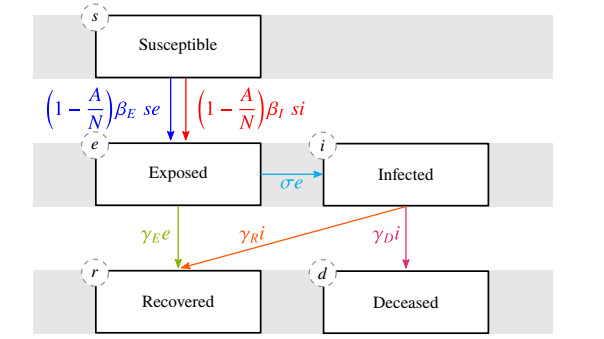
A nonlinear partial differential equation (PDE) based compartmental model of COVID-19 provides a continuous trace of infection over space and time. Finer resolutions in the spatial discretization, the inclusion of additional model compartments and model stratifications based on clinically relevant categories contribute to an increase in the number of unknowns to the order of millions. We adopt a parallel scalable solver that permits faster solutions for these high fidelity models. The solver combines domain decomposition and algebraic multigrid preconditioners at multiple levels to achieve the desired strong and weak scalabilities. As a numerical illustration of this general methodology, a five-compartment susceptible-exposed-infected-recovered-deceased (SEIRD) model of COVID-19 is used to demonstrate the scalability and effectiveness of the proposed solver for a large geographical domain (Southern Ontario). It is possible to predict the infections for a period of three months for a system size of 186 million (using 3200 processes) within 12 hours saving months of computational effort needed for the conventional solvers.
Citation: Sudhi Sharma, Victorita Dolean, Pierre Jolivet, Brandon Robinson, Jodi D. Edwards, Tetyana Kendzerska, Abhijit Sarkar. Scalable computational algorithms for geospatial COVID-19 spread using high performance computing[J]. Mathematical Biosciences and Engineering, 2023, 20(8): 14634-14674. doi: 10.3934/mbe.2023655
A nonlinear partial differential equation (PDE) based compartmental model of COVID-19 provides a continuous trace of infection over space and time. Finer resolutions in the spatial discretization, the inclusion of additional model compartments and model stratifications based on clinically relevant categories contribute to an increase in the number of unknowns to the order of millions. We adopt a parallel scalable solver that permits faster solutions for these high fidelity models. The solver combines domain decomposition and algebraic multigrid preconditioners at multiple levels to achieve the desired strong and weak scalabilities. As a numerical illustration of this general methodology, a five-compartment susceptible-exposed-infected-recovered-deceased (SEIRD) model of COVID-19 is used to demonstrate the scalability and effectiveness of the proposed solver for a large geographical domain (Southern Ontario). It is possible to predict the infections for a period of three months for a system size of 186 million (using 3200 processes) within 12 hours saving months of computational effort needed for the conventional solvers.

| [1] | B. Robinson, J. D. Edwards, T. Kendzerska, C. L. Pettit, D. Poirel, J. M. Daly, et al., Comprehensive compartmental model and calibration algorithm for the study of clinical implications of the population-level spread of COVID-19: a study protocol, BMJ Open, 12 (2012). AVailable from: https://bmjopen.bmj.com/content/12/3/e052681. |
| [2] |
A. R. Tuite, D. N. Fisman, A. L. Greer, Mathematical modelling of COVID-19 transmission and mitigation strategies in the population of Ontario, Canada, CMAJ, 192 (2020), E497–E505. https://doi.org/10.1503/cmaj.200476 doi: 10.1503/cmaj.200476

|
| [3] |
G. Bertaglia, L. Pareschi, Hyperbolic compartmental models for epidemic spread on networks with uncertain data: application to the emergence of COVID-19 in Italy, Math. Models Methods Appl. Sci., 31 (2021), 2495–2531. https://doi.org/10.1142/S0218202521500548 doi: 10.1142/S0218202521500548
|
| [4] |
C. C. Kerr, R. M. Stuart, D. Mistry, R. G. Abeysuriya, K. Rosenfeld, G. R. Hart, et al., Covasim: an agent-based model of COVID-19 dynamics and interventions, PLoS Comput. Biol., 17 (2021), e1009149. https://doi.org/10.1371/journal.pcbi.1009149 doi: 10.1371/journal.pcbi.1009149
|
| [5] |
A. Mollalo, B. Vahedi, K. M. Rivera, GIS-based spatial modeling of COVID-19 incidence rate in the continental United states, Sci. Total Environ., 728 (2020), 138884. https://doi.org/10.1016/j.scitotenv.2020.138884 doi: 10.1016/j.scitotenv.2020.138884
|
| [6] | H. Wang, N. Yamamoto, Using a partial differential equation with google mobility data to predict COVID-19 in Arizona, preprint, arXiv: 2006.16928. |
| [7] |
P. K. Jha, L. Cao, J. T. Oden, Bayesian-based predictions of COVID-19 evolution in {T}exas using multispecies mixture-theoretic continuum models, Comput. Mech., 66 (2020), 1055–1068. https://doi.org/10.1007/s00466-020-01889-z doi: 10.1007/s00466-020-01889-z
|
| [8] |
J. P. Keller, L. Gerardo-Giorda, A. Veneziani, Numerical simulation of a susceptible–exposed–infectious space-continuous model for the spread of rabies in raccoons across a realistic landscape, J. Biol. Dyn., 7 (2013), 31–46. https://doi.org/10.1080/17513758.2012.742578 doi: 10.1080/17513758.2012.742578
|
| [9] |
A. Viguerie, G. Lorenzo, F. Auricchio, D. Baroli, T. J. Hughes, A. Patton, et al., Simulating the spread of COVID-19 via a spatially-resolved susceptible–exposed–infected–recovered–deceased (SEIRD) model with heterogeneous diffusion, Appl. Math. Lett., 111 (2021), 106617. https://doi.org/10.1016/j.aml.2020.106617 doi: 10.1016/j.aml.2020.106617
|
| [10] |
A. Viguerie, A. Veneziani, G. Lorenzo, D. Baroli, N. Aretz-Nellesen, A. Patton, et al., Diffusion–reaction compartmental models formulated in a continuum mechanics framework: application to COVID-19, mathematical analysis, and numerical study, Comput. Mech., 66 (2020), 1131–1152. https://doi.org/10.1007/s00466-020-01888-0 doi: 10.1007/s00466-020-01888-0
|
| [11] |
T. F. Chan, T. P. Mathew, Domain decomposition algorithms, Acta Numer., 3 (1994), 61–143. https://doi.org/10.1017/S0962492900002427 doi: 10.1017/S0962492900002427
|
| [12] | V. Dolean, P. Jolivet, F. Nataf, An Introduction to Domain Decomposition Methods: Algorithms, Theory, and Parallel Implementation, SIAM, 2015. |
| [13] | T. Mathew, Domain Decomposition Methods for the Numerical Solution of Partial Differential Equations, Springer Science & Business Media, 61 (2008). |
| [14] | B. F. Smith, Domain decomposition methods for partial differential equations, in Parallel Numerical Algorithms, Springer, (1997), 225–243. https://doi.org/10.1007/978-94-011-5412-3_8 |
| [15] | A. Toselli, O. Widlund, Domain Decomposition Methods-Algorithms and Theory, Springer Science & Business Media, 34 (2004). https://doi.org/10.1007/b137868 |
| [16] |
D. Knoll, P. McHugh, Newton-Krylov methods applied to a system of convection-diffusion-reaction equations, Comput. Phys. Commun., 88 (1995), 141–160. https://doi.org/10.1016/0010-4655(95)00062-K doi: 10.1016/0010-4655(95)00062-K
|
| [17] |
J. N. Shadid, R. Tuminaro, K. D. Devine, G. L. Hennigan, P. Lin, Performance of fully coupled domain decomposition preconditioners for finite element transport/reaction simulations, J. Comput. Phys., 205 (2005), 24–47. https://doi.org/10.1016/j.jcp.2004.10.038 doi: 10.1016/j.jcp.2004.10.038
|
| [18] |
X. C. Cai, D. E. Keyes, L. Marcinkowski, Nonlinear additive Schwarz preconditioners and application in computational fluid dynamics, Int. J. Numer. Methods Fluids, 40 (2002), 1463–1470. https://doi.org/10.1002/fld.404 doi: 10.1002/fld.404
|
| [19] |
V. Dolean, M. J. Gander, W. Kheriji, F. Kwok, R. Masson, Nonlinear preconditioning: how to use a nonlinear Schwarz method to precondition Newton's method, SIAM J. Sci. Comput., 38 (2016), A3357–A3380. https://doi.org/10.1137/15M102887X doi: 10.1137/15M102887X
|
| [20] |
A. Klawonn, M. Lanser, O. Rheinbach, Nonlinear FETI-DP and BDDC methods, SIAM J. Sci. Comput., 36 (2014), A737–A765. https://doi.org/10.1137/130920563 doi: 10.1137/130920563
|
| [21] | ICES (formerly the Institute of Clinical Evaluative Sciences), 2021. Available from: www.ices.on.ca/Data-and-Privacy/. Accessed: 2021-01-07, ICES is an independent, non-profit research institute funded by an annual grant from the Ontario Ministry of Health and Long-Term Care. As a prescribed entity under Ontario's privacy legislation, ICES is authorized to collect and use health care data for the purposes of health system analysis, evaluation, and decision support. Secure access to these data is governed by policies and procedures that are approved by the Information and Privacy Commissioner of Ontario. |
| [22] |
G. Bertaglia, W. Boscheri, G. Dimarco, L. Pareschi, Spatial spread of COVID-19 outbreak in Italy using multiscale kinetic transport equations with uncertainty, Math. Biosci. Eng., 18 (2021), 7028–7059. https://doi.org/10.3934/mbe.2021350 doi: 10.3934/mbe.2021350
|
| [23] | O. Le Maître, O. M. Knio, Spectral Methods for Uncertainty Quantification: with Applications to Computational Fluid Dynamics, Springer Science & Business Media, 2010. https://doi.org/10.1007/978-90-481-3520-2 |
| [24] |
A. Sarkar, N. Benabbou, R. Ghanem, Domain decomposition of stochastic PDEs: theoretical formulations, Int. J. Numer. Methods Eng., 77 (2009), 689–701. https://doi.org/10.1002/nme.2431 doi: 10.1002/nme.2431
|
| [25] | M. Emmett, M. Minion, Toward an efficient parallel in time method for partial differential equations, Commun. Appl. Math. Comput. Sci., Mathematical Sciences Publishers, 7 (2012), 105–132. https://doi.org/10.2140/camcos.2012.7.105 |
| [26] |
A. Aghabarati, J. P. Webb, Algebraic multigrid combined with domain decomposition for the finite element analysis of large scattering problems, IEEE Trans. Antennas Propag., 63 (2014), 404–408. https://doi.org/10.1109/TAP.2014.2365047 doi: 10.1109/TAP.2014.2365047
|
| [27] |
A. Arrarás, F. J. Gaspar, L. Portero, C. Rodrigo, Domain decomposition multigrid methods for nonlinear reaction–diffusion problems, Commun. Nonlinear Sci. Numer. Simul., 20 (2015), 699–710. https://doi.org/10.1016/j.cnsns.2014.06.044 doi: 10.1016/j.cnsns.2014.06.044
|
| [28] | H. Sundar, G. Biros, C. Burstedde, J. Rudi, O. Ghattas, G. Stadler, Parallel geometric-algebraic multigrid on unstructured forests of octrees, in SC'12: Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis, IEEE, (2012), 1–11. |
| [29] |
J. M. Tang, S. P. MacLachlan, R. Nabben, C. Vuik, A comparison of two-level preconditioners based on multigrid and deflation, SIAM J. Matrix Anal. Appl., 31 (2010), 1715–1739. https://doi.org/10.1137/08072084X doi: 10.1137/08072084X
|
| [30] |
J. M. Tang, R. Nabben, C. Vuik, Y. A. Erlangga, Comparison of two-level preconditioners derived from deflation, domain decomposition and multigrid methods, J. Sci. Comput., 39 (2009), 340–370. https://doi.org/10.1007/s10915-009-9272-6 doi: 10.1007/s10915-009-9272-6
|
| [31] |
H. Al Daas, L. Grigori, P. Jolivet, P. H. Tournier, A multilevel schwarz preconditioner based on a hierarchy of robust coarse spaces, SIAM J. Sci. Comput., 43 (2021), A1907–A1928. https://doi.org/10.1137/19M1266964 doi: 10.1137/19M1266964
|
| [32] |
A. Borzì, V. De Simone, D. Di Serafino, Parallel algebraic multilevel schwarz preconditioners for a class of elliptic pde systems, Comput. Visualization Sci., 16 (2013), 1–14. https://doi.org/10.1007/s00791-014-0220-0 doi: 10.1007/s00791-014-0220-0
|
| [33] |
L. F. Pavarino, S. Scacchi, Parallel multilevel schwarz and block preconditioners for the bidomain parabolic-parabolic and parabolic-elliptic formulations, SIAM J. Sci. Comput., 33 (2011), 1897–1919. https://doi.org/10.1137/100808721 doi: 10.1137/100808721
|
| [34] |
E. E. Holmes, M. A. Lewis, J. Banks, R. Veit, Partial differential equations in ecology: spatial interactions and population dynamics, Ecology, 75 (1994), 17–29. https://doi.org/10.2307/1939378 doi: 10.2307/1939378
|
| [35] | J. D. Murray, Mathematical Biology I. An Introduction, Springer, 2002. https://doi.org/10.1007/b98868 |
| [36] | F. Brauer, P. Van Den Driessche, J. Wu, L. J. S. Allen, Mathematical Epidemiology, Springer, 1945 (2008). |
| [37] | M. J. Keeling, P. Rohani, Modeling Infectious Diseases in Humans and Animals, Princeton University Press, 2008. |
| [38] |
M. Grave, A. L. Coutinho, Adaptive mesh refinement and coarsening for diffusion–reaction epidemiological models, Comput. Mech., 67 (2021), 1177–1199. https://doi.org/10.1007/s00466-021-01986-7 doi: 10.1007/s00466-021-01986-7
|
| [39] |
S. J. Ruuth, Implicit-explicit methods for reaction-diffusion problems in pattern formation, J. Math. Biol., 34 (1995), 148–176. https://doi.org/10.1007/BF00178771 doi: 10.1007/BF00178771
|
| [40] |
U. M. Ascher, S. J. Ruuth, B. T. Wetton, Implicit-explicit methods for time-dependent partial differential equations, SIAM J. Numer. Anal., 32 (1995), 797–823. https://doi.org/10.1137/0732037 doi: 10.1137/0732037
|
| [41] | A. J. Wathen, Preconditioning, Acta Numer., 24 (2015), 329–376. https://doi.org/10.1017/S0962492915000021 |
| [42] |
M. Benzi, Preconditioning techniques for large linear systems: a survey, J. Comput. Phys., 182 (2002), 418–477. https://doi.org/10.1006/jcph.2002.7176 doi: 10.1006/jcph.2002.7176
|
| [43] | S. Balay, S. Abhyankar, M. F. Adams, S. Benson, J. Brown, P. Brune, et al., PETSc {W}eb page, 2021, Available from: https://petsc.org/. |
| [44] | W. L. Briggs, V. E. Henson, S. F. McCormick, A Multigrid Tutorial, SIAM, 2000. |
| [45] | G. Strang, Computational Science and Engineering, Wellesley-Cambridge Press, 2007. Available from: https://books.google.co.in/books?id = GQ9pQgAACAAJ. |
| [46] | U. Trottenberg, C. W. Oosterlee, A. Schuller, Multigrid, Elsevier, 2000. |
| [47] | P. S. Vassilevski, Lecture Notes on Multigrid Methods, Technical Report, Lawrence Livermore National Lab, Livermore, CA (United States), 2010. |
| [48] | R. D. Falgout, An Introduction to Algebraic Multigrid, Technical Report, Lawrence Livermore National Lab.(LLNL), Livermore, CA (United States), 2006. |
| [49] |
J. Xu, L. Zikatanov, Algebraic multigrid methods, Acta Numer., 26 (2017), 591–721. https://doi.org/10.1017/S0962492917000083 doi: 10.1017/S0962492917000083
|
| [50] |
F. Hecht, New development in FreeFem++, J. Numer. Math., 20 (2012), 251–265. https://doi.org/10.1515/jnum-2012-0013 doi: 10.1515/jnum-2012-0013
|
| [51] | HYPRE: Scalable linear solvers and multigrid methods. Available from: https://computing.llnl.gov/projects/hypre-scalable-linear-solvers-multigrid-methods. |
| [52] |
V. E. Henson, U. M. Yang, BoomerAMG: a parallel algebraic multigrid solver and preconditioner, Appl. Numer. Math., 41 (2002), 155–177. https://doi.org/10.1016/S0168-9274(01)00115-5 doi: 10.1016/S0168-9274(01)00115-5
|
| [53] |
Y. Saad, A flexible inner-outer preconditioned GMRES algorithm, SIAM J. Sci. Comput., 14 (1993), 461–469. https://doi.org/10.1137/0914028 doi: 10.1137/0914028
|
| [54] |
A. Ghai, C. Lu, X. Jiao, A comparison of preconditioned Krylov subspace methods for large-scale nonsymmetric linear systems, Numer. Linear Algebra Appl., 26 (2019), e2215. https://doi.org/10.1002/nla.2215 doi: 10.1002/nla.2215
|
| [55] | Digital Research Alliance of Canada. Available from: https://alliancecan.ca/en. |
| [56] | BELUGA supercomputer. Available from: https://docs.alliancecan.ca/wiki/B%C3%A9luga/en. |
| [57] | NIAGARA supercomputer. Available from: https://docs.alliancecan.ca/wiki/Niagara. |
| [58] | M. Howison, E. W. Bethel, H. Childs, Hybrid parallelism for volume rendering on large-, multi-, and many-core systems, IEEE Trans. Visual Comput. Graphics, IEEE, 18 (2021), 17–29. https://doi.org/10.1109/TVCG.2011.24 |
| [59] |
S. Deparis, G. Grandperrin, A. Quarteroni, Parallel preconditioners for the unsteady navier–stokes equations and applications to hemodynamics simulations, Comput. Fluids, 92 (2014), 253–273. https://doi.org/10.1016/j.compfluid.2013.10.034 doi: 10.1016/j.compfluid.2013.10.034
|
| [60] | Ministry of health and ministry of long-term care. Available from: https://www.health.gov.on.ca/en/common/system/services/phu/. |
| [61] | QGIS Development Team, QGIS Geographic Information System, QGIS Association, 2021. |
| [62] | Ontario GeoHub, 2021. Available from: https://geohub.lio.gov.on.ca. |
| [63] | 2019 novel coronavirus data catalogue, 2021. Available from: https://data.ontario.ca/en/group/2019-novel-coronavirus. |
| [64] |
J. A. Long, C. Ren, Associations between mobility and socio-economic indicators vary across the timeline of the COVID-19 pandemic, Comput. Environ. Urban Syst., 91 (2022), 101710. https://doi.org/10.1016/j.compenvurbsys.2021.101710 doi: 10.1016/j.compenvurbsys.2021.101710
|
| [65] | M. Khalil, Bayesian Inference for Complex and Large-Scale Engineering Systems, Ph.D thesis, Carleton University, 2013. |
| [66] |
Y. M. Marzouk, H. N. Najm, Dimensionality reduction and polynomial chaos acceleration of Bayesian inference in inverse problems, J. Comput. Phys., 228 (2009), 1862–1902. https://doi.org/10.1016/j.jcp.2008.11.024 doi: 10.1016/j.jcp.2008.11.024
|
| [67] |
Y. M. Marzouk, H. N. Najm, L. A. Rahn, Stochastic spectral methods for efficient Bayesian solution of inverse problems, J. Comput. Phys., 224 (2007), 560–586. https://doi.org/10.1016/j.jcp.2006.10.010 doi: 10.1016/j.jcp.2006.10.010
|
| [68] | K. Salari, P. Knupp, Code Verification by the Method of Manufactured Solutions, Technical Report, Sandia National Laboratories, 2000. Available from: https://digital.library.unt.edu/ark: /67531/metadc702130/. |
| [69] |
P. J. Roache, Code verification by the method of manufactured solutions, J. Fluids Eng., 124 (2002), 4–10. https://doi.org/10.1115/1.1436090 doi: 10.1115/1.1436090
|
| [70] | O. C. Zienkiewicz, R. L. Taylor, R. L. Taylor, The Finite Element Method: Solid Mechanics, Butterworth-heinemann, 2 (2000). https://doi.org/10.1016/C2009-0-26332-X |
| [71] | T. J. Hughes, The Finite Element Method: Linear Static and Dynamic Finite Element Analysis, Courier Corporation, 2012. |
















Figures(17) / Tables(7)

Sudhi Sharma, Victorita Dolean, Pierre Jolivet, Brandon Robinson, Jodi D. Edwards, Tetyana Kendzerska, Abhijit Sarkar. Scalable computational algorithms for geospatial COVID-19 spread using high performance computing[J]. Mathematical Biosciences and Engineering, 2023, 20(8): 14634-14674. doi: 10.3934/mbe.2023655







 DownLoad:
DownLoad: