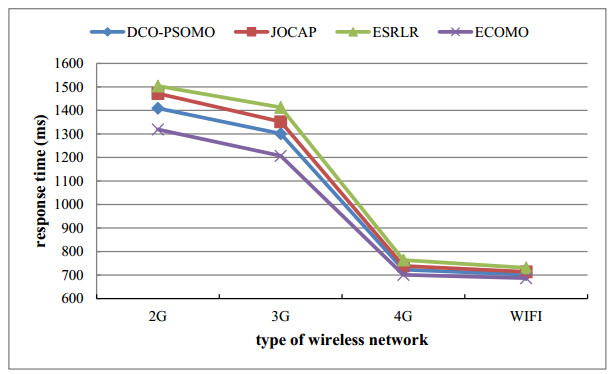
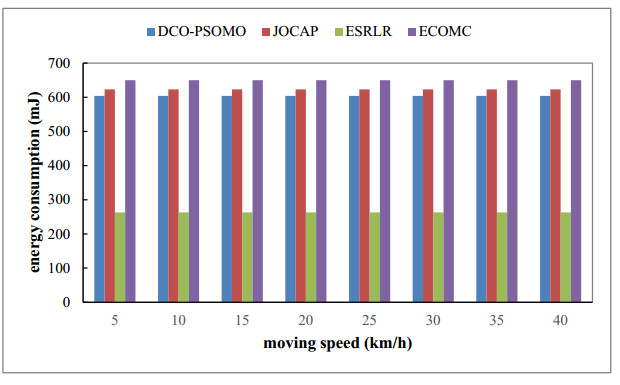
The current computation offloading algorithm for the mobile cloud ignores the selection of offloading opportunities and does not consider the uninstall frequency, resource waste, and energy efficiency reduction of the user's offloading success probability. Therefore, in this study, a dynamic computation offloading algorithm based on particle swarm optimization with a mutation operator in a multi-access edge computing environment is proposed (DCO-PSOMO). According to the CPU utilization and the memory utilization rate of the mobile terminal, this method can dynamically obtain the overload time by using a strong, locally weighted regression method. After detecting the overload time, the probability of successful downloading is predicted by the mobile user's dwell time and edge computing communication range, and the offloading is either conducted immediately or delayed. A computation offloading model was established via the use of the response time and energy consumption of the mobile terminal. Additionally, the optimal computing offloading algorithm was designed via the use of a particle swarm with a mutation operator. Finally, the DCO-PSOMO algorithm was compared with the JOCAP, ECOMC and ESRLR algorithms, and the experimental results demonstrated that the DCO-PSOMO offloading method can effectively reduce the offloading cost and terminal energy consumption, and improves the success probability of offloading and the user's QoS.
Citation: Yanpei Liu, Wei Huang, Liping Wang, Yunjing Zhu, Ningning Chen. Dynamic computation offloading algorithm based on particle swarm optimization with a mutation operator in multi-access edge computing[J]. Mathematical Biosciences and Engineering, 2021, 18(6): 9163-9189. doi: 10.3934/mbe.2021452
The current computation offloading algorithm for the mobile cloud ignores the selection of offloading opportunities and does not consider the uninstall frequency, resource waste, and energy efficiency reduction of the user's offloading success probability. Therefore, in this study, a dynamic computation offloading algorithm based on particle swarm optimization with a mutation operator in a multi-access edge computing environment is proposed (DCO-PSOMO). According to the CPU utilization and the memory utilization rate of the mobile terminal, this method can dynamically obtain the overload time by using a strong, locally weighted regression method. After detecting the overload time, the probability of successful downloading is predicted by the mobile user's dwell time and edge computing communication range, and the offloading is either conducted immediately or delayed. A computation offloading model was established via the use of the response time and energy consumption of the mobile terminal. Additionally, the optimal computing offloading algorithm was designed via the use of a particle swarm with a mutation operator. Finally, the DCO-PSOMO algorithm was compared with the JOCAP, ECOMC and ESRLR algorithms, and the experimental results demonstrated that the DCO-PSOMO offloading method can effectively reduce the offloading cost and terminal energy consumption, and improves the success probability of offloading and the user's QoS.

| [1] | VZKOO, Hootsuite—global digital report 2021, 2021. Available from: https://www.vzkoo.com/doc/31188.html. |
| [2] |
D. Sabella, A. Vaillant, P. Kuure, U. Rauschenbach, F. Giust, Mobile–edge computing architecture: the role of MEC in the internet of things, IEEE Consum. Electron. Mag., 5 (2016), 84–91. doi: 10.1109/MCE.2016.2590118

|
| [3] | J. Yan, S. Bi, Y. J. Zhang, M. Tao, Optimal task offloading and resource allocation in mobile-edge computing with inter-user task dependency, IEEE Trans. Wireless Commun., 19 (2019), 235–250. |
| [4] |
T. Taleb, K. Samdanis, B. Mada, H. Flinck, S. Dutta, D. Sabella, On multi-access edge computing: A survey of the emerging 5G network edge cloud architecture and orchestration, IEEE Commun. Surv. Tutorials, 19 (2017), 1657–1681. doi: 10.1109/COMST.2017.2705720
|
| [5] |
Y. H. Kao, B. Krishnamachari, M. R. Ra, F. Bai, Hermes: Latency optimal task assignment for resource–constrained mobile computing, IEEE Trans. Mobile Comput., 16 (2017), 3056–3069. doi: 10.1109/TMC.2017.2679712
|
| [6] |
N. Cheng, F. Lyu, W. Quan, C. Zhou, H. He, W. Shi, et al., Space/aerial–assisted computing offloading for IoT applications: A learning–based approach, IEEE J. Sel. Areas Commun., 37 (2019), 1117–1129. doi: 10.1109/JSAC.2019.2906789
|
| [7] | M. G. R. Alam, M. M. Hassan, M. Z. I. Uddin, A. Almogren, G. Fortino, Autonomic computation offloading in mobile edge for IoT applications, Future Gener. Comput. Syst., 90 (2009), 149–157. |
| [8] | S. Wang, R. Urgaonkar, T. He, K. Chan, M. Zafer, K. K. Leung, Dynamic service placement for mobile micro–clouds with predicted future costs, IEEE Trans. Parallel Distrib. Syst., 28 (2016), 1002–1016. |
| [9] | K. Li, M. Tao, Z. Chen, A computation–communication tradeoff study for mobile edge computing networks, in 2019 IEEE International Symposium on Information Theory, (2019), 2639–2643. |
| [10] | C. Yi, J. Cai, Z. Su, A multi-user mobile computation offloading and transmission scheduling mechanism for delay-sensitive applications, IEEE Trans. Mobile Comput., 19 (2019), 29–43. |
| [11] |
M. E. Khoda, M. A. Razzaque, A. Almogren, M. M. Hassan, A. Alamri, A. Alelaiwi, Efficient computation offloading decision in mobile cloud computing over 5G network, Mobile Netw. Appl., 21 (2016), 777–792. doi: 10.1007/s11036-016-0688-6
|
| [12] | S. Deng, L. Huang, J. Taheri, A. Y. Zomaya, Computation offloading for service workflow in mobile cloud computing, IEEE Trans. Parallel Distrib. Syst., 26 (2014), 3317–3329. |
| [13] |
Y. Mao, J. Zhang, K. B. Letaief, Dynamic computation offloading for mobile-edge computing with energy harvesting devices, IEEE J. Sel. Areas Commun., 34 (2016), 3590–3605. doi: 10.1109/JSAC.2016.2611964
|
| [14] | H. Liu, L. Cao, T. Pei, Q. Deng, J. Zhu, A fast algorithm for energy-saving offloading with reliability and latency requirements in multi-access edge computing, IEEE Access, 8 (2019), 151–161. |
| [15] |
B. Li, Y. Pei, H. Wu, B. Shen, Heuristics to allocate high–performance cloudlets for computation offloading in mobile ad hoc clouds, J. Supercomput., 71 (2015), 3009–3036. doi: 10.1007/s11227-015-1425-9
|
| [16] | M. Deng, H. Tian, B. Fan, Fine-granularity based application offloading policy in cloud–enhanced small cell networks, in 2016 IEEE International Conference on Communications Workshops (ICC), (2016), 638–643. |
| [17] | M. Chen, Y. Hao, Y. Li, C. F. Lai, D. Wu, On the computation offloading at ad hoc cloudlet: architecture and service modes, IEEE Commun. Mag., 53 (2015), 18–24. |
| [18] |
H. Kchaou, Z. Kechaou, A. M. Alimi, Towards an offloading framework based on big data analytics in mobile cloud computing environments, Proc. Comput. Sci., 53 (2015), 292–297. doi: 10.1016/j.procs.2015.07.306
|
| [19] | M. H. Chen, M. Dong, B. Liang, Joint offloading decision and resource allocation for mobile cloud with computing access point, in 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), (2016), 3516–3520. |
| [20] | O. Munoz, A. Pascual-Iserte, J. Vidal, Optimization of radio and computational resources for energy efficiency in latency–constrained application offloading, IEEE Trans. Veh. Technol., 64 (2014), 4738–4755. |
| [21] |
V. Pandey, S. Singh, S. Tapaswi, Energy and time efficient algorithm for cloud offloading using dynamic profiling, Wireless Pers. Commun., 80 (2015), 1687–1701. doi: 10.1007/s11277-014-2107-2
|
| [22] | Y. Li, J. Wu, L. Chen, POEM+: Pricing longer for mobile blockchain computation offloading with edge computing, in IEEE International Conference on High Performance Computing and Communications, (2019), 162–167. |
| [23] |
C. You, K. Huang, H. Chae, B. H. Kim, Energy-efficient resource allocation for mobile–edge computation offloading, IEEE Trans. Wireless Commun., 16 (2017), 1397–1411. doi: 10.1109/TWC.2016.2633522
|
| [24] |
S. Khalili, O. Simeone, Inter-layer per-mobile optimization of cloud mobile computing: a message-passing approach, IEEE Trans. Emerging Telecommun. Technol., 27 (2016):814–827. doi: 10.1002/ett.3028
|
| [25] |
G. Mitsis, E. E. Tsiropoulou, S. Papavassiliou, Data offloading in UAV-assisted multi-access edge computing systems: A resource-based pricing and user risk-awareness approach, Sensors, 20 (2020), 1–21. doi: 10.1109/JSEN.2020.3010656
|
| [26] |
P. A. Apostolopoulos, E. E. Tsiropoulou, S. Papavassiliou, Cognitive data offloading in mobile edge computing for internet of things, IEEE Access, 8 (2020), 55736–55749. doi: 10.1109/ACCESS.2020.2981837
|
| [27] | A. Nurunnabi, G. West, D. Belton, Robust locally weighted regression techniques for ground surface points filtering in mobile laser scanning three–dimensional point cloud data, IEEE Trans. Geosci. Remote Sens., 54 (2015), 2181–2193. |













Figures(15) / Tables(3)

Yanpei Liu, Wei Huang, Liping Wang, Yunjing Zhu, Ningning Chen. Dynamic computation offloading algorithm based on particle swarm optimization with a mutation operator in multi-access edge computing[J]. Mathematical Biosciences and Engineering, 2021, 18(6): 9163-9189. doi: 10.3934/mbe.2021452







 DownLoad:
DownLoad: