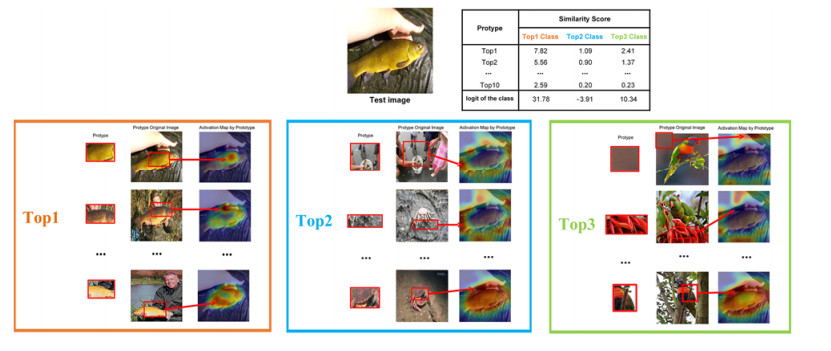
With the increasing application of deep neural networks, their performance requirements in various fields are increasing. Deep neural network models with higher performance generally have a high number of parameters and computation (FLOPs, Floating Point Operations), and have the black-box characteristic. This hinders the deployment of deep neural network models on low-power platforms, as well as sustainable development in high-risk decision-making fields. However, there is little work to ensure the interpretability of the model in the research on the lightweight of the deep neural network model. This paper proposed FAPI-Net (feature augmentation and prototype interpretation), a lightweight interpretable network. It combined feature augmentation convolution blocks and the prototype dictionary interpretability (PDI) module. The feature augmentation convolution block is composed of lightweight feature-map augmentation (FA) modules and a residual connection stack. The FA module could effectively reduce network parameters and computation without losing network accuracy. The PDI module can realize the visualization of model classification reasoning. FAPI-Net is designed regarding MobileNetV3's structure, and our experiments show that the FAPI-Net is more effective than MobileNetV3 and other advanced lightweight CNNs. Params and FLOPs on the ILSVRC2012 dataset are 2 and 20% lower than that on MobileNetV3, respectively, and FAPI-Net with a trainable PDI module has almost no loss of accuracy compared with baseline models. In addition, the ablation experiment on the CIFAR-10 dataset proved the effectiveness of the FA module used in FAPI-Net. The decision reasoning visualization experiments show that FAPI-Net could make the classification decision process of specific test images transparent.
Citation: Xiaoyang Zhao, Xinzheng Xu, Hu Chen, Hansang Gu, Zhongnian Li. FAPI-Net: A lightweight interpretable network based on feature augmentation and prototype interpretation[J]. Mathematical Biosciences and Engineering, 2023, 20(4): 6191-6214. doi: 10.3934/mbe.2023267
With the increasing application of deep neural networks, their performance requirements in various fields are increasing. Deep neural network models with higher performance generally have a high number of parameters and computation (FLOPs, Floating Point Operations), and have the black-box characteristic. This hinders the deployment of deep neural network models on low-power platforms, as well as sustainable development in high-risk decision-making fields. However, there is little work to ensure the interpretability of the model in the research on the lightweight of the deep neural network model. This paper proposed FAPI-Net (feature augmentation and prototype interpretation), a lightweight interpretable network. It combined feature augmentation convolution blocks and the prototype dictionary interpretability (PDI) module. The feature augmentation convolution block is composed of lightweight feature-map augmentation (FA) modules and a residual connection stack. The FA module could effectively reduce network parameters and computation without losing network accuracy. The PDI module can realize the visualization of model classification reasoning. FAPI-Net is designed regarding MobileNetV3's structure, and our experiments show that the FAPI-Net is more effective than MobileNetV3 and other advanced lightweight CNNs. Params and FLOPs on the ILSVRC2012 dataset are 2 and 20% lower than that on MobileNetV3, respectively, and FAPI-Net with a trainable PDI module has almost no loss of accuracy compared with baseline models. In addition, the ablation experiment on the CIFAR-10 dataset proved the effectiveness of the FA module used in FAPI-Net. The decision reasoning visualization experiments show that FAPI-Net could make the classification decision process of specific test images transparent.

| [1] |
S. Ji, J. Li, T. Du, B. Li, A survey of interpretability methods, applications and security of machine learning models, J. Comput. Res. Dev., 56 (2019), 2071–2096. https://doi.org/10.7544/issn1000-1239.2019.20190540 doi: 10.7544/issn1000-1239.2019.20190540

|
| [2] |
J. Zhong, J. Chen, A. Mian, DualConv: Dual convolutional kernels for lightweight deep neural networks, IEEE Trans. Neural Networks Learn. Syst., 2022 (2022), 1–8. https://doi.org/10.1109/TNNLS.2022.3151138 doi: 10.1109/TNNLS.2022.3151138
|
| [3] |
B. Sun, J. Li, M. Shao, Y. Fu, LRPRNet: Lightweight deep network by low-rank pointwise residual convolution, IEEE Trans. Neural Networks Learn. Syst., 2021 (2021), 1–11. https://doi.org/10.1109/TNNLS.2021.3117685 doi: 10.1109/TNNLS.2021.3117685
|
| [4] | A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, et al., Mobilenets: Efficient convolutional neural networks for mobile vision applications, preprint, arXiv: 1704.04861. |
| [5] | M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, L. Chen, Mobilenetv2: Inverted residuals and linear bottlenecks, in Proceedings of IEEE Computer Vision and Pattern Recognition (CVPR), (2018), 4510–4520. https://doi.org/10.48550/arXiv.1801.04381 |
| [6] | A. Howard, R. Pang, H. Adam, Q. V. Le, M. Sandler, B. Chen, et al., Searching for MobileNetV3, in Proceedings of IEEE International Conference on Computer Vision (ICCV), (2019), 1314–1324. https://doi.org/10.1109/ICCV.2019.00140 |
| [7] | X. Zhang, X. Zhou, M. Lin, J. Sun, Shufflenet: An extremely efficient convolutional neural network for mobile devices, in Proceedings of IEEE Computer Vision and Pattern Recognition (CVPR), (2018), 6848–6856. https://doi.org/10.1109/CVPR.2018.00716 |
| [8] | N. Ma, X. Zhang, H. Zheng, J. Sun, ShuffleNet V2: Practical guidelines for efficient cnn architecture design, in Proceedings of the European Conference on Computer Vision (ECCV), (2018), 116–131. https://doi.org/10.48550/arXiv.1807.11164 |
| [9] | Z. Qin, Z. Li, Z. Zhang, Y. Bao, G. Yu, Y. Peng, et al., ThunderNet: Towards real-time generic object detection on mobile devices, in Proceedings of IEEE International Conference on Computer Vision (ICCV), (2019), 6717–6726. https://doi.org/10.1109/ICCV.2019.00682 |
| [10] | F. N. Landola, S. Han, M. W. Moskewicz, K. Ashraf, W. J. Dally, K. Keutzer, SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and < 0.5 MB model size, preprint, arXiv: 1602.07360. |
| [11] | M. Tan, B. Chen, R. Pang, V. Vasudevan, M. Sandler, A. Howard, et al., MnasNet: Platform-aware neural architecture search for mobile, in Proceedings of IEEE Computer Vision and Pattern Recognition (CVPR), (2019), 2820–2828. https://doi.org/10.1109/CVPR.2019.00293 |
| [12] | M. Tan, Q. V. Le, EfficientNet: Rethinking model scaling for convolutional neural networks, in Proceedings of the 36th International Conference on Machine Learning (ICML), 97 (2019), 6105–6114. https://doi.org/10.48550/arXiv.1905.11946 |
| [13] |
Q. Zhao, J. Liu, B. Zhang, S. Lyu, N. Raoof, W. Feng, Interpretable relative squeezing bottleneck design for compact convolutional neural networks model, Image Vis. Comput., 89 (2019), 276–288. https://doi.org/10.1016/j.imavis.2019.06.006 doi: 10.1016/j.imavis.2019.06.006
|
| [14] |
B. Jiang, S. Chen, B. Wang, B. Luo, MGLNN: Semi-supervised learning via multiple graph cooperative learning neural networks, Neural Networks, 153 (2022), 204–214. https://doi.org/10.1016/j.neunet.2022.05.024 doi: 10.1016/j.neunet.2022.05.024
|
| [15] |
A. M. Roy, J. Bhaduri, T. Kumar, K. Raj, WilDect-YOLO: An efficient and robust computer vision-based accurate object localization model for automated endangered wildlife detection, Ecol. Inf., 2022 (2022), 101919. https://doi.org/10.1016/j.ecoinf.2022.101919 doi: 10.1016/j.ecoinf.2022.101919
|
| [16] | A. Chandio, G. Gui, T. Kumar, I. Ullah, R. Ranjbarzadeh, A. M. Roy, et al., Precise single-stage detector, preprint, arXiv: 2210.04252. |
| [17] | B. Kim, M. Wattenberg, J. Gilmer, C. J. Cai, J. Wexler, F. B. Viégas, et al., Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (TCAV), in Proceedings of the 35th International Conference on Machine Learning (ICML), 80 (2018), 2673–2682. https://doi.org/10.48550/arXiv.1711.11279 |
| [18] | A. Ghorbani, J. Wexler, J. Y. Zou, B. Kim, Towards automatic concept-based explanations, in Proceedings of Neural Information Processing Systems (NeurIPS), (2019), 9273–9282. https://doi.org/10.48550/arXiv.1902.03129 |
| [19] | Y. Ge, Y. Xiao, Z. Xu, M. Zheng, S. Karanam, T. Chen, et al., A peek into the reasoning of neural networks: Interpreting with structural visual concepts, in Proceedings of IEEE Computer Vision and Pattern Recognition (CVPR), (2021), 2195–2204. https://doi.org/10.48550/arXiv.2105.00290 |
| [20] | C. Seifert, A. Aamir, A. Balagopalan, D. Jain, A. Sharma, S. Grottel, et al., Visualizations of deep neural networks in computer vision: A survey, in Transparent Data Mining for Big and Small Data (SBD), 32 (2017), 123–144. https://doi.org/10.1007/978-3-319-54024-5_6 |
| [21] | W. Samek, T. Wiegand, K. Müller, Explainable artificial intelligence: Understanding, visualizing and interpreting deep learning models, preprint, arXiv: 1708.08296. |
| [22] | W. Samek, G. Montavon, S. Lapuschkin, C. J. Anders, K. Müller, Toward interpretable machine learning: Transparent deep neural networks and beyond, preprint, arXiv: 2003.07631. |
| [23] | K. Simonyan, A. Vedaldi, A. Zisserman, Deep inside convolutional networks: Visualising image classification models and saliency maps, preprint, arXiv: 1312.6034. |
| [24] | Z. Qi, S. Khorram, F. Li, Visualizing deep networks by optimizing with integrated gradients, in Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), (2020), 11890–11898. https://doi.org/10.1609/aaai.v34i07.6863 |
| [25] | B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, A. Torralba, Learning deep features for discriminative localization, in Proceedings of IEEE Computer Vision and Pattern Recognition (CVPR), (2016), 2921–2929. https://doi.org/10.1109/CVPR.2016.319 |
| [26] | R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, D. Batra, Grad-CAM: Visual explanations from deep networks via gradient-based localization, in Proceedings of IEEE International Conference on Computer Vision (ICCV), (2017), 618–626. https://doi.org/10.1109/ICCV.2017.74 |
| [27] | A. Chattopadhyay, A. Sarkar, P. Howlader, V. N. Balasubramanian, Grad-CAM++: Generalized gradient-based visual explanations for deep convolutional networks, in Proceedings of the 18th IEEE Winter Conference on Applications of Computer Vision (WACV), (2018), 839–847. https://doi.org/10.1109/WACV.2018.00097 |
| [28] | H. Wang, Z. Wang, M. Du, F. Yang, Z. Zhang, S. Ding, et al., Score-CAM: Score-weighted visual explanations for convolutional neural networks, in Proceedings of IEEE Computer Vision and Pattern Recognition Workshops (CVPRW), (2020), 111–119. https://doi.org/10.48550/arXiv.1910.01279 |
| [29] | J. R. Lee, S. Kim, I. Park, T. Eo, D. Hwang, Relevance-CAM: Your model already knows where to look, in Proceedings of IEEE Computer Vision and Pattern Recognition (CVPR), (2021), 14944–14953. https://doi.org/10.1109/CVPR46437.2021.01470 |
| [30] | D. Bahdanau, K. Cho, Y. Bengio, Neural machine translation by jointly learning to align and translate, preprint, arXiv: 1409.0473. |
| [31] | W. Shen, Z. Wei, S. Huang, B. Zhang, J. Fan, P. Zhao, et al., Interpretable compositional convolutional neural networks, in Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence (IJCAI), (2021), 2971–2978. https://doi.org/10.24963/ijcai.2021/409 |
| [32] | R. Wang, X. Wang, D. I. Inouye, Shapley explanation networks, preprint, arXiv: 2104.02297. |
| [33] | W. Stammer, M. Memmel, P. Schramowski, K. Kersting, Interactive disentanglement: Learning concepts by interacting with their prototype representations, in Proceedings of IEEE Computer Vision and Pattern Recognition (CVPR), (2022), 10317–10328. https://doi.org/10.1109/CVPR52688.2022.01007 |
| [34] | H. Yang, Z. Shen, Y. Zhao, AsymmNet: Towards ultralight convolution neural networks using asymmetrical bottlenecks, in Proceedings of IEEE Computer Vision and Pattern Recognition Workshops (CVPRW), (2021), 2339–2348. https://doi.org/10.1109/CVPRW53098.2021.00266 |
| [35] | K. Han, Y. Wang, Q. Tian, J. Guo, C. Xu, C. Xu, Ghostnet: More features from cheap operations, in Proceedings of IEEE Computer Vision and Pattern Recognition (CVPR), (2020), 1577–1586. https://doi.org/10.1109/CVPR42600.2020.00165 |
| [36] | M. Tan, Q. V. Le, MixConv: Mixed depthwise convolutional kernels, in Proceedings of British Machine Vision Conference (BMVC), (2019), 74. https://doi.org/10.48550/arXiv.1907.09595 |
| [37] | M. D. Zeiler, R. Fergus, Visualizing and understanding convolutional networks, in Proceedings of the European Conference on Computer Vision (ECCV), (2014), 818–833. https://doi.org/10.48550/arXiv.1311.2901 |
| [38] | C. Chen, O. Li, D. Tao, A. Barnett, C. Rudin, J. Su, This looks like that: Deep learning for interpretable image recognition, in Proceedings of Neural Information Processing Systems (NeurIPS), (2019), 8928–8939. https://doi.org/10.48550/arXiv.1806.10574 |
| [39] | B. Kim, O. Koyejo, R. Khanna, Examples are not enough, learn to criticize! criticism for interpretability, in Proceedings of Neural Information Processing Systems (NeurIPS), (2016), 2280–2288. https://dl.acm.org/doi/abs/10.5555/3157096.3157352 |
| [40] | A. Krizhevsky, G. Hinton, Learning Multiple Layers of Features from Tiny Images, Technical Report, Citeseer, 2009. |
| [41] | J. Deng, W. Dong, R. Socher, L. Li, K. Li, F. Li, Imagenet: A large-scale hierarchical image database, in Proceedings of IEEE Computer Vision and Pattern Recognition (CVPR), (2009), 248–255. https://doi.org/10.1109/CVPR.2009.5206848 |
| [42] | G. Huang, Z. Liu, L. V. D. Maaten, K. Q. Weinberger, Densely connected convolutional networks, in Proceedings of IEEE Computer Vision and Pattern Recognition (CVPR), (2017), 2261–2269. https://doi.org/10.48550/arXiv.1608.06993 |
| [43] | C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, Z. Wojna, Rethinking the inception architecture for computer vision, in Proceedings of IEEE Computer Vision and Pattern Recognition (CVPR), (2016), 2818–2826. https://doi.org/10.1109/CVPR.2016.308 |






Figures(11) / Tables(5)

Xiaoyang Zhao, Xinzheng Xu, Hu Chen, Hansang Gu, Zhongnian Li. FAPI-Net: A lightweight interpretable network based on feature augmentation and prototype interpretation[J]. Mathematical Biosciences and Engineering, 2023, 20(4): 6191-6214. doi: 10.3934/mbe.2023267







 DownLoad:
DownLoad: