The aim of this research work is to put forward fuzzy models of granular computing based on fuzzy relation and fuzzy indiscernibility relation. Thanks to fuzzy information granulation to provide multi-level visualization of problems that include uncertain information. In such a granulation, fuzzy sets and fuzzy graphs help us to represent relationships among granules, groups or clusters. We consider the fuzzy indiscernibility relation of a fuzzy knowledge representation system ($ \mathcal{I} $). We describe the granular structures of $ \mathcal{I} $, including discernibility, core, reduct and essentiality of $ \mathcal{I} $. Then we examine the contribution of these structures to granular computing. Moreover, we introduce certain granular structures using fuzzy graph models and discuss degree based model of fuzzy granular structures. Granulation of network models based on fuzzy information effectively handles real life data which possesses uncertainty and vagueness. Finally, certain algorithms of proposed models are developed and implemented to solve real life problems involving uncertain granularities. We also present a concise comparison of the models developed in our work with other existing methodologies.
Citation: Muhammad Akram, Ahmad N. Al-Kenani, Anam Luqman. Degree based models of granular computing under fuzzy indiscernibility relations[J]. Mathematical Biosciences and Engineering, 2021, 18(6): 8415-8443. doi: 10.3934/mbe.2021417
The aim of this research work is to put forward fuzzy models of granular computing based on fuzzy relation and fuzzy indiscernibility relation. Thanks to fuzzy information granulation to provide multi-level visualization of problems that include uncertain information. In such a granulation, fuzzy sets and fuzzy graphs help us to represent relationships among granules, groups or clusters. We consider the fuzzy indiscernibility relation of a fuzzy knowledge representation system ($ \mathcal{I} $). We describe the granular structures of $ \mathcal{I} $, including discernibility, core, reduct and essentiality of $ \mathcal{I} $. Then we examine the contribution of these structures to granular computing. Moreover, we introduce certain granular structures using fuzzy graph models and discuss degree based model of fuzzy granular structures. Granulation of network models based on fuzzy information effectively handles real life data which possesses uncertainty and vagueness. Finally, certain algorithms of proposed models are developed and implemented to solve real life problems involving uncertain granularities. We also present a concise comparison of the models developed in our work with other existing methodologies.

| [1] | T. Y. Lin, Granular computing, Announcement of the BISC Special Interest Group on Granular Computing, 1997. |
| [2] | Y. Y. Yao, N. Zhong, Granular computing using finite information systems, In Data Mining, Rough Sets and Granular Computing, Physica-Verlag, 2002,102–124. |
| [3] | Y. Y. Yao, A partition model of granular computing, In Transactions on rough sets I, Springer, Berlin, Heidelberg, 2004,232–253. |
| [4] | Y. Y. Yao, J. T. Yao, Granular computing as a basis for consistent classification problems, Proc. PAKDD 02 Workshop on Foundations of Data Mining, 2 (2002), 101–106. |
| [5] | J. T. Yao, Y. Y. Yao, A granular computing approach to machine learning, FSKD, 2 (2002), 732–736. |
| [6] |
G. Chiaselotti, D. Ciucci, T. Gentile, F. G. Infusino, The granular partition lattice of an information table, Inf. Sci., 373 (2016), 57–78. doi: 10.1016/j.ins.2016.08.037

|
| [7] | S. K. M. Wong, D. Wu, Automated mining of granular database scheme, In Proc. IEEE Int. Conf. on Fuzzy Syst., 2002,690–694. |
| [8] | C. Bisi, G. Chiaselotti, D. Ciucci, T. Gentile, F. G. Infusino, Micro and macro models of granular computing induced by the indiscernibility relation, Inf. Sci., 388 (2017), 247–273. |
| [9] | C. Berge, Graphs and hypergraphs, Amsterdam: North-Holland Publishing Company, 1973. |
| [10] | J. G. Stell, Granulation for graphs, In Int. Conf. Spat. Inf. Theor., Springer, Berlin, Heidelberg, 1999,417–432. |
| [11] |
F. M. Bianchi, L. Livi, A. Rizzi, A. Sadeghian, A Granular computing approach to the design of optimized graph classification systems, Soft Comput., 18 (2014), 393–412. doi: 10.1007/s00500-013-1065-z
|
| [12] | G. Chen, N. Zhong, Granular structures in graphs, In Int. Conf. RSKT, Springer, Berlin, Heidelberg, 2011,649–658. |
| [13] | G. Chen, N. Zhong, Three granular structure models in graphs, In Int. Conf. RSKT, Springer, Berlin, Heidelberg, 2012,351–358. |
| [14] | G. Chiaselotti, D. Ciucci, T. Gentile, Simple graphs in granular computing, Inf. Sci., 340 (2016), 279–304. |
| [15] | G. Chen, N. Zhong, Y. Yao, A hypergraph model of granular computing, In IEEE Int. Conf. Granular Comput., 2008,130–135. |
| [16] | J. G. Stell, Relational granularity for hypergraphs, In Int. Conf. Rough Sets Curr. Trends Comput., Springer, Berlin, Heidelberg, (2010), 267–276. |
| [17] | L. A. Zadeh, Fuzzy sets and information granularity, Adv. Fuzzy Set Theor. Appl., North-Holland, Amsterdam, (1979), 3–18. |
| [18] | L. A. Zadeh, Towards a theory of fuzzy information granulation and its centrality in human reasoning and fuzzy logic, Fuzzy Sets. Syst., 19 (1997), 111–127. |
| [19] | L. Yang, S. Zhang, L. Zhu, Hypergraph clustering model based on fuzzy frequent item sets applied in management of agricultural land evaluation, In 2010 3rd Int. Conf. Inf. Manage. Innov. Manage. Ind. Eng., 3 (2010), 569–572. |
| [20] |
Q. Wang, Z. Gong, An application of fuzzy hypergraphs and hypergraphs in granular computing, Inf. Sci., 429 (2018), 296–314. doi: 10.1016/j.ins.2017.11.024
|
| [21] |
Z. Gong, Q. Wang, On the connection of fuzzy hypergraph with fuzzy information system, J. Intell. Fuzzy Syst., 33 (2017), 1665–1676. doi: 10.3233/JIFS-16468
|
| [22] |
P. K. Singh, A. C. Kumar, J. Li, Knowledge representation using interval-valued fuzzy formal concept lattice, Soft Comput., 20 (2016), 1485–1502. doi: 10.1007/s00500-015-1600-1
|
| [23] | B. $\check{ S}$e$\check{s}$elja, A. Tepav$\check{s}$evi$\acute{c}$, Fuzzy ordering relation and fuzzy poset, Pattern Recognition and Machine Intelligence, PReMI 2007, Lecture Notes in Computer Science, Springer, Berlin, Heidelberg, 4815, (2007). |
| [24] |
A. Pedrycz, K. Hirota, W. Pedrycz, F. Dong, Granular representation and granular computing with fuzzy sets, Fuzzy Sets. Syst., 203 (2012), 17–32. doi: 10.1016/j.fss.2012.03.009
|
| [25] |
M. Akram, A. Luqman, J. C. R. Alcantud, Risk evaluation in failure modes and effects analysis: hybrid TOPSIS and ELECTRE I solutions with Pythagorean fuzzy information, Neural Comput. Appl., 33 (2021), 5675–5703. doi: 10.1007/s00521-020-05350-3
|
| [26] |
A. Luqman, M. Akram, J. C. R. Alcantud, Digraph and matrix approach for risk evaluations under Pythagorean fuzzy information, Expert Syst. Appl., 170 (2021), 114518. doi: 10.1016/j.eswa.2020.114518
|
| [27] | M. Akram, C. Kahraman, K. Zahid, Group decision-making based on complex spherical fuzzy VIKOR approach, Know. Based Syst., (2021), 106793. |
| [28] | Z. Pawlak, Rough sets, Theoretical Aspects of Reasoning About Data, Kluwer Academic Publisher, 1991. |
| [29] | Z. Pawlak, Granularity of knowledge, indiscernibility and rough sets, Proc.1998 IEEE Int. Conf. Fuzzy Syst., (1998), 106–110. |
| [30] | C. Kaur, R. Kumar, A fuzzy hierarchy-based pattern matching technique for melody classification, Soft Comput., 2 (2019), 7375–7392. |
| [31] |
T. O. William-West, D. Singh, Information granulation for rough fuzzy hypergraphs, Granul. Comput., 3 (2018), 75–92. doi: 10.1007/s41066-017-0057-2
|
| [32] |
Y. Y. Yao, Information granulation and rough set approximation, Int. J. Intell. Syst., 16 (2001), 87–104. doi: 10.1002/1098-111X(200101)16:1<87::AID-INT7>3.0.CO;2-S
|
| [33] | Y. Y. Yao, Information granulation and approximation in a decision-theoretical model of rough sets, In Pal S.K., Polkowski L., Skowron A. (eds) Rough-Neural Computing. Cognitive Technologies, Springer, Berlin, Heidelberg, (2004). |
| [34] |
A. Luqman, M. Akram, A. N. A. Koam, An $m$-polar fuzzy hypergraph model of granular computing, Symmetry, 11 (2019), 483. doi: 10.3390/sym11040483
|
| [35] |
A. Luqman, M. Akram, A. N. A. Koam, Granulation of hypernetwork models under the $q$-rung picture fuzzy environment, Mathematics, 7 (2019), 496. doi: 10.3390/math7060496
|
| [36] |
M. Akram, A. Luqman, A. N. Al-Kenani, Certain models of granular computing based on rough fuzzy approximations, J. Intell. Fuzzy Syst., 39 (2020), 2797–2816. doi: 10.3233/JIFS-191165
|
| [37] |
M. Akram, A. Luqman, Granulation of ecological networks under fuzzy soft environment, Soft Comput., 24 (2020), 11867–11892. doi: 10.1007/s00500-020-05083-4
|
| [38] |
W. Pedrycz, Granular computing as a framework of system modeling, J. Control Autom. Electr. Syst., 24 (2013), 81–86. doi: 10.1007/s40313-013-0010-9
|
| [39] |
W. Pedrycz, Allocation of information granularity in optimization anddecision-making models: Towards building the foundationsof Granular Computing, Eur. J. Operat. Res., 232 (2014), 137–145. doi: 10.1016/j.ejor.2012.03.038
|
| [40] | L. A. Zadeh, Fuzzy sets, Inf. Cont., 8 (1965), 338–353. |
| [41] |
L. A. Zadeh, Similarity relations and fuzzy orderings, Inf. Sci., 3 (1971), 177–200. doi: 10.1016/S0020-0255(71)80005-1
|
| [42] |
Z. Gong, Q. Wang, On the connection of fuzzy hypergraph with fuzzy information system, J. Intell. Fuzzy Syst., 33 (2017), 1665–1676. doi: 10.3233/JIFS-16468
|
| [43] | J. N. Mordeson, P. S. Nair, Fuzzy graphs and fuzzy hypergraphs, Physica Verlag, Heidelberg, Second Edition, 46 (2000), 1–250. |
| [44] | A. Rosenfeld, Fuzzy graphs, In fuzzy Sets and their applications, L. A. Zadeh, K. S. Fu, and M. Shimura, Eds., Academic Press, New York, USA, 1975, 77–95. |
| [45] | K. Radha, N. Kumaravel, The degree of an edge in Cartesian product and composition of two fuzzy graphs, Int. J. App. Math. Stat. Sci., 2 (2013), 65–78. |
| [46] | A. Luqman, Granulation of network models under fuzzy hybrid information, Higher Education Commission, PhD Thesis, 2020. |
| [47] | H. S. Nawaz, M. Akram, J. C. R. Alcantud, An algorithm to compute the strength of competing interactions in the Bering Sea based on Pythagorean fuzzy hypergraphs, Neural Comput. Appl., (2021), 1–23. |
| [48] | M. Akram, H. S. Nawaz, Inter-specific competition among trees in Pythagorean fuzzy soft environment, Complex Intell. Syst., (2021), 1–22. |
| [49] |
F. Zafar, M. Akram, A novel decision-making method based on rough fuzzy information, Int. J. Fuzzy Syst., 20 (2018), 1000–1014. doi: 10.1007/s40815-017-0368-0
|
| [50] | M. Akram, F. Zafar, Hybrid soft computing models applied to graph theory, Springer International Publishing, 2020, 1–434. |
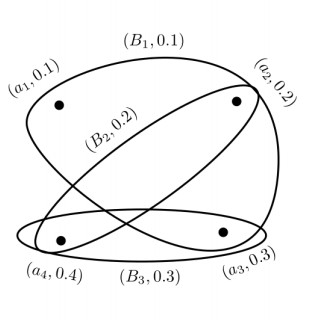
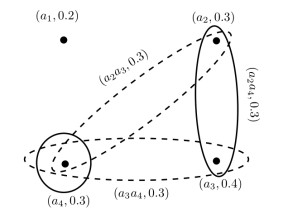
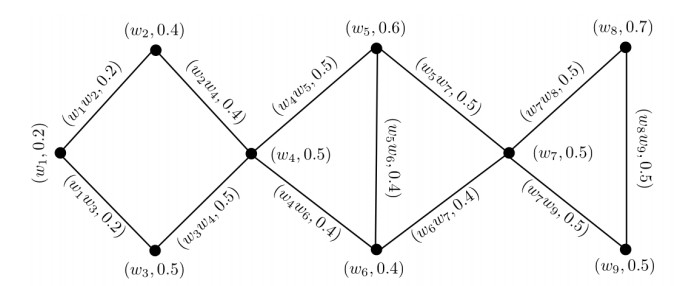
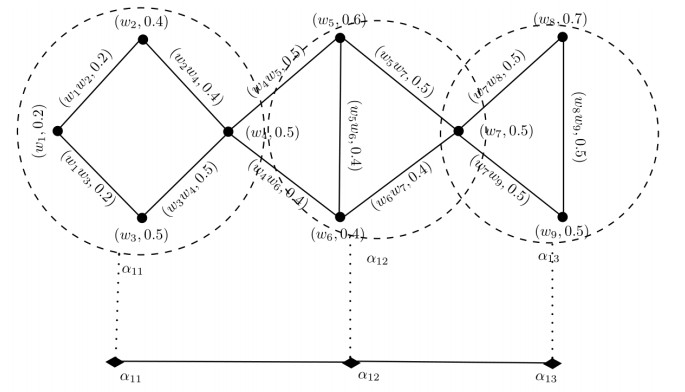
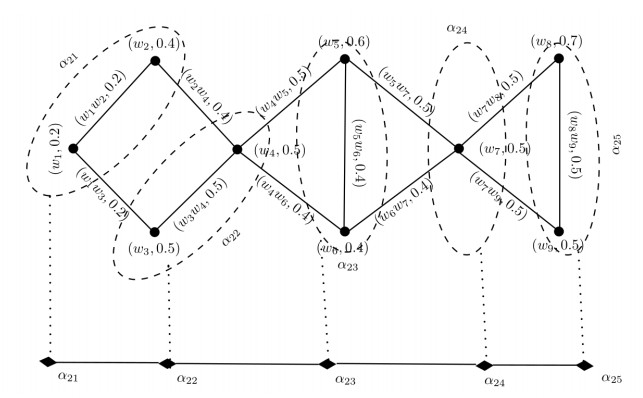
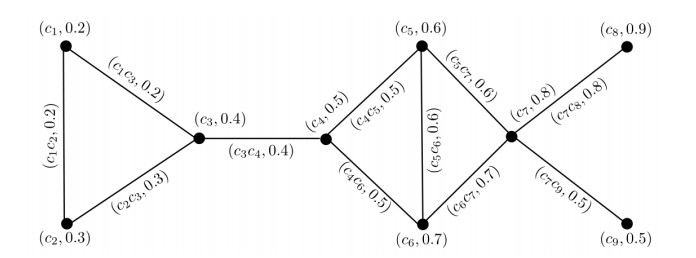
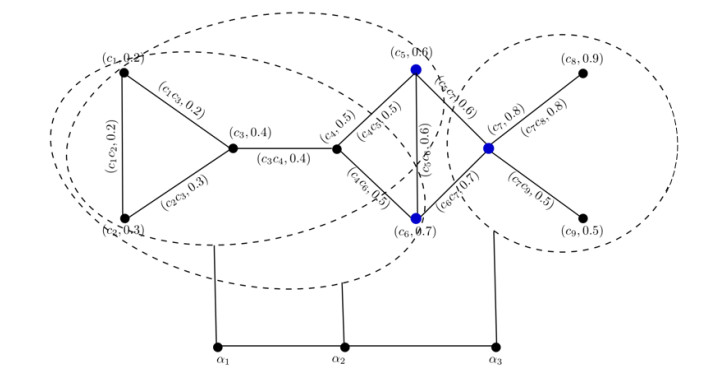
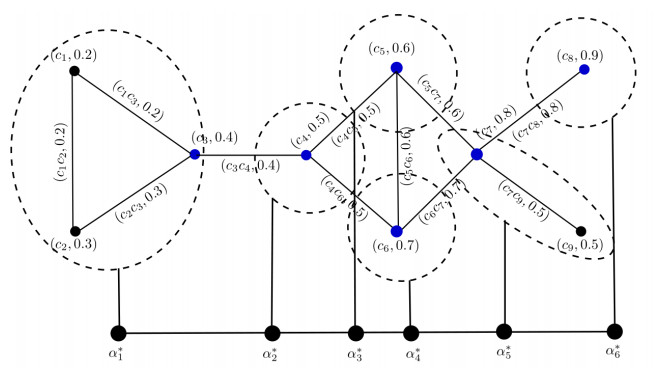
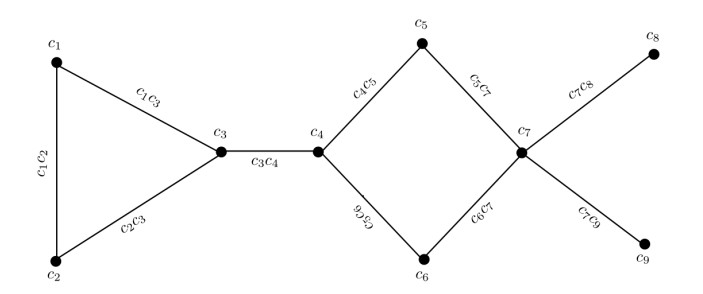
Figures(14) / Tables(14)

Muhammad Akram, Ahmad N. Al-Kenani, Anam Luqman. Degree based models of granular computing under fuzzy indiscernibility relations[J]. Mathematical Biosciences and Engineering, 2021, 18(6): 8415-8443. doi: 10.3934/mbe.2021417







 DownLoad:
DownLoad: