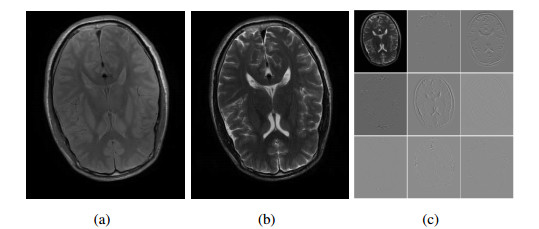
Magnetic resonance (MR) image enhancement technology can reconstruct high-resolution image from a low-resolution image, which is of great significance for clinical application and scientific research. T1 weighting and T2 weighting are the two common magnetic resonance imaging modes, each of which has its own advantages, but the imaging time of T2 is much longer than that of T1. Related studies have shown that they have very similar anatomical structures in brain images, which can be utilized to enhance the resolution of low-resolution T2 images by using the edge information of high-resolution T1 images that can be rapidly imaged, so as to shorten the imaging time needed for T2 images. In order to overcome the inflexibility of traditional methods using fixed weights for interpolation and the inaccuracy of using gradient threshold to determine edge regions, we propose a new model based on previous studies on multi-contrast MR image enhancement. Our model uses framelet decomposition to finely separate the edge structure of the T2 brain image, and uses the local regression weights calculated from T1 image to construct a global interpolation matrix, so that our model can not only guide the edge reconstruction more accurately where the weights are shared, but also carry out collaborative global optimization for the remaining pixels and their interpolated weights. Experimental results on a set of simulated MR data and two sets of real MR images show that the enhanced images obtained by the proposed method are superior to the compared methods in terms of visual sharpness or qualitative indicators.
Citation: Yingying Xu, Songsong Dai, Haifeng Song, Lei Du, Ying Chen. Multi-modal brain MRI images enhancement based on framelet and local weights super-resolution[J]. Mathematical Biosciences and Engineering, 2023, 20(2): 4258-4273. doi: 10.3934/mbe.2023199
Magnetic resonance (MR) image enhancement technology can reconstruct high-resolution image from a low-resolution image, which is of great significance for clinical application and scientific research. T1 weighting and T2 weighting are the two common magnetic resonance imaging modes, each of which has its own advantages, but the imaging time of T2 is much longer than that of T1. Related studies have shown that they have very similar anatomical structures in brain images, which can be utilized to enhance the resolution of low-resolution T2 images by using the edge information of high-resolution T1 images that can be rapidly imaged, so as to shorten the imaging time needed for T2 images. In order to overcome the inflexibility of traditional methods using fixed weights for interpolation and the inaccuracy of using gradient threshold to determine edge regions, we propose a new model based on previous studies on multi-contrast MR image enhancement. Our model uses framelet decomposition to finely separate the edge structure of the T2 brain image, and uses the local regression weights calculated from T1 image to construct a global interpolation matrix, so that our model can not only guide the edge reconstruction more accurately where the weights are shared, but also carry out collaborative global optimization for the remaining pixels and their interpolated weights. Experimental results on a set of simulated MR data and two sets of real MR images show that the enhanced images obtained by the proposed method are superior to the compared methods in terms of visual sharpness or qualitative indicators.

| [1] |
L. Hua, Y. Gu, X. Gu, J. Xue, T. Ni, A novel brain MRI image segmentation method using an improved multi-view fuzzy c-means clustering algorithm, Front. Neurosci., 15 (2021), 662674. https://doi.org/10.3389/fnins.2021.662674 doi: 10.3389/fnins.2021.662674

|
| [2] | A. Hatamizadeh, V. Nath, Y. Tang, D. Yang, H. R. Roth, D. Xu, Swin UNETR: Swin transformers for semantic segmentation of brain tumors in MRI images, in International MICCAI Brainlesion Workshop, Springer, (2022), 272–284. https://doi.org/10.1007/978-3-031-08999-2_22 |
| [3] |
H. Greenspan, Super-resolution in medical imaging, Comput. J., 52 (2009), 43–63. https://doi.org/10.1093/comjnl/bxm075 doi: 10.1093/comjnl/bxm075
|
| [4] |
D. Qiu, Y. Cheng, X. Wang, Gradual back-projection residual attention network for magnetic resonance image super-resolution, Comput. Meth. Prog. Bio., 208 (2021), 106252. https://doi.org/10.1016/j.cmpb.2021.106252 doi: 10.1016/j.cmpb.2021.106252
|
| [5] |
L. Wang, H. Zhu, Z. He, Y. Jia, J. Du, Adjacent slices feature transformer network for single anisotropic 3D brain MRI image super-resolution, Biomed. Signal Proces., 72 (2022), 103339. https://doi.org/10.1016/j.bspc.2021.103339 doi: 10.1016/j.bspc.2021.103339
|
| [6] | R. Keys, Cubic convolution interpolation for digital image processing, in IEEE Transactions on Acoustics, Speech and Signal Processing, IEEE: Piscataway, (1981), 1153–1160. https://doi.org/10.1109/TASSP.1981.1163711 |
| [7] |
X. Li, M. Orchard, New edge-directed interpolation, IEEE T. Image Process., 10 (2001), 1521–1527. https://doi.org/10.1109/83.951537 doi: 10.1109/83.951537
|
| [8] |
J. Manjón, P. Coupé, A. Buades, V. Fonov, D. L. Collins, M. Robles, Non-local MRI upsampling, Med. Image Anal., 14 (2010), 784–792. https://doi.org/10.1016/j.media.2010.05.010 doi: 10.1016/j.media.2010.05.010
|
| [9] |
Z. Wei, K.-K. Ma, Contrast-guided image interpolation, IEEE T. Image Process., 22 (2013), 4271–4285. https://doi.org/10.1109/TIP.2013.2271849 doi: 10.1109/TIP.2013.2271849
|
| [10] |
F. Shi, J. Cheng, L. Wang, P. T. Yap, D. Shen, LRTV: MR image super-resolution with low-rank and total variation regularizations, IEEE T. Med. Imaging, 34 (2015), 2459–2466. https://doi.org/10.1109/TMI.2015.2437894 doi: 10.1109/TMI.2015.2437894
|
| [11] |
S. Tourbier, X. Bresson, P. Hagmann, J. P. Thiran, R. Meuli, M. B. Cuadra, An efficient total variation algorithm for super-resolution in fetal brain MRI with adaptive regularization, NeuroImage, 118 (2015), 584–597. https://doi.org/10.1016/j.neuroimage.2015.06.018 doi: 10.1016/j.neuroimage.2015.06.018
|
| [12] |
A. Rueda, N. Malpica, E. Romero, Single-image super-resolution of brain MR images using overcomplete dictionaries, Med. Image Anal., 17 (2013), 113–132. https://doi.org/10.1016/j.media.2012.09.003 doi: 10.1016/j.media.2012.09.003
|
| [13] |
D. Zhang, J. He, Y. Zhao, M. Du, MR image super-resolution reconstruction using sparse representation, nonlocal similarity and sparse derivative prior, Comput. Biol. Med., 58 (2015), 130–145. https://doi.org/10.1016/j.compbiomed.2014.12.023 doi: 10.1016/j.compbiomed.2014.12.023
|
| [14] |
Y. Jia, Z. He, A. Gholipour, S. K. Warfield, Single anisotropic 3-D MR image upsampling via overcomplete dictionary trained from in-plane high resolution slices, IEEE J. Biomed. Health, 20 (2016), 1552–1561. https://doi.org/10.1109/JBHI.2015.2470682 doi: 10.1109/JBHI.2015.2470682
|
| [15] |
Y. Jia, A. Gholipour, Z. He, S. K. Warfield, A new sparse representation framework for reconstruction of an isotropic high spatial resolution MR volume from orthogonal anisotropic resolution scans, IEEE T. Med. Imaging, 36 (2017), 1182–1193. https://doi.org/10.1109/TMI.2017.2656907 doi: 10.1109/TMI.2017.2656907
|
| [16] | Y. Huang, L. Shao, A. F. Frangi, Simultaneous super-resolution and cross-modality synthesis of 3d medical images using weakly-supervised joint convolutional sparse coding, in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2017), 6070–6079. |
| [17] | Y. Chen, Y. Xie, Z. Zhou, F. Shi, A. G. Christodoulou, D. Li, Brain MRI super resolution using 3D deep densely connected neural networks, in 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), IEEE, 2018,739–742. https://doi.org/10.1109/ISBI.2018.8363679 |
| [18] |
J. Shi, Z. Li, S. Ying, C. Wang, Q. Liu, Q. Zhang, et al., MR image super-resolution via wide residual networks with fixed skip connection, IEEE J. Biomed. Health, 23 (2019), 1129–1140. https://doi.org/10.1109/JBHI.2018.2843819 doi: 10.1109/JBHI.2018.2843819
|
| [19] |
X. Zhao, X. Hu, Y. Liao, T. He, T. Zhang, X. Zou, et al., Accurate MR image super-resolution via lightweight lateral inhibition network, Comput. Vis. Image Und., 201 (2020), 103075. https://doi.org/10.1016/j.cviu.2020.103075 doi: 10.1016/j.cviu.2020.103075
|
| [20] |
M. Jiang, M. Zhi, L. Wei, X. Yang, J. Zhang, Y. Li, et al., FA-GAN: Fused attentive generative adversarial networks for MRI image super-resolution, Comput. Med. Imag. Grap., 92 (2021), 101969. https://doi.org/10.1016/j.compmedimag.2021.101969 doi: 10.1016/j.compmedimag.2021.101969
|
| [21] |
H. Song, W. Yang, GSCCTL: A general semi-supervised scene classification method for remote sensing images based on clustering and transfer learning, Int. J. Remote Sens., 2021 (2021), 1–25. https://doi.org/10.1080/01431161.2021.2019851 doi: 10.1080/01431161.2021.2019851
|
| [22] |
Z. Wang, J. Chen, S. C. Hoi, Deep learning for image super-resolution: A survey, IEEE T. Pattern Anal., 43 (2021), 3365–3387. https://doi.org/10.1109/TPAMI.2020.2982166 doi: 10.1109/TPAMI.2020.2982166
|
| [23] |
Y. Li, B. Sixou, F. Peyrin, A review of the deep learning methods for medical images super resolution problems, IRBM, 42 (2021), 120–133. https://doi.org/10.1016/j.irbm.2020.08.004 doi: 10.1016/j.irbm.2020.08.004
|
| [24] |
Q. Lyu, H. Shan, C. Steber, C. Helis, C. Whitlow, M. Chan, et al., Multi-contrast super-resolution MRI through a progressive network, IEEE Trans. Med. Imag., 39 (2020), 2738–2749. https://doi.org/10.1109/TMI.2020.2974858 doi: 10.1109/TMI.2020.2974858
|
| [25] |
Q. Lyu, H. Shan, G. Wang, MRI super-resolution with ensemble learning and complementary priors, IEEE Trans. Comput. Imag., 6 (2020), 615–624. https://doi.org/10.1109/TCI.2020.2964201 doi: 10.1109/TCI.2020.2964201
|
| [26] | B. M. Dale, M. A. Brown, R. C. Semelka, MRI: Basic Principles and Applications. John Wiley & Sons, 2015. |
| [27] |
S. Rathore, A. Abdulkadir, C. Davatzikos, Analysis of MRI data in diagnostic neuroradiology, Annu. Rev. Biomed. Data Sci., 3 (2020), 365–390. https://doi.org/https://doi.org/10.1146/annurev-biodatasci-022620-015538 doi: 10.1146/annurev-biodatasci-022620-015538
|
| [28] | F. Rousseau, Brain hallucination, in European Conference on Computer Vision, Springer, (2008), 497–508. https://doi.org/10.1007/978-3-540-88682-2_38 |
| [29] |
F. Rousseau, A non-local approach for image super-resolution using intermodality priors, Med. Image Anal., 14 (2010), 594–605. https://doi.org/10.1016/j.media.2010.04.005 doi: 10.1016/j.media.2010.04.005
|
| [30] |
J. V. Manjón, P. Coupé, A. Buades, D. L. Collins, M. Robles, MRI superresolution using self-similarity and image priors, Int. J. Biomed. Imag., 2010 (2010), 1–11. https://doi.org/10.1155/2010/425891 doi: 10.1155/2010/425891
|
| [31] |
K. Jafari-Khouzani, MRI upsampling using feature-based nonlocal means approach, IEEE Trans. Med. Imag., 33 (2014), 1969–1985. https://doi.org/10.1109/TMI.2014.2329271 doi: 10.1109/TMI.2014.2329271
|
| [32] |
X. Lu, Z. Huang, Y. Yuan, MR image super-resolution via manifold regularized sparse learning, Neurocomputing, 162 (2015), 96–104. https://doi.org/10.1016/j.neucom.2015.03.065 doi: 10.1016/j.neucom.2015.03.065
|
| [33] |
H. Zheng, X. Qu, Z. Bai, Y. Liu, D. Guo, J. Dong, et al., Multi-contrast brain magnetic resonance image super-resolution using the local weight similarity, BMC Med. Imag., 17 (2017). https://doi.org/10.1186/s12880-016-0176-2 doi: 10.1186/s12880-016-0176-2
|
| [34] |
H. Zheng, K. Zeng, D. Guo, J. Ying, Y. Yang, X. Peng, et al., Multi-contrast brain MRI image super-resolution with gradient-guided edge enhancement, IEEE Access, 6 (2018), 57856–57867. https://doi.org/10.1109/ACCESS.2018.2873484 doi: 10.1109/ACCESS.2018.2873484
|
| [35] |
Y. R. Li, R. H. Chan, L. Shen, X. Zhuang, Regularization with multilevel non-stationary tight framelets for image restoration, Appl. Comput. Harmon. Anal., 53 (2021), 332–348. https://doi.org/10.1016/j.acha.2021.03.003 doi: 10.1016/j.acha.2021.03.003
|
| [36] |
Y. R. Li, R. H. Chan, L. Shen, Y. C. Hsu, W.-Y. Isaac Tseng, An adaptive directional haar framelet-based reconstruction algorithm for parallel magnetic resonance imaging, SIAM J. Imag. Sci., 9 (2016), 794–821. https://doi.org/10.1137/15M1033964 doi: 10.1137/15M1033964
|
| [37] |
Y. R. Li, L. Shen, X. Zhuang, A tailor-made 3-dimensional directional haar semi-tight framelet for pMRI reconstruction, Appl. Comput. Harmon. Anal., 60 (2022), 446–470. https://doi.org/10.1016/j.acha.2022.04.003 doi: 10.1016/j.acha.2022.04.003
|
| [38] |
A. Ron, Z. Shen, Affine systems in $l_2(\mathbb{R}^d)$: The analysis of the analysis operator, J. Funct. Anal., 148 (1997), 408–447. https://doi.org/10.1006/jfan.1996.3079 doi: 10.1006/jfan.1996.3079
|
| [39] | E. Esser, Primal Dual Algorithms for Convex Models and Applications to Image Restoration, Registration and Nonlocal Inpainting, PhD thesis, University of California in Los Angeles, 2010. |
| [40] | C. A. Cocosco, V. Kollokian, K. S. Kwan, A. C. Evans, I. Centre, Brain Web: Online interface to a 3D MRI simulated brain database, NeuroImage, 5 (1997). |
| [41] |
Z. Wang, A. C. Bovik, H. R. Sheikh, E. P. Simoncelli, Image quality assessment: from error visibility to structural similarity, IEEE Trans. Image Process., 13 (2004), 600–612. https://doi.org/10.1109/TIP.2003.819861 doi: 10.1109/TIP.2003.819861
|
| [42] |
S. Boyd, N. Parikh, E. Chu, B. Peleato, J. Eckstein, Distributed optimization and statistical learning via the alternating direction method of multipliers, Foundations and Trends® in Machine Learning, 3 (2011), 1–122. https://doi.org/10.1561/2200000016 doi: 10.1561/2200000016
|






Figures(7) / Tables(2)

Yingying Xu, Songsong Dai, Haifeng Song, Lei Du, Ying Chen. Multi-modal brain MRI images enhancement based on framelet and local weights super-resolution[J]. Mathematical Biosciences and Engineering, 2023, 20(2): 4258-4273. doi: 10.3934/mbe.2023199







 DownLoad:
DownLoad: