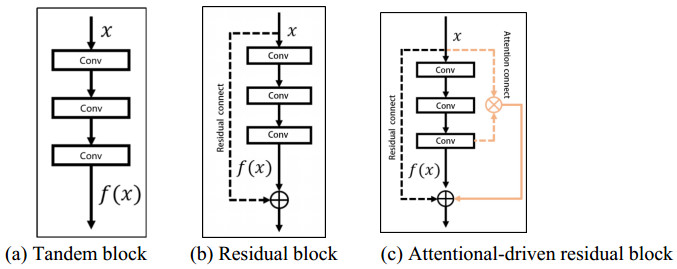
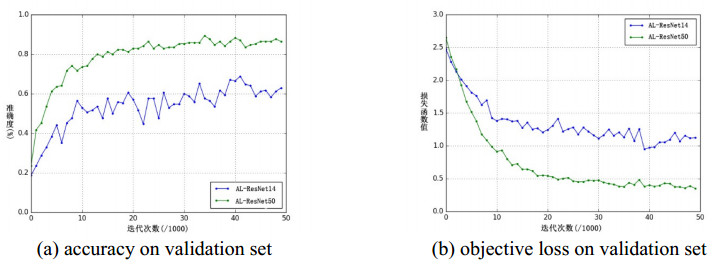
As a typical fine-grained image recognition task, flower category recognition is one of the most popular research topics in the field of computer vision and forestry informatization. Although the image recognition method based on Deep Convolutional Neural Network (DCNNs) has achieved acceptable performance on natural scene image, there are still shortcomings such as lack of training samples, intra-class similarity and low accuracy in flowers category recognition. In this paper, we study deep learning-based flowers' category recognition problem, and propose a novel attention-driven deep learning model to solve it. Specifically, since training the deep learning model usually requires massive training samples, we perform image augmentation for the training sample by using image rotation and cropping. The augmented images and the original image are merged as a training set. Then, inspired by the mechanism of human visual attention, we propose a visual attention-driven deep residual neural network, which is composed of multiple weighted visual attention learning blocks. Each visual attention learning block is composed by a residual connection and an attention connection to enhance the learning ability and discriminating ability of the whole network. Finally, the model is training in the fusion training set and recognize flowers in the testing set. We verify the performance of our new method on public Flowers 17 dataset and it achieves the recognition accuracy of 85.7%.
Citation: Shuai Cao, Biao Song. Visual attentional-driven deep learning method for flower recognition[J]. Mathematical Biosciences and Engineering, 2021, 18(3): 1981-1991. doi: 10.3934/mbe.2021103
As a typical fine-grained image recognition task, flower category recognition is one of the most popular research topics in the field of computer vision and forestry informatization. Although the image recognition method based on Deep Convolutional Neural Network (DCNNs) has achieved acceptable performance on natural scene image, there are still shortcomings such as lack of training samples, intra-class similarity and low accuracy in flowers category recognition. In this paper, we study deep learning-based flowers' category recognition problem, and propose a novel attention-driven deep learning model to solve it. Specifically, since training the deep learning model usually requires massive training samples, we perform image augmentation for the training sample by using image rotation and cropping. The augmented images and the original image are merged as a training set. Then, inspired by the mechanism of human visual attention, we propose a visual attention-driven deep residual neural network, which is composed of multiple weighted visual attention learning blocks. Each visual attention learning block is composed by a residual connection and an attention connection to enhance the learning ability and discriminating ability of the whole network. Finally, the model is training in the fusion training set and recognize flowers in the testing set. We verify the performance of our new method on public Flowers 17 dataset and it achieves the recognition accuracy of 85.7%.

| [1] |
D. R. Pereira, J. P. Papa, G. F. R. Saraiva, G. M. Souza, Automatic classification of plant electrophysiological responses to environmental stimuli using machine learning and interval arithmetic, Comput. Electron. Agric., 145 (2018), 35-42. doi: 10.1016/j.compag.2017.12.024

|
| [2] |
Q. L. Ye, Z. Li, L. Fu, Z. Zhang, W. Yang, G. Yang, Nonpeaked Discriminant Analysis Data Representation, IEEE Trans. Neural Networks Learn. Syst., 30 (2019), 3818-3832. doi: 10.1109/TNNLS.2019.2944869
|
| [3] |
Q. L. Ye, J. Yang, F. Liu, C. Zhao, N. Ye, T. Yin, L1-Norm Distance Linear Discriminant Analysis Based on an Effective Iterative Algorithm, IEEE Trans. Circuits Syst. Video Technol., 28 (2018), 114-129. doi: 10.1109/TCSVT.2016.2596158
|
| [4] | L. Fu, Z. Li, Q. L. Ye, H. Yin, Q. Liu, X. Chen, et al., Learning Robust Discriminant Subspace Based on Joint L2, p- and L2, s-Norm Distance Metrics, IEEE Trans. Neural Networks Learn. Syst., 2020, forthcoming. |
| [5] | L. Fu, D. Zhang, Q. L. Ye, Recurrent Thrifty Attention Network for Remote Sensing Scene Recognition, IEEE Trans. Geosci. Remote Sens., 2020, forthcoming. |
| [6] |
C. Wachinger, M. Reuter, T. Klein, DeepNAT: Deep convolutional neural network for segmenting neuroanatomy, NeuroImage, 170 (2018), 434-445. doi: 10.1016/j.neuroimage.2017.02.035
|
| [7] | Y. Cheng, L. Fu, P. Luo, Q. Ye, F. Liu, W. Zhu, Multi-view generalized support vector machine via mining the inherent relationship between views with applications to face and fire smoke recognition, Knowl. Based Syst., 210 (2020), 106488. |
| [8] |
Y. Chen, H. Yin, Q. L. Ye, P. Huang, L. Fu, Z. Yang, Improved multi-view GEPSVM via Inter-View Difference Maximization and Intra-view Agreement Minimization, Neural Networks, 125 (2020), 313-329. doi: 10.1016/j.neunet.2020.02.002
|
| [9] | Q. L. Ye, H. Zhao, Z. Li, X. Yang, S. Gao, T. Yin, et al., L1-norm Distance Minimization Based Fast Robust Twin Support Vector k-plane clustering, IEEE Trans. Neural Networks Learn. Syst., 29 (2018), 4494-4503. |
| [10] |
H. Zhu, Q. Liu, Y. Qi, X. Huang, F. Jiang, S. Zhang, Plant identification based on very deep convolutional neural networks, Multimedia Tools Appl., 77 (2018), 29779-29797. doi: 10.1007/s11042-017-5578-9
|
| [11] | Q. Ye, D. Xu, D. Zhang, Remote sensing image classification based on deep learning features and support vector machine, J. For. Eng., 4 (2019), 20961359. |
| [12] |
Y. Liu, X. Zhou, Z. Hu, Y. Yu, Y. Yang, C. Xu, Wood defect recognition based on optimized convolution neural network algorithm, J. For. Eng., 4 (2019), 115-120. doi: 10.31186/jenggano.4.2.115-127
|
| [13] |
M. Cıbuk, U. Budak, Y. Guo, M. C. Ince, A. Sengur, Efficient deep features selections and classification for flower species recognition, Measurement, 137 (2019), 7-13. doi: 10.1016/j.measurement.2019.01.041
|
| [14] | S. Zhang, J. Yang, B. Schiele, Occluded Pedestrian Detection Through Guided Attention in CNNs, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018. |
| [15] | M. E. Nilsback, A. Zisserman, A Visual Vocabulary for Flower Classification, 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, 2006. |
| [16] |
J. Zhang, K. Shao, X. Luo, Small sample image recognition using improved Convolutional Neural Network, J. Visual Commun. Image Representation, 55 (2018), 640-647. doi: 10.1016/j.jvcir.2018.07.011
|
| [17] | K. Li, M. Zhang, Z. Yang, B. Lyu, Classification for decorative papers of wood-based panels using color and glossiness parameters in combination with neural network method, J. For. Eng., 3 (2018), 16-20. |
| [18] | K. He, X. Zhang, S. Ren, J. Sun, Deep Residual Learning for Image Recognition, Proceedings of the IEEE conference on computer vision and pattern recognition, 2016. |
| [19] | M. Ravanelli, T. Parcollet, Y. Bengio, The PyTorch-Kaldi Speech Recognition Toolkit, ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2019. |
| [20] |
B. Kim, C. Oh, Y. Yi, D. Kim, GPU-Accelerated Boussinesq Model Using Compute Unified Device Architecture FORTRAN, J. Coastal Res., 85 (2018), 1176-1180. doi: 10.2112/SI85-236.1
|
| [21] |
G. Cheng, Z. Li, J. Han, X. Yao, L. Gao, Exploring hierarchical convolutional features for hyperspectral image classification, IEEE Trans. Geosci. Remote Sens., 56 (2018), 6712-6722. doi: 10.1109/TGRS.2018.2841823
|
| [22] | T. Sercu, C. Puhrsch, B. Kingsbury, Y. LeCun, Very Deep Multilingual Convolutional Neural Networks for LVCSR, 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2016. |
| [23] | M. Lin, Q. Chen, S. Yan, Network in network, preprint, arXiv: 1312.4400, |
| [24] | K. He, X. Zhang, S. Ren, J. Sun, Delving Deep into Rectifiers: Surpassing Human-level Performance on Imagenet Classification, Proceedings of the IEEE international conference on computer vision, 2015. |
| [25] | C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, Z. Wojna, Rethinking the Inception Architecture for Computer Vision, Proceedings of the IEEE conference on computer vision and pattern recognition, 2016. |



Figures(5) / Tables(2)

Shuai Cao, Biao Song. Visual attentional-driven deep learning method for flower recognition[J]. Mathematical Biosciences and Engineering, 2021, 18(3): 1981-1991. doi: 10.3934/mbe.2021103







 DownLoad:
DownLoad: