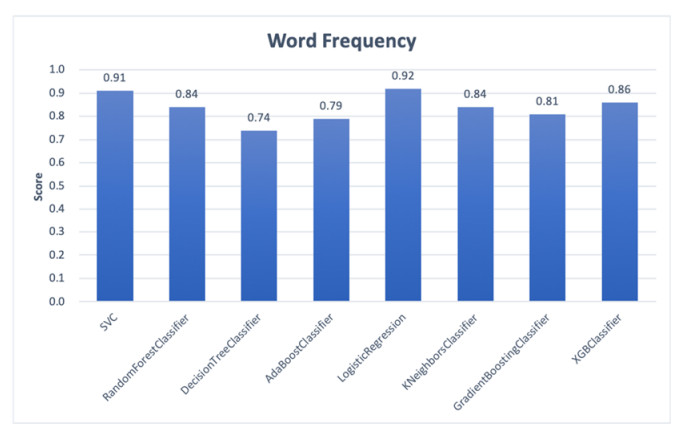
Recent decades have witnessed the rapid development of literary studies on gender and writing style. One of the common limitations of previous studies is that they analyze only a few texts, which some researchers have already pointed out. In this study, we attempt to find the features that best facilitate the classification of texts by authorial gender. Based on a corpus of 1113 classical fictions from the early 19th century to the early 20th century. Eight algorithms, including SVM, random forest, decision tree, AdaBoost, logistic regression, K-nearest neighbors, gradient boosting and XGBoost, are used to automatically select the features that are most useful for properly categorizing a text. We find that word frequency is the most important predictor for identifying authorial gender in classical fictions, achieving an accuracy rate of 92%. We also find that nationhood is not particularly impactful when dealing with authorial gender differences in classical fictions, as genderlectal variation is 'universal' in the English-speaking world.
Citation: Dan Zhu, Liru Yang, Xin Liang. Gender classification in classical fiction: A computational analysis of 1113 fictions[J]. Mathematical Biosciences and Engineering, 2022, 19(9): 8892-8907. doi: 10.3934/mbe.2022412
Recent decades have witnessed the rapid development of literary studies on gender and writing style. One of the common limitations of previous studies is that they analyze only a few texts, which some researchers have already pointed out. In this study, we attempt to find the features that best facilitate the classification of texts by authorial gender. Based on a corpus of 1113 classical fictions from the early 19th century to the early 20th century. Eight algorithms, including SVM, random forest, decision tree, AdaBoost, logistic regression, K-nearest neighbors, gradient boosting and XGBoost, are used to automatically select the features that are most useful for properly categorizing a text. We find that word frequency is the most important predictor for identifying authorial gender in classical fictions, achieving an accuracy rate of 92%. We also find that nationhood is not particularly impactful when dealing with authorial gender differences in classical fictions, as genderlectal variation is 'universal' in the English-speaking world.

| [1] |
R. Lakoff, Language and woman's place, Lang. Soc., 2 (1973), 45–79. https://doi.org/10.1017/S0047404500000051 doi: 10.1017/S0047404500000051

|
| [2] |
J. Holmes, Women's talk: The question of sociolinguistic universals, Aust. J. Commun., 20 (1993), 125–149. https://doi.org/10.5588/pha.15.0018 doi: 10.5588/pha.15.0018
|
| [3] |
E. J. Aries, F. L. Johnson, Close friendship in adulthood: Conversational content between same-sex friends, Sex Roles, 9 (1983), 1183–1196. https://doi.org/10.1007/bf00303101 doi: 10.1007/bf00303101
|
| [4] | D. Tannen, Rethinking power and solidarity in gender and dominance, in Proceedings of the Annual Meeting of the Berkeley Linguistics Society, 16 (1990), 519. https://doi.org/10.3765/bls.v16i1.3433 |
| [5] | J. Holmes, Women's language: A functional approach, Gen. Ling., 24 (1984), 149. |
| [6] |
J. Holmes, Paying compliments: A sex-preferential positive politeness strategy, J. Pragmatics, 12 (1988), 445–465. https://doi.org/10.1016/0378-2166(88)90005-7 doi: 10.1016/0378-2166(88)90005-7
|
| [7] |
J. Holmes, Sex differences and apologies: One aspect of communicative competence, Appl. Ling., 10 (1989), 194–213. https://doi.org/10.1093/applin/10.2.194 doi: 10.1093/applin/10.2.194
|
| [8] |
C. L. Berryman-Fink, J. R. Wilcox, A multivariate investigation of perceptual attributions concerning gender appropriateness in language, Sex Roles, 9(1983), 663–681. https://doi.org/10.1007/BF00289796 doi: 10.1007/BF00289796
|
| [9] |
J. A. Simkins-Bullock, B. G. Wildman, An investigation into the relationship between gender and language, Sex Roles, 24 (1991), 149–160. https://doi.org/10.1007/BF00288888 doi: 10.1007/BF00288888
|
| [10] |
S. Argamon, M. Koppel, J. Fine, A. R. Shimoni, Gender, genre, and writing style in formal written texts, Text, 23 (2003), 321–346. https://doi.org/10.1515/text.2003.014 doi: 10.1515/text.2003.014
|
| [11] | J. D. Burger, J. C. Henderson, G. Kim, G. Zarrella, Discriminating gender on twitter, in Conference on Empirical Methods in Natural Language Processing, (2011), 1301–1309. Available from: https://dblp.uni-trier.de/rec/conf/emnlp/BurgerHKZ11.html. |
| [12] | R. Sarawgi, K. Gajulapalli, Y. Choi, Gender attribution: Tracing stylometric evidence beyond topic and genre, in Proceedings of the Fifteenth Conference on Computational Natural Language Learning, (2011), 78–86. Available from: https://dblp.uni-trier.de/db/conf/conll/conll2011.html. |
| [13] |
M. Dahllöf, Automatic prediction of gender, political affiliation, and age in Swedish politicians from the wording of their speeches—A comparative study of classifiability, Lit. Ling. Comput., 27 (2012), 139–153. https://doi.org/10.1093/llc/fqs010 doi: 10.1093/llc/fqs010
|
| [14] |
B. Yu, Language and gender in Congressional speech, Lit, Ling, Comput., 29 (2014), 118–132. https://doi.org/10.1093/llc/fqs073 doi: 10.1093/llc/fqs073
|
| [15] | D. L. Hoover, Textual analysis, in Literary Studies in the Digital Age (eds. K. M. Price and R. Siemens), 2013. Available from: http://dlsanthology.commons.mla.org/textual-analysis/. |
| [16] |
M. L. Newman, C. J. Groom, L. D. Handelman, J. W. Pennebaker, Gender differences in language use: An analysis of 14,000 text samples, Discourse Processes, 45 (2008), 211–236. https://doi.org/10.1080/01638530802073712 doi: 10.1080/01638530802073712
|
| [17] | J. Pennebaker, The Secret Life of Pronouns: What Our Words Say about Us, Bloomsbury Press, London, (2011), 56. https://doi.org/10.1093/llc/fqt006 |
| [18] | P. Baker, Using Corpora to Analyze Gender, Bloomsbury, London, 2014. https://doi.org/10.1016/j.system.2016.04.008 |
| [19] | G. Flaubert, The Letters of Gustave Flaubert, 1830–1857, Harvard University Press, 1980. |
| [20] |
M. Koppel, S. Argamon, A. R. Shimoni, Automatically categorizing written texts by author gender, Lit. Ling. Comput., 17 (2003), 401–412. https://doi.org/10.1093/llc/17.4.401 doi: 10.1093/llc/17.4.401
|
| [21] | M. Jockers, Macroanalysis: Digital Methods and Literary History, University of Illinois Press, Urbana, (2013), 93–99,133. https://doi.org/10.5406/illinois/9780252037528.001.0001 |
| [22] |
J. Rybicki, Vive la difference: Tracing the (authorial) gender signal by multivariate analysis of word frequencies, Digital Scholarship Humanit., 31 (2016), 746–761. https://doi.org/10.1093/llc/fqv023 doi: 10.1093/llc/fqv023
|
| [23] |
S. G. Weidman, J. O'Sullivan, The limits of distinctive words: Re-evaluating literature's gender marker debate, Digital Scholarship Humanit., 33 (2018), 374–390. https://doi.org/10.1093/llc/fqx017 doi: 10.1093/llc/fqx017
|
| [24] | S. Grayson, M. Mulvany, K. Wade, G. Meaney, D. Greene, Exploring the role of gender in 19th century fiction through the lens of word embeddings, in 1st International Conference on Language, Data and Knowledge, (2017), 358–364. Available from: https://linkspringer.53yu.com/chapter/10.1007/978-3-319-59888-8_30. |
| [25] |
V. Bergvall, Rethinking language and gender research: Theory and practice, J. Pragmatics, 29 (1996), 213–220. https://doi.org/10.1016/S0378-2166(97)82076-0 doi: 10.1016/S0378-2166(97)82076-0
|
| [26] |
R. Potter, Literary criticism and literary computing, Comput. Humanit., 22 (1988), 91–97. https://doi.org/10.2307/30200105 doi: 10.2307/30200105
|
| [27] | J, Gottschall, Literature, Science, and a New Humanities, Palgrave Macmillan, New York, 2008. https://doi.org/10.1057/9780230615595 |
| [28] | L. Cassuto, C. V. Eby, B. Reiss, The Cambridge History of the American Novel, Cambridge University Press, 2011. https://doi.org/10.1017/CHOL9780521899079 |
| [29] | J. Bender, D. David, M. Seidel, The Columbia History of the British Novel, Columbia University Press, 1994. https://doi.org/10.2307/3508695 |
| [30] |
A. A. Augustine, M. R. Mehl, R. J. Larsen, A positivity bias in written and spoken English and its moderation by personality and gender, Social Psychol. Pers. Sci., 2 (2011), 508–515. https://doi.org/10.1177/1948550611399154 doi: 10.1177/1948550611399154
|
| [31] |
S. Luoto, Sexual dimorphism in language, and the gender shift hypothesis of homosexuality, Front. Psychol., 12 (2021), 1665. https://doi.org/10.3389/fpsyg.2021.639887 doi: 10.3389/fpsyg.2021.639887
|











Figures(12) / Tables(2)

Dan Zhu, Liru Yang, Xin Liang. Gender classification in classical fiction: A computational analysis of 1113 fictions[J]. Mathematical Biosciences and Engineering, 2022, 19(9): 8892-8907. doi: 10.3934/mbe.2022412







 DownLoad:
DownLoad: