In this paper, we study the problem of optimal control of backward stochastic differential equations with three delays (discrete delay, moving-average delay and noisy memory). We establish the sufficient optimality condition for the stochastic system. We introduce two kinds of time-advanced stochastic differential equations as the adjoint equations, which involve the partial derivatives of the function $ f $ and its Malliavin derivatives. We also show that these two kinds of adjoint equations are equivalent. Finally, as applications, we discuss a linear-quadratic backward stochastic system and give an explicit optimal control. In particular, the stochastic differential equations with time delay are simulated by means of discretization techniques, and the effect of time delay on the optimal control result is explained.
Citation: Heping Ma, Hui Jian, Yu Shi. A sufficient maximum principle for backward stochastic systems with mixed delays[J]. Mathematical Biosciences and Engineering, 2023, 20(12): 21211-21228. doi: 10.3934/mbe.2023938
In this paper, we study the problem of optimal control of backward stochastic differential equations with three delays (discrete delay, moving-average delay and noisy memory). We establish the sufficient optimality condition for the stochastic system. We introduce two kinds of time-advanced stochastic differential equations as the adjoint equations, which involve the partial derivatives of the function $ f $ and its Malliavin derivatives. We also show that these two kinds of adjoint equations are equivalent. Finally, as applications, we discuss a linear-quadratic backward stochastic system and give an explicit optimal control. In particular, the stochastic differential equations with time delay are simulated by means of discretization techniques, and the effect of time delay on the optimal control result is explained.

| [1] |
E. Pardoux, S. G. Peng, Adapted solutions of backward differential equations, Syst. Control Lett., 14 (1990), 55–61. https://doi.org/10.1016/0304-4149(95)00024-2 doi: 10.1016/0304-4149(95)00024-2

|
| [2] |
N. El Karoui, S. G. Peng, M. Quenez, Backward stochastic differential equations in finance, Math. Finance, 7 (1997), 1–71. https://doi.org/10.1111/1467-9965.00022 doi: 10.1111/1467-9965.00022
|
| [3] |
D. Duffie, P. Geoffard, C. Skiadas, Efficient and equilibrium allocations with stochastic differential utility, J. Math. Econ., 23 (1994), 133–146. https://doi.org/10.1016/0304-4068(94)90002-7 doi: 10.1016/0304-4068(94)90002-7
|
| [4] |
G. Wang, H. Zhang, Mean-field backward stochastic differential equation with non-Lipschitz coefficient, Asian J. Control, 22 (2019), 1986–1994. https://doi.org/10.1002/asjc.2087 doi: 10.1002/asjc.2087
|
| [5] |
P. Huang, G. Wang, H. Zhang, An asymmetric information non-zero sum differential game of mean-field backward stochastic differential equation with applications, Adv. Differ. Equ., 236 (2019), 1–25. https://doi.org/10.1186/s13662-019-2166-5 doi: 10.1186/s13662-019-2166-5
|
| [6] | J. Yong, X. Zhou, Stochastic Controls: Hamiltonian Systems and HJB Equations, Springer-Verlag, New York, NY, USA, 1999. |
| [7] | A. Bressan, B. Piccoli, Introduction to the Mathematical Theory of Control, Springfield: American Institute of Mathematical Sciences, 1 (2007). |
| [8] |
N. Dokuchaev, X. Zhou, Stochastic controls with terminal contingent conditions, J. Math. Anal. Appl., 238 (1999), 143–165. https://doi.org/10.1006/JMAA.1999.6515 doi: 10.1006/JMAA.1999.6515
|
| [9] |
A. E. B. Lim, X. Zhou, Linear-quadratic control of backward stochastic differential equations, SIAM J. Control Optim., 40 (2001), 450–474. https://doi.org/10.1137/S0363012900374737 doi: 10.1137/S0363012900374737
|
| [10] |
J. Huang, G. Wang, J. Xiong, A maximum principle for partial information backward stochastic control problems with applications, SIAM J. Control Optim., 48 (2009), 2106–2117. https://doi.org/10.1137/080738465 doi: 10.1137/080738465
|
| [11] |
Z. Huang, Y. Wang, X. R. Wang, A mean-field optimal control for fully coupled forward-backward stochastic control systems with Lévy processes, J. Syst. Sci. Complex, 35 (2022), 205–220. https://doi.org/10.1007/s11424-021-0077-5 doi: 10.1007/s11424-021-0077-5
|
| [12] |
G. Wang, Z. Yu, A Pontryagin's maximum principle for non-zero sum differential games of BSDEs with applications, IEEE Trans. Autom. Control, 55 (2010), 1742–1747. https://doi.org/10.1109/TAC.2010.2048052 doi: 10.1109/TAC.2010.2048052
|
| [13] |
G. Wang, Z. Yu, A partial information non-zero sum differential game of backward stochastic differential equations with applications, Automatica, 48 (2012), 342–352. https://doi.org/10.1016/j.automatica.2011.11.010 doi: 10.1016/j.automatica.2011.11.010
|
| [14] |
G. Wang, H. Xiao, J. Xiong, A kind of linear quadratic non-zero differential game of backward stochastic differential equation with asymmetric information, Automatica, 63 (2018), 346–352. https://doi.org/10.1016/j.automatica.2018.08.019 doi: 10.1016/j.automatica.2018.08.019
|
| [15] |
S. Peng, Backward stochastic differential equations and applications to optimal control, Appl. Math. Optim., 27 (1993), 125–144. https://doi.org/10.1007/BF01195978 doi: 10.1007/BF01195978
|
| [16] |
W. Xu, Stochastic maximum principle for optimal control problem of forward and backward system, J. Aust. Math. Soc. Ser. B., 37 (1995), 172–185. https://doi.org/10.1017/S0334270000007645 doi: 10.1017/S0334270000007645
|
| [17] |
L. Chen, P. Zhou, H. Xiao, Backward Stackelberg games with delay and related forward-backward stochastic differential equaitons, Mathematics, 11 (2023), 2898. https://doi.org/10.3390/math11132898 doi: 10.3390/math11132898
|
| [18] |
Y. Zheng, J. Shi, A stackelberg game of backward stochastic differential equations with applications, J. Optim. Theory Appl., 10 (2019), 968–992. https://doi.org/10.1007/s13235-019-00341-z doi: 10.1007/s13235-019-00341-z
|
| [19] |
T. Wang, Backward stochastic volterra integro-differential equations and applications, SIAM J. Control Optim., 60 (2022), 2393–2419. https://doi.org/10.1137/20m1371464 doi: 10.1137/20m1371464
|
| [20] |
X. Li, J. Sun, J. Xiong, Linear quadratic optimal control problems for mean-field backward stochastic differential equations, Appl. Math. Optim., 80 (2019), 223–250. https://doi.org/10.1007/s00245-017-9464-7 doi: 10.1007/s00245-017-9464-7
|
| [21] |
L. Delong, P. Imleller, Backward stochastic differential equations with time delayed generators-results and counter examples, Ann. Appl. Probab., 20 (2010), 1512–1536. https://doi.org/10.1214/09-AAP663 doi: 10.1214/09-AAP663
|
| [22] | S. Tomasiello, L. Rarità, An approximation technique and a possible application for a class of delay differential equations, in Proceedings of the 34th European Modeling & Simulation Symposium (EMSS 2022), (2022), 45. https://doi.org/10.46354/i3m.2022.emss.045 |
| [23] |
L. Rarità, C. D'Apice, B. Piccoli, D. Helbing, Sensitivity analysis of permeability parameters for flows on Barcelona networks, J. Differ. Equations, 249 (2010), 3110–3131. https://doi.org/10.1016/J.JDE.2010.09.006 doi: 10.1016/J.JDE.2010.09.006
|
| [24] |
L. Chen, J. H. Huang, Stochastic maximum principle for controlled backward delayed system via advanced stochastic differential equation, J. Optim. Theroy Appl., 167 (2015), 1112–1135. https://doi.org/10.1007/s10957-013-0386-5 doi: 10.1007/s10957-013-0386-5
|
| [25] |
N. Anakira, A. Alomari, I. Hashim, Optimal homotopy asymptotic method for solving delay differential equations, Math. Probl. Eng., 2013 (2013), 498902. https://doi.org/10.1155/2013/498902 doi: 10.1155/2013/498902
|
| [26] |
S. Wu, G. Wang, Optimal control problem of backward stochstic differential delay equation under partial information, Syst. Control Lett., 82 (2015), 71–78. https://doi.org/10.1016/j.sysconle.2015.05.008 doi: 10.1016/j.sysconle.2015.05.008
|
| [27] |
K. Dahl, S. E. A. Mohammed, B. Øksendal, E. Røse, Optimal control of systems with noisy memory and BSDEs with Malliavin derivatives, J. Funct. Anal., 271 (2016), 289–329. https://doi.org/10.1016/J.JFA.2016.04.031 doi: 10.1016/J.JFA.2016.04.031
|
| [28] | Y. Kazmerchuk, A. Swishchuk, J. Wu, A continuous-time GARCH model for stochastic volatility with delay, Can. Appl. Math. Q., 13 (2005), 123–149. |
| [29] |
A. Delavarkhalafi, A. S. Fatemion Aghda, M. Tahmasebi, Maximum principle for infinite horizon optimal control of mean-field backward stochastic systems with delay and noisy memory, Int. J. Control, 95 (2020), 535–543. https://doi.org/10.1080/00207179.2020.1800822 doi: 10.1080/00207179.2020.1800822
|
| [30] |
J. Ma, P. Protter, J. M. Yong, Solving forward-backward stochastic differential equations explicitly–-a four step scheme, Probab. Theory Relat. Fields, 98 (1994), 339–359. https://doi.org/10.1007/BF01192258 doi: 10.1007/BF01192258
|
| [31] |
F. Zhang, Sufficient maximum prinicple for stochastic optimal control problems with general delays, J. Optim. Theory Appl., 192 (2022), 678–701. https://doi.org/10.1007/s10957-021-01987-9 doi: 10.1007/s10957-021-01987-9
|
| [32] | G. Di Nunno, B. Øksendal, F. Proske, Malliavin Calculus for Lévy Processes with Applications to Finance, Berlin: Springer, 2009. |
| [33] | D. Nualart, The Malliavin Calculus and Related Topics, Berlin: Springer, 2006. |
| [34] |
G. Di Nunno, T. Meyer-Brandis, B. Øksendal, F. Proske, Malliavin calculus and anticipative Itô formula for Lévy processes, Infin. Dimension. Anal. Quantum Probab. Relat. Top., 08 (2005), 235–258. https://doi.org/10.1142/S0219025705001950 doi: 10.1142/S0219025705001950
|
| [35] |
A. Delavarkhalafi, A. S. Fatemion Aghda, M. Tahmasebi, Maximum principle for infinite horizon optimal control of mean-field backward stochastic systems with delay and noisy memory, Int. J. Control, 95 (2022), 535–543. https://doi.org/10.1080/00207179.2020.1800822 doi: 10.1080/00207179.2020.1800822
|
| [36] |
H. Ma, L. Bin, Infinite horizon optimal control problem of mean-field backward stochastic delay differential equation under partial information, Eur. J. Control, 36 (2017), 43–50. https://doi.org/10.1016/j.ejcon.2017.04.001 doi: 10.1016/j.ejcon.2017.04.001
|
| [37] | S. Wu, Partially-observed maximum principle for backward stochastic differential delay equations, IEEE/CAA J. Autom. Sin., (2017), 1–6. https://doi.org/10.1109/JAS.2017.7510472 |
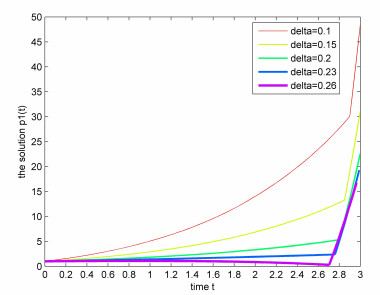


Figures(3)

Heping Ma, Hui Jian, Yu Shi. A sufficient maximum principle for backward stochastic systems with mixed delays[J]. Mathematical Biosciences and Engineering, 2023, 20(12): 21211-21228. doi: 10.3934/mbe.2023938







 DownLoad:
DownLoad: