Citation: Debashis Ghosh. Wavelet-based Benjamini-Hochberg procedures for multiple testing under dependence[J]. Mathematical Biosciences and Engineering, 2020, 17(1): 56-72. doi: 10.3934/mbe.2020003

| [1] | Y. Benjamini and Y. Hochberg, Controlling the false discovery rate: a practical and powerful approach to multiple testing, R. Stat. Soc. B, 57 (1995), 289-300. |
| [2] | Y. Benjamini and D. Yekutieli, The control of the false discovery rate in multiple testing under dependency, Ann. Stat., 29 (2001), 1165-1188. |
| [3] | S. K. Sarkar, Some results on false discovery rates in stepwise multiple testing procedures, Ann. Stat., 30 (2002), 239-257. |
| [4] | S. K. Sarkar, False discovery and false nondiscovery rates in single-step multiple testing procedures, Ann. Stat., 34 (2006), 394-415. |
| [5] | G. Blanchard and E. Roquain, Two simple sufficient conditions for FDR control, Electron. J. Statist., 2 (2008), 963-992. |
| [6] | C. R. Genovese and L. Wasserman, A stochastic process approach to false discovery control, Ann. Stat., (2004), 1035-1061. |
| [7] | J. D. Storey, J. E. Taylor and D. Siegmund, Strong control, conservative point estimation and simultaneous conservative consistency of false discovery rates: a unified approach, J. R. Stat. Soc. B, 66 (2004), 187-205. |
| [8] | M. P. Pacifico, C. Genovese, I. Verdinelli, et al., False discovery control for random fields, J. Am. Stat. Assoc., 99 (2004), 1002-1014. |
| [9] | W. Sun and T. Cai, Large-scale multiple testing under dependency, J. R. Stat. Soc. B, 71 (2009), 393-424. |
| [10] | B. Efron, Correlation and large-scale simultaneous significance testing, J. Am. Stat. Assoc., 102 (2007), 93-103. |
| [11] | B. Efron, Correlated z-values and the accuracy of large-scale statistical estimates, J. Am. Stat. Assoc., 105 (2010), 1042-1055. |
| [12] | J. T. Leek and J. D. Storey, Capturing Heterogeneity in Gene Expression Studies by Surrogate Variable Analysis, PLoS Genet., 3 (2007), e161. |
| [13] | A. Schwartzman and X. Lin, The effect of correlation on false discovery rate estimation, Biometrika, 98 (2011), 199-214. |
| [14] | R. Pyke, Spacings (with discussion), J. R. Stat. Soc. B, 27 (1965), 395-436. |
| [15] | D. Ghosh, Incorporating the empirical null hypothesis into the Benjamini-Hochberg procedure, Stat. Appl. Genet. Mol. Biol., 11 (2012). |
| [16] | S. G. Mallat, A theory for multiresolution signal decomposition: the wavelet representation, IEEE Trans. Pattern Anal. Machine Intell., 11 (1989), 674-693. |
| [17] | I. Daubechies, Ten Lectures on Wavelets. Philadelphia: SIAM, 1992. |
| [18] | F. Abramovich and Y. Benjamini, Adaptive thresholding of wavelet coefficients, Comput. Stat. Data Anal., 22 (1996), 351-361. |
| [19] | X. Shen, H. C. Huang and N. Cressie, Nonparametric hypothesis testing for a spatial signal, J. Am. Stat. Assoc., 97 (2002), 1122-1140. |
| [20] | M. Langaas, B. H. Lindqvist and E. Ferkingstad, Estimating the portion of true null hypotheses, with application to DNA microarray data, J. R. Stat. Soc. B, 67 (2005), 555-572. |
| [21] | Y. Benjamini, A. M. Krieger and D. Yekutieli, Adaptive linear step-up procedures that control the false discovery rate, Biometrika, 93 (2006), 491-507. |
| [22] | H. Finner, T. Dickhaus and M. Roters, On the false discovery rate and an asymptotically optimal rejection curve, Ann. Stat., 37 (2008), 596-618. |
| [23] | J. A. Ferreira and A. H. Zwinderman, On the Benjamini-Hochberg method, Ann. Stat., 34 (2006), 1827-1849. |
| [24] | W. B. Wu, On false discovery control under dependence, Ann. Stat., 36 (2008), 364-380. |
| [25] | J. Fan, X. Han and W. Gu, Estimating false discovery proportion under arbitrary covariance dependence (with discussion), J. Am. Stat. Assoc., 107 (2012), 1019-1048. |
| [26] | K. H. Desai and J. D. Storey, Cross-Dimensional Inference of Dependent High-Dimensional Data, J. Am. Stat. Assoc., 107 (2012), 135-151. |
| [27] | R. J. Adler and J. E. Taylor, Random Fields and Geometry, New York: Springer, 2007. |
| [28] | J. T. Leek and J. D. Storey, Capturing Heterogeneity in Gene Expression Studies by Surrogate Variable Analysis, PLoS Genet., 3 (2007), e161. |
| [29] | D. B. Percival and A. T. Walden, Wavelet methods for time series analysis, Cambridge: Cambridge University Press, 2000. |
| [30] | I. M. Johnstone and B. W. Silverman, Wavelet threshold estimators for data with correlated noise, J. R. Stat. Soc. B, 59 (1997), 319-351. |
| [31] | I. Hedenfalk, D.Duggan, Y. Chen, et al., Gene-expression profiles in hereditary breast cancer, New England J. Med., 344 (2001), 539-548. |
| [32] | T. R. Golub, D. K. Slonim, P. Tamayo, et al., Molecular classification of cancer: class discovery and class prediction by gene expression monitoring, Science, 286 (1999), 531-537. |
| [33] | M. S. Taqqu, Weak convergence to fractional Brownian motion and to the Rosenblatt process, Z. Wahrscheinlichkeitstheorie verw. Geb., 31 (1975), 287-302. |
| [34] | A. Cohen, I. Daubechies and J. C. Feauveau, Biorthogonal bases of compactly supported wavelets, Commun. Pur. Appl. Math., 45 (1992), 485-560. |
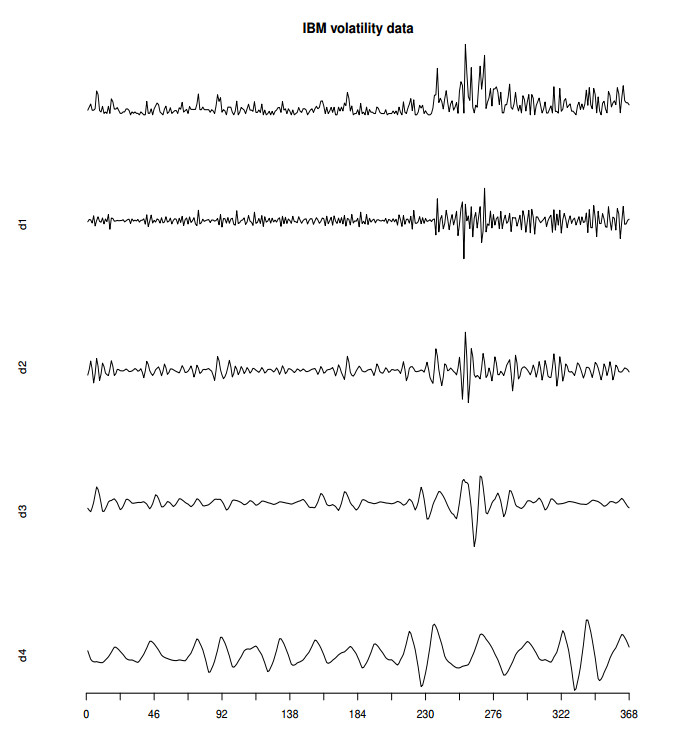
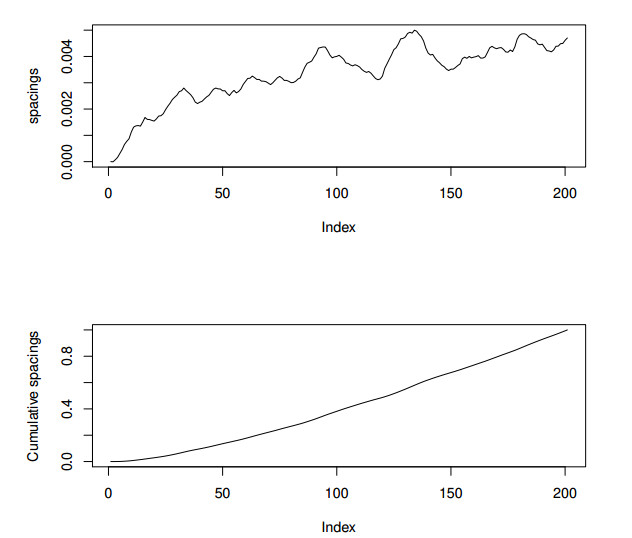
Figures(2) / Tables(3)

Debashis Ghosh. Wavelet-based Benjamini-Hochberg procedures for multiple testing under dependence[J]. Mathematical Biosciences and Engineering, 2020, 17(1): 56-72. doi: 10.3934/mbe.2020003







 DownLoad:
DownLoad: