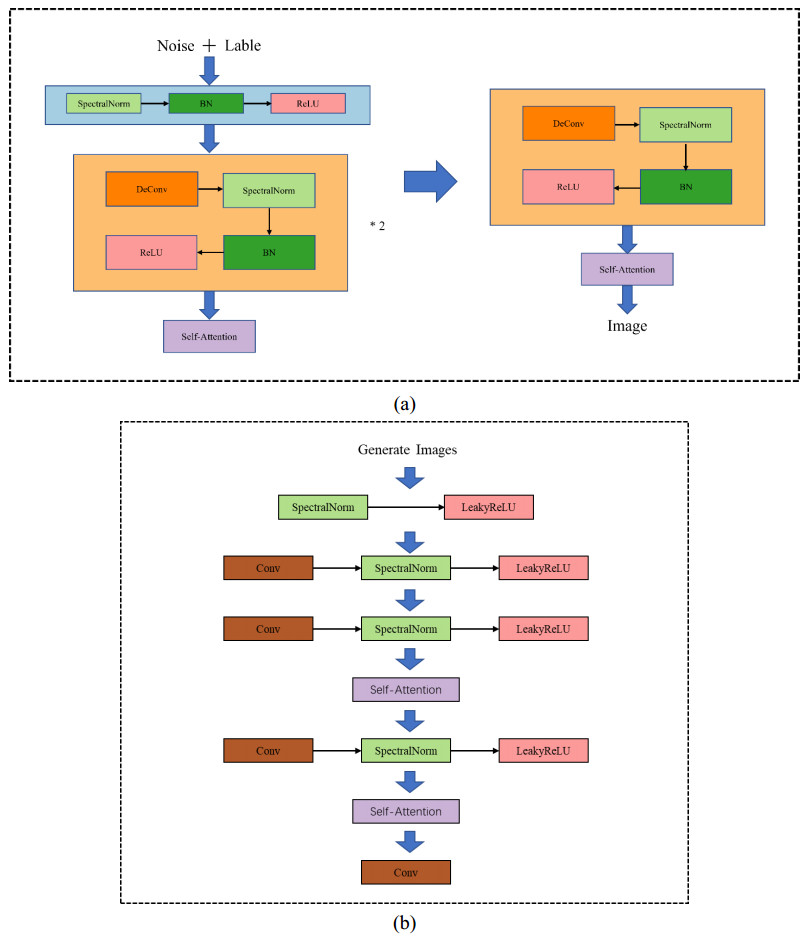
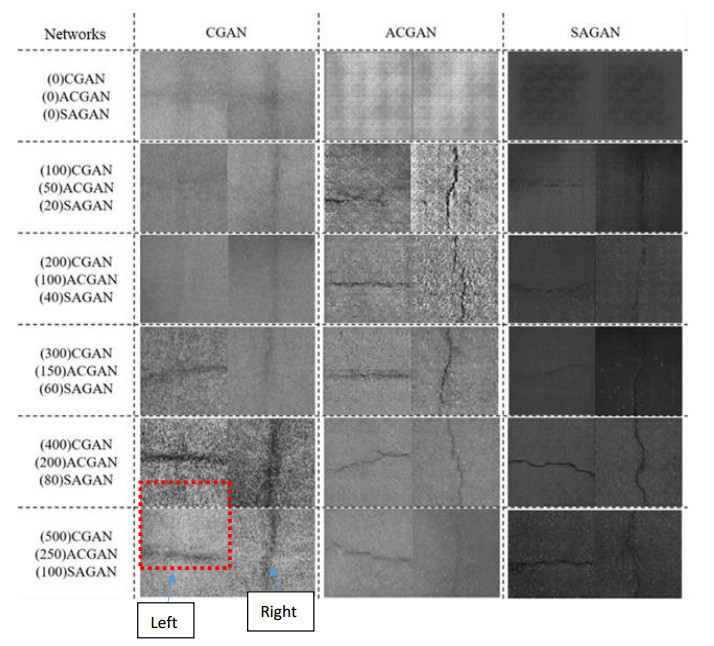
A Generative Adversarial Network (GAN) based asphalt pavement crack image generation method was proposed to improve the dataset size of the road images. Five open-source road crack datasets were leveraged to construct an image dataset, which contained two labels - transverse cracks and longitudinal cracks. The constructed dataset was used to facilitate crack detection and classification research by providing a diverse collection of labeled crack images derived from multiple public sources. The network structure of fully connected, convolutional and attention mechanisms based on the Conditional Generative Adversarial Network (CGAN) was used in this project. The purpose of this study was to train a generative model on selected categories of input pavement crack images and generate realistic crack images of those categories. We aim to tune the parameters of the GAN and optimize hyperparameters to improve the realism possibility of generated images. It also explored the generated images with different sizes and evaluated the performance of networks with different architectures. In particular, we analyzed the structural characteristics of conditional GAN. Results demonstrated that the Self-Attention Generative Adversarial Networks (SAGAN) model, which combines self-attention mechanisms with CGAN, can effectively address challenges related to limited crack image data and the inability to selectively generate images from specific categories. By conditioning the generator on category information, the SAGAN model was able to generate high-quality images while focusing on the target categories. Overall, the self-attention and conditional aspects of the SAGAN framework helped improve the generation of realistic pavement crack images.
Citation: Hui Yao, Yuhan Wu, Shuo Liu, Yanhao Liu, Hua Xie. A pavement crack synthesis method based on conditional generative adversarial networks[J]. Mathematical Biosciences and Engineering, 2024, 21(1): 903-923. doi: 10.3934/mbe.2024038
A Generative Adversarial Network (GAN) based asphalt pavement crack image generation method was proposed to improve the dataset size of the road images. Five open-source road crack datasets were leveraged to construct an image dataset, which contained two labels - transverse cracks and longitudinal cracks. The constructed dataset was used to facilitate crack detection and classification research by providing a diverse collection of labeled crack images derived from multiple public sources. The network structure of fully connected, convolutional and attention mechanisms based on the Conditional Generative Adversarial Network (CGAN) was used in this project. The purpose of this study was to train a generative model on selected categories of input pavement crack images and generate realistic crack images of those categories. We aim to tune the parameters of the GAN and optimize hyperparameters to improve the realism possibility of generated images. It also explored the generated images with different sizes and evaluated the performance of networks with different architectures. In particular, we analyzed the structural characteristics of conditional GAN. Results demonstrated that the Self-Attention Generative Adversarial Networks (SAGAN) model, which combines self-attention mechanisms with CGAN, can effectively address challenges related to limited crack image data and the inability to selectively generate images from specific categories. By conditioning the generator on category information, the SAGAN model was able to generate high-quality images while focusing on the target categories. Overall, the self-attention and conditional aspects of the SAGAN framework helped improve the generation of realistic pavement crack images.

| [1] | X. Guan, H. Zhang, X. Du, X. Zhang, M. Sun, Y. Bi, Optimization for asphalt pavement maintenance plans at network level: Integrating maintenance funds, pavement performance, road users, and environment, Appl. Sci., 13 (2023), 8842. https://doi.org/10.3390/app13158842 |
| [2] |
Y. Du, N. Pan, Z. Xu, F. Deng, Y. Shen, H. Kang, Pavement distress detection and classification based on YOLO network, Int. J. Pavement Eng., 22 (2021), 1659–1672. https://doi.org/10.1080/10298436.2020.1714047 doi: 10.1080/10298436.2020.1714047

|
| [3] |
J. Zhu, J. Zhong, T. Ma, X. Huang, W. Zhang, Y. Zhou, Pavement distress detection using convolutional neural networks with images captured via UAV, Autom. Constr., 133 (2022), 103991. https://doi.org/10.1016/j.autcon.2021.103991 doi: 10.1016/j.autcon.2021.103991
|
| [4] |
E. Ibragimov, H. J. Lee, J. J. Lee, N. Kim, Automated pavement distress detection using region based convolutional neural networks, Int. J. Pavement Eng., 23 (2022), 1981–1992. https://doi.org/10.1080/10298436.2020.1833204 doi: 10.1080/10298436.2020.1833204
|
| [5] |
J. Guan, X. Yang, L. Ding, X. Cheng, V. C. Lee, C. Jin, Automated pixel-level pavement distress detection based on stereo vision and deep learning, Autom. Constr., 129 (2021), 103788. https://doi.org/10.1016/j.autcon.2021.103788 doi: 10.1016/j.autcon.2021.103788
|
| [6] | H. Zhang, I. Goodfellow, D. Metaxas, A. Odena, Self-attention generative adversarial networks, in Proceedings of the 36th International Conference on Machine Learning, 97 (2019), 7354–7363. https://doi.org/10.48550/arXiv.1805.08318 |
| [7] |
Z. Tong, T. Ma, W. Zhang, J. Huyan, Evidential transformer for pavement distress segmentation, Comput. Aided Civ. Infrastruct. Eng., 38 (2023), 2317–2338. https://doi.org/10.1111/mice.13018 doi: 10.1111/mice.13018
|
| [8] | I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, et al., Generative adversarial networks, Adv. Neural Inf. Process. Syst., 27 (2020). https://doi.org/10.48550/arXiv.1406.2661 |
| [9] | M. Arjovsky, S. Chintala, L. Bottou, Wasserstein generative adversarial networks, Int. Conf. Mach. Learn., (2017), 214–223. https://doi.org/10.48550/arXiv.1701.07875 |
| [10] | T. Karras, T. Aila, S. Laine, J. Lehtinen, Progressive growing of gans for improved quality, stability, and variation, preprint, arXiv: 1710.10196. https://doi.org/10.48550/arXiv.1710.10196 |
| [11] | X. Mao, Q. Li, H. Xie, R. Y. Lau, Z. Wang, S. P. Smolley, Least squares generative adversarial networks, in Proceedings of the IEEE International Conference on Computer Vision (ICCV), (2017), 2794–2802. https://doi.org/10.48550/arXiv.1611.04076 |
| [12] | T. Karras, S. Laine, T. Aila, A style-based generator architecture for generative adversarial networks, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 4401–4410. https://doi.org/10.48550/arXiv.1812.04948 |
| [13] |
L. Pei, Z. Sun, L. Xiao, W. Li, J. Sun, H. Zhang, Virtual generation of pavement crack images based on improved deep convolutional generative adversarial network, Eng. Appl. Artif. Intell., 104 (2021), 104376. https://doi.org/10.1016/j.engappai.2021.104376 doi: 10.1016/j.engappai.2021.104376
|
| [14] |
B. Xu, C. Liu, Pavement crack detection algorithm based on generative adversarial network and convolutional neural network under small samples, Measurement, 196 (2022), 111219. https://doi.org/10.1016/j.measurement.2022.111219 doi: 10.1016/j.measurement.2022.111219
|
| [15] | D. Mazzini, P. Napoletano, F. Piccoli, R. Schettini, A novel approach to data augmentation for pavement distress segmentation, Comput. Ind., 121 (2020). https://doi.org/10.1016/j.compind.2020.103225 |
| [16] | L. L. Pei, Z. Y. Sun, L. Y. Xiao, W. Li, J. Sun, H. Zhang, Virtual generation of pavement crack images based on improved deep convolutional generative adversarial network, Eng. Appl. Artif. Intell., 104 (2021). https://doi.org/10.1016/j.engappai.2021.104376 |
| [17] | I. Gulrajani, F. Ahmed, M. Arjovsky, V. Dumoulin, A. C. Courville, Improved training of wasserstein gans, Adv. Neural Inf. Process. Syst., 30 (2017). https://doi.org/10.48550/arXiv.1704.00028 |
| [18] | K. M. He, X. Y. Zhang, S. Q. Ren, J. Sun, Ieee: 'Deep residual learning for image recognition', in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2016), 770–778 |
| [19] | Z. Xu, X. Yu, Z. Liu, S. Zhang, Q. Sun, N. Chen, et al., Safety monitoring of transportation infrastructure foundation: Intelligent recognition of subgrade distresses based on B-Scan GPR images, IEEE Trans. Intell. Transp. Syst., (2022), 15468–15477. https://doi.org/10.1109/TITS.2022.3224769 |
| [20] | J. X. Dong, N. N. Wang, H. Y. Fang, Q. F. Hu, C. Zhang, B. S. Ma, et al., Innovative method for pavement multiple damages segmentation and measurement by the Road-Seg-CapsNet of feature fusion, Constr. Build. Mater., 324 (2022). https://doi.org/10.1016/j.conbuildmat.2022.126719 |
| [21] |
Y. Shi, L. M. Cui, Z. Q. Qi, F. Meng, Z. S. Chen, Automatic road crack detection using random structured forests, IEEE Trans. Intell. Transp. Syst., 17 (2016), 3434–3445. https://doi.org/10.1109/tits.2016.2552248 doi: 10.1109/tits.2016.2552248
|
| [22] |
F. Yang, L. Zhang, S. J. Yu, D. Prokhorov, X. Mei, H. B. Ling, Feature pyramid and hierarchical boosting network for pavement crack detection, IEEE Trans. Intell. Transp. Syst., 21 (2020), 1525–1535. https://doi.org/10.1109/tits.2019.2910595 doi: 10.1109/tits.2019.2910595
|
| [23] |
Q. Zou, Y. Cao, Q. Q. Li, Q. Z. Mao, S. Wang, Crack Tree: Automatic crack detection from pavement images, Pattern Recognit. Lett., 33 (2012), 227–238. https://doi.org/10.1016/j.patrec.2011.11.004 doi: 10.1016/j.patrec.2011.11.004
|
| [24] | M. Eisenbach, R. Stricker, D. Seichter, K. Amende, K. Debes, M. Sesselmann, et al., How to get pavement distress detection ready for deep learning? A systematic approach, in 2017 International Joint Conference on Neural Networks (IJCNN), (2017), 2039–2047. https://doi.org/10.1109/IJCNN.2017.7966101 |
| [25] |
R. Amhaz, S. Chambon, J. Idier, V. Baltazart, Automatic crack detection on two-dimensional pavement images: An algorithm based on minimal path selection, IEEE Trans. Intell. Transp. Syst., 17 (2016), 2718–2729.https://doi.org/10.1109/TITS.2015.2477675 doi: 10.1109/TITS.2015.2477675
|
| [26] | A. Radford, L. Metz, S. Chintala, Unsupervised representation learning with deep convolutional generative adversarial networks, preprint, arXiv: 1511.06434. https://doi.org/10.48550/arXiv.1511.06434 |
| [27] |
H. Tang, S. Gao, L. Wang, X. Li, B. Li, S. Pang, A novel intelligent fault diagnosis method for rolling bearings based on Wasserstein generative adversarial network and Convolutional Neural Network under Unbalanced Dataset, Sensors, 21 (2021), 6754. https://doi.org/10.3390/s21206754 doi: 10.3390/s21206754
|
| [28] |
A. Kyslytsyna, K. Xia, A. Kislitsyn, I. Abd El Kader, Y. Wu, Road surface crack detection method based on conditional generative adversarial networks, Sensors, 21 (2021), 7405. https://doi.org/10.3390/s21217405 doi: 10.3390/s21217405
|
| [29] | M. Mirza, S. Osindero, Conditional generative adversarial nets, preprint, arXiv: 1411.1784. https://doi.org/10.48550/arXiv.1411.1784 |
| [30] | A. Odena, C. Olah, J. Shlens, Conditional image synthesis with auxiliary classifier gans, Int. Conf. Mach. Learn., (2017), 2642–2651. https://doi.org/10.48550/arXiv.1610.09585 |
| [31] |
D. C. Dowson, B. V. Landau, The Fréchet distance between multivariate normal distributions, J. Multivar. Anal., 12 (1982), 450–455. https://doi.org/10.1016/0047-259X(82)90077-X doi: 10.1016/0047-259X(82)90077-X
|
| [32] | C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, Z. Wojna, Rethinking the inception architecture for computer vision, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2016), 2818–2826. https://doi.org/10.48550/arXiv.1512.00567 |
Figures(10) / Tables(2)

Hui Yao, Yuhan Wu, Shuo Liu, Yanhao Liu, Hua Xie. A pavement crack synthesis method based on conditional generative adversarial networks[J]. Mathematical Biosciences and Engineering, 2024, 21(1): 903-923. doi: 10.3934/mbe.2024038







 DownLoad:
DownLoad: