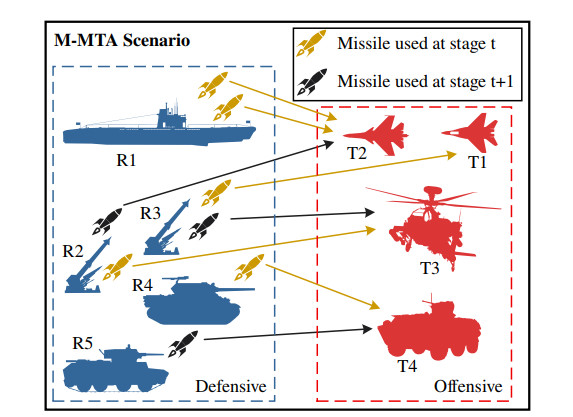
This paper investigates a novel multi-objective optimization framework for the multi-stage missile target allocation (M-MTA) problem, which also widely exists in other real-world complex systems. Specifically, a constrained model of M-MTA is built with the trade-off between minimizing the survivability of targets and minimizing the cost consumption of missiles. Moreover, a multi-objective optimization algorithm (NSGA-MTA) is proposed for M-MTA, where the hybrid encoding mechanism establishes the expression of the model and algorithm. Furthermore, rule-based initialization is developed to enhance the quality and searchability of feasible solutions. An efficient non-dominated sorting method is introduced into the framework as an effective search strategy. Besides, the genetic operators with the greedy mechanism and random repair strategy are involved in handling the constraints with maintaining diversity. The results of numerical experiments demonstrate that NSGA-MTA performs better in diversity and convergence than the excellent current algorithms in metrics and Pareto front obtained in 15 scenarios. Taguchi method is also adopted to verify the contribution of proposed strategies, and the results show that these strategies are practical and promotive to performance improvement.
Citation: Shiqi Zou, Xiaoping Shi, Shenmin Song. A multi-objective optimization framework with rule-based initialization for multi-stage missile target allocation[J]. Mathematical Biosciences and Engineering, 2023, 20(4): 7088-7112. doi: 10.3934/mbe.2023306
This paper investigates a novel multi-objective optimization framework for the multi-stage missile target allocation (M-MTA) problem, which also widely exists in other real-world complex systems. Specifically, a constrained model of M-MTA is built with the trade-off between minimizing the survivability of targets and minimizing the cost consumption of missiles. Moreover, a multi-objective optimization algorithm (NSGA-MTA) is proposed for M-MTA, where the hybrid encoding mechanism establishes the expression of the model and algorithm. Furthermore, rule-based initialization is developed to enhance the quality and searchability of feasible solutions. An efficient non-dominated sorting method is introduced into the framework as an effective search strategy. Besides, the genetic operators with the greedy mechanism and random repair strategy are involved in handling the constraints with maintaining diversity. The results of numerical experiments demonstrate that NSGA-MTA performs better in diversity and convergence than the excellent current algorithms in metrics and Pareto front obtained in 15 scenarios. Taguchi method is also adopted to verify the contribution of proposed strategies, and the results show that these strategies are practical and promotive to performance improvement.

| [1] |
R. K. Ahuja, A. Kumar, K. C. Jha, J. B. Orlin, Exact and heuristic algorithms for the weapon-target assignment problem, Oper. Res., 55 (2007), 1136–1146. https://doi.org/10.1287/opre.1070.0440 doi: 10.1287/opre.1070.0440

|
| [2] |
W. Wei, R. Yang, H. Gu, W. Zhao, C. Chen, S. Wan, Multi-objective optimization for resource allocation in vehicular cloud computing networks, IEEE Trans. Intell. Transp. Syst., 23 (2021), 25536–25545. https://doi.org/10.1109/TITS.2021.3091321 doi: 10.1109/TITS.2021.3091321
|
| [3] |
X. Hao, N. Yao, L. Wang, J. Wang, Joint resource allocation algorithm based on multi-objective optimization for wireless sensor networks, Appl. Soft Comput., 94 (2020), 106470. https://doi.org/10.1016/j.asoc.2020.106470 doi: 10.1016/j.asoc.2020.106470
|
| [4] |
O. A. Ogbolumani, N. I. Nwulu, Multi-objective optimisation of constrained food-energy-water-nexus systems for sustainable resource allocation, Sustainable Energy Technol. Assess., 44 (2021), 100967. https://doi.org/10.1016/j.seta.2020.100967 doi: 10.1016/j.seta.2020.100967
|
| [5] | S. P. Lloyd, H. S. Witsenhausen, Weapons allocation is np-complete, in 1986 Summer Computer Simulation Conference, (1986), 1054–1058. |
| [6] |
J. Li, B. Xin, P. M. Pardalos, J. Chen, Solving bi-objective uncertain stochastic resource allocation problems by the CVaR-based risk measure and decomposition-based multi-objective evolutionary algorithms, Ann. Oper. Res., 296 (2021), 639–666. https://doi.org/10.1007/s10479-019-03435-4 doi: 10.1007/s10479-019-03435-4
|
| [7] | P. A. Hosein, M. Athans, Preferential Defense Strategies, 1990. |
| [8] |
B. Xin, J. Chen, J. Zhang, L. Dou, Z. Peng, Efficient decision makings for dynamic weapon-target assignment by virtual permutation and tabu search heuristics, IEEE Trans. Syst. Man Cyber. C, 40 (2010), 649–662. https://doi.org/10.1109/TSMCC.2010.2049261 doi: 10.1109/TSMCC.2010.2049261
|
| [9] |
X. Shi, S. Zou, S. Song, R. Guo, A multi-objective sparse evolutionary framework for large-scale weapon target assignment based on a reward strategy, J. Intell. Fuzzy Syst., 40 (2021), 10043–10061. https://doi.org/10.3233/JIFS-202679 doi: 10.3233/JIFS-202679
|
| [10] |
O. Karasakal, Air defense missile-target allocation models for a naval task group, Comput. Oper. Res., 35 (2008), 1759–1770. https://doi.org/10.1016/j.cor.2006.09.011 doi: 10.1016/j.cor.2006.09.011
|
| [11] |
A. G. Kline, D. K. Ahner, B. J. Lunday, Real-time heuristic algorithms for the static weapon target assignment problem, J. Heuristics, 25 (2019), 377–397. https://doi.org/10.1007/s10732-018-9401-1 doi: 10.1007/s10732-018-9401-1
|
| [12] |
A. G. Kline, D. K. Ahner, B. J. Lunday, A heuristic and metaheuristic approach to the static weapon target assignment problem, J. Global Optim., 78 (2020), 791–812. https://doi.org/10.1007/s10898-020-00938-4 doi: 10.1007/s10898-020-00938-4
|
| [13] |
G. denBroeder Jr, R. Ellison, L. Emerling, On optimum target assignments, Oper. Res., 7 (1959), 322–326. https://doi.org/10.1287/opre.7.3.322 doi: 10.1287/opre.7.3.322
|
| [14] |
Z. J. Lee, C. Y. Lee, S. F. Su, An immunity-based ant colony optimization algorithm for solving weapon–target assignment problem, Appl. Soft Comput., 2 (2002), 39–47. https://doi.org/10.1016/S1568-4946(02)00027-3 doi: 10.1016/S1568-4946(02)00027-3
|
| [15] |
C. M. Lai, T. H. Wu, Simplified swarm optimization with initialization scheme for dynamic weapon–target assignment problem, Appl. Soft Comput., 82 (2019), 105542. https://doi.org/10.1016/j.asoc.2019.105542 doi: 10.1016/j.asoc.2019.105542
|
| [16] |
Z. J. Lee, S. F. Su, C. Y. Lee, Efficiently solving general weapon-target assignment problem by genetic algorithms with greedy eugenics, IEEE Trans. Syst. Man Cyber. B, 33 (2003), 113–121. https://doi.org/10.1109/TSMCB.2003.808174 doi: 10.1109/TSMCB.2003.808174
|
| [17] |
T. Chang, D. Kong, N. Hao, K. Xu, G. Yang, Solving the dynamic weapon target assignment problem by an improved artificial bee colony algorithm with heuristic factor initialization, Appl. Soft Comput., 70 (2018), 845–863. https://doi.org/10.1016/j.asoc.2018.06.014 doi: 10.1016/j.asoc.2018.06.014
|
| [18] | L. Juan, C. Jie, X. Bin, Efficiently solving multi-objective dynamic weapon-target assignment problems by NSGA-II, in 2015 34th Chinese Control Conference (CCC), (2015), 2556–2561. https://doi.org/10.1109/ChiCC.2015.7260033 |
| [19] | J. Li, J. Chen, B. Xin, L. Dou, Solving multi-objective multi-stage weapon target assignment problem via adaptive NSGA-II and adaptive MOEA/D: A comparison study, in 2015 IEEE Congress on Evolutionary Computation (CEC), (2015), 3132–3139. https://doi.org/10.1109/CEC.2015.7257280 |
| [20] |
K. Deb, A. Pratap, S. Agarwal, T. Meyarivan, A fast and elitist multiobjective genetic algorithm: NSGA-II, IEEE Trans. Evol. Comput., 6 (2002), 182–197. https://doi.org/10.1109/4235.996017 doi: 10.1109/4235.996017
|
| [21] |
Q. Zhang, H. Li, MOEA/D: A multiobjective evolutionary algorithm based on decomposition, IEEE Trans. Evol. Comput., 11 (2007), 712–731. https://doi.org/10.1109/TEVC.2007.892759 doi: 10.1109/TEVC.2007.892759
|
| [22] |
N. Srinivas, K. Deb, Muiltiobjective optimization using nondominated sorting in genetic algorithms, Evol. Comput., 2 (1994), 221–248. https://doi.org/10.1162/evco.1994.2.3.221 doi: 10.1162/evco.1994.2.3.221
|
| [23] |
F. Sarro, F. Ferrucci, M. Harman, A. Manna, J. Ren, Adaptive multi-objective evolutionary algorithms for overtime planning in software projects, IEEE Trans. Software Eng., 43 (2017), 898–917. https://doi.org/10.1109/TSE.2017.2650914 doi: 10.1109/TSE.2017.2650914
|
| [24] |
P. Arumugam, E. Amankwah, A. Walker, C. Gerada, Design optimization of a short-term duty electrical machine for extreme environment, IEEE Trans. Ind. Electron., 64 (2017), 9784–9794. https://doi.org/10.1109/TIE.2017.2711555 doi: 10.1109/TIE.2017.2711555
|
| [25] |
J. Zhou, J. Sun, X. Zhou, T. Wei, M. Chen, S. Hu, et al., Resource management for improving soft-error and lifetime reliability of real-time mpsocs, IEEE Trans. Comput. Aided Design Integr. Circuits Syst., 38 (2019), 2215–2228. https://doi.org/10.1109/TCAD.2018.2883993 doi: 10.1109/TCAD.2018.2883993
|
| [26] |
X. Zhang, Y. Tian, R. Cheng, Y. Jin, An efficient approach to nondominated sorting for evolutionary multiobjective optimization, IEEE Trans. Evol. Comput., 19 (2014), 201–213. https://doi.org/10.1109/TEVC.2014.2308305 doi: 10.1109/TEVC.2014.2308305
|
| [27] |
J. Chen, B. Xin, Z. Peng, L. Dou, J. Zhang, Evolutionary decision-makings for the dynamic weapon-target assignment problem, Sci. China Ser. F Inf. Sci., 52 (2009), 2006. https://doi.org/10.1007/s11432-009-0190-x doi: 10.1007/s11432-009-0190-x
|
| [28] |
Y. Wang, B. Xin, J. Chen, An adaptive memetic algorithm for the joint allocation of heterogeneous stochastic resources, IEEE Trans. Cybern., 52 (2021), 11526–11538. https://doi.org/10.1109/TCYB.2021.3087363 doi: 10.1109/TCYB.2021.3087363
|
| [29] |
K. Deb, H. Jain, An evolutionary many-objective optimization algorithm using reference-point-based nondominated sorting approach, part i: Solving problems with box constraints, IEEE Trans. Evol. Comput., 18 (2013), 577–601. https://doi.org/10.1109/TEVC.2013.2281535 doi: 10.1109/TEVC.2013.2281535
|
| [30] |
K. Li, R. Chen, G. Fu, X. Yao, Two-archive evolutionary algorithm for constrained multiobjective optimization, IEEE Trans. Evol. Comput., 23 (2018), 303–315. https://doi.org/10.1109/TEVC.2018.2855411 doi: 10.1109/TEVC.2018.2855411
|
| [31] |
H. Jain, K. Deb, An evolutionary many-objective optimization algorithm using reference-point based nondominated sorting approach, part ii: Handling constraints and extending to an adaptive approach, IEEE Trans. Evol. Comput., 18 (2013), 602–622. https://doi.org/10.1109/TEVC.2013.2281534 doi: 10.1109/TEVC.2013.2281534
|
| [32] |
A. A. Ghanbari, H. Alaei, Meta-heuristic algorithms for resource management in crisis based on OWA approach, Appl. Intell., 51 (2021), 646–657. https://doi.org/10.1007/s10489-020-01808-y doi: 10.1007/s10489-020-01808-y
|
| [33] |
X. Wu, C. Chen, S. Ding, A modified moea/d algorithm for solving bi-objective multi-stage weapon-target assignment problem, IEEE Access, 9 (2021), 71832–71848. https://doi.org/10.1109/ACCESS.2021.3079152 doi: 10.1109/ACCESS.2021.3079152
|
| [34] |
C. A. C. Coello, N. C. Cortés, Solving multiobjective optimization problems using an artificial immune system, Genet. Program. Evol. Mach., 6 (2005), 163–190. https://doi.org/10.1007/s10710-005-6164-x doi: 10.1007/s10710-005-6164-x
|
| [35] | H. Ishibuchi, H. Masuda, Y. Nojima, Sensitivity of performance evaluation results by inverted generational distance to reference points, in 2016 IEEE Congress on Evolutionary Computation (CEC), (2016), 1107–1114. https://doi.org/10.1109/CEC.2016.7743912 |
| [36] |
E. Zitzler, L. Thiele, Multiobjective evolutionary algorithms: A comparative case study and the strength pareto approach, IEEE Trans. Evol. Comput., 3 (1999), 257–271. https://doi.org/10.1109/4235.797969 doi: 10.1109/4235.797969
|
| [37] | K. Deb, S. Jain, Running performance metrics for evolutionary multi-objective optimization, in Proceedings of the Fourth Asia-Pacific Conference on Simulated Evolution and Learning (SEAL'02), (Singapore), (2002), 13–20. https://doi.org/10.1016/S1350-4789(02)80143-X |
| [38] |
M. Srinivas, L. M. Patnaik, Adaptive probabilities of crossover and mutation in genetic algorithms, IEEE Trans. Syst. Man Cybern., 24 (1994), 656–667. https://doi.org/10.1109/21.286385 doi: 10.1109/21.286385
|
| [39] |
W. Xu, C. Chen, S. Ding, P. M. Pardalos, A bi-objective dynamic collaborative task assignment under uncertainty using modified MOEA/D with heuristic initialization, Expert Syst. Appl., 140 (2020), 112844. https://doi.org/10.1016/j.eswa.2019.112844 doi: 10.1016/j.eswa.2019.112844
|
| [40] |
I. Voutchkov, A. Keane, A. Bhaskar, T. M. Olsen, Weld sequence optimization: The use of surrogate models for solving sequential combinatorial problems, Comput. Methods Appl. Mech. Eng., 194 (2005), 3535–3551. https://doi.org/10.1155/IMRN.2005.3551 doi: 10.1155/IMRN.2005.3551
|
| [41] |
W. Luo, J. Lü, K. Liu, L. Chen, Learning-based policy optimization for adversarial missile-target assignment, IEEE Trans. Syst. Man Cybern. Syst., 52 (2021), 4426–4437. https://doi.org/10.1109/TSMC.2021.3096997 doi: 10.1109/TSMC.2021.3096997
|




Figures(5) / Tables(7)

Shiqi Zou, Xiaoping Shi, Shenmin Song. A multi-objective optimization framework with rule-based initialization for multi-stage missile target allocation[J]. Mathematical Biosciences and Engineering, 2023, 20(4): 7088-7112. doi: 10.3934/mbe.2023306







 DownLoad:
DownLoad: