Citation: Fengyong Li, Gang Zhou, Jingsheng Lei. Reliable data transmission in wireless sensor networks with data decomposition and ensemble recovery[J]. Mathematical Biosciences and Engineering, 2019, 16(5): 4526-4545. doi: 10.3934/mbe.2019226

| [1] | H. Shen, X. Li, Q. Cheng, et al., Missing information reconstruction of remote sensing data: A technical review, IEEE Geosc. Rem. Sen. M., 3 (2015), 61–85. |
| [2] | M. Chen, S. Mao and Y. Liu, Big data: A survey, Mobile Netw. Appl., 19 (2014), 171–209. |
| [3] | A. Sandryhaila and J. Moura, Big data analysis with signal processing on graphs: Representation and processing of massive data sets with irregular structure, IEEE Signal Proc. Mag., 31 (2014), 80–90. |
| [4] | T. Cover and P. Hart, Nearest neighbor pattern classification, IEEE T. Inform. Theory, 13 (1967), 21–27. |
| [5] | L. Kong, D. Jiang and M. Wu, Optimizing the spatio-temporal distribution of cyber-physical systems for environment abstraction, 2010 IEEE 30th International Conference on Distributed Computing Systems (ICDCS), Genoa, Italy, June 21–25, (2010), 179–188. |
| [6] | H. Zhu, Y. Zhu, M. Li, et al., SEER: Metropolitan-scale traffic perception based on lossy sensory data, in Proceedings of IEEE International Conference on Computer Communications (INFO-COM), Rio de Janeiro, Brazil, April 19-25, (2009), 217–225. |
| [7] | E. Candes, J. Romberg and T. Tao, Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information, IEEE T. Inform. Theory, 52 (2006), 489–509. |
| [8] | D. Donoho, Compressed sensing, IEEE T. Inform. Theory, 52 (2006), 1289–1306. |
| [9] | L. Kong, M. Xia, X. Liu, et al., Data loss and reconstruction in wireless sensor networks, IEEE T. Parall. Distr., 25 (2014), 2818–2828. |
| [10] | Z. Chen, L. Chen, G. Hu, et al., Data reconstruction in wireless sensor networks from incomplete and erroneous observations, IEEE Access, 6 (2018), 45493–45503. |
| [11] | F. Li, K. Wu, X. Zhang, et al., Robust batch steganography in social networks with non-uniform payload and data decomposition, IEEE Access, 6 (2018), 29912–29925. |
| [12] | X. Zhang, Matrix analysis and applications, Beijing, Tsinghua University Press, (2004), 161–166. |
| [13] | A. Sekey, A computer simulation study of real-zero interpolation, IEEE T. Audio Electroacous-tics, 18 (1970), 43–54. |
| [14] | N. Dodgson, Quadratic interpolation for image resampling, IEEE T. Image Process., 6 (1997), 1322–1326. |
| [15] | M. Wen, K. Lu, J. Lei, et al., BDO-SD: An efficient scheme for big data outsourcing with secure deduplication, 2015 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Hong Kong, China, April 26-May 1, (2015), 214–219. |

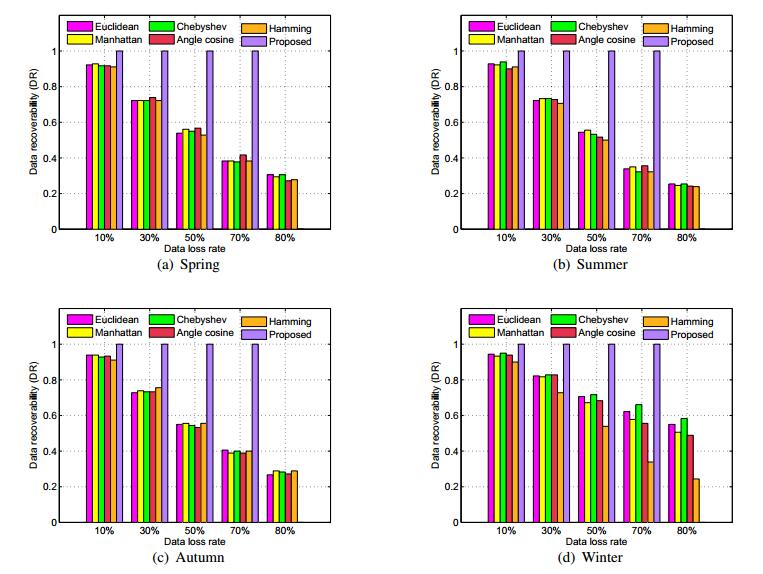
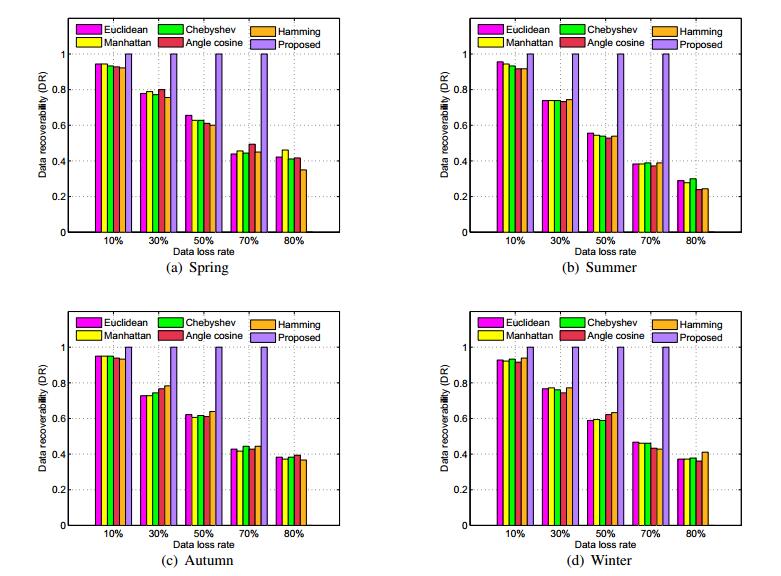
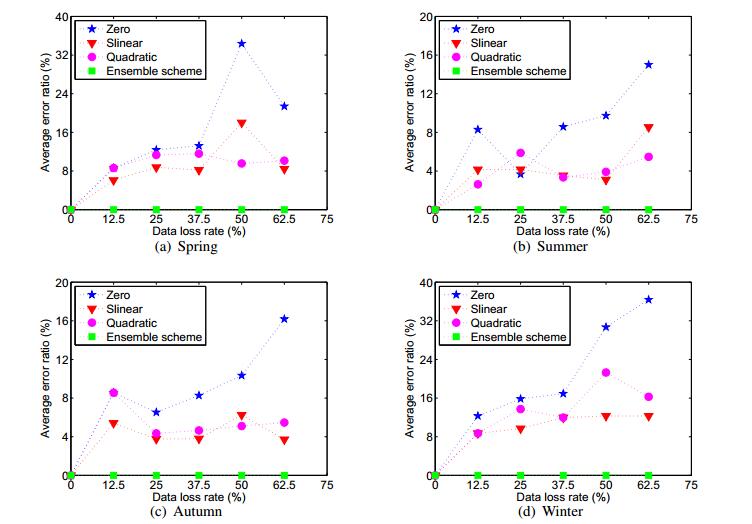
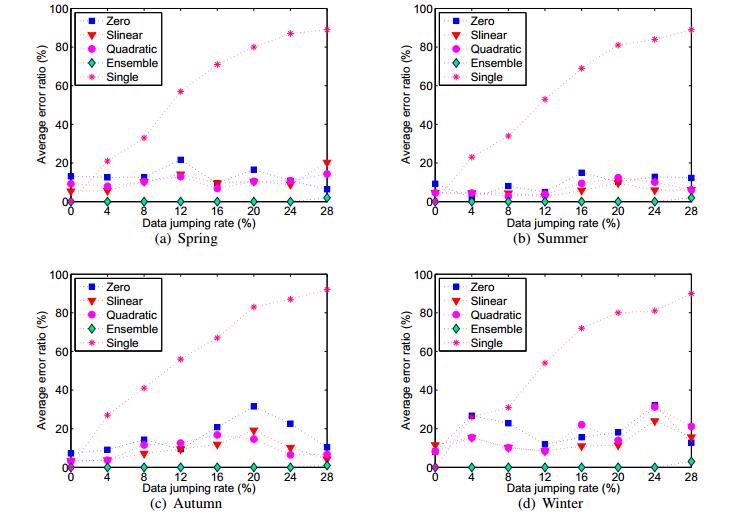
Figures(9) / Tables(4)

Fengyong Li, Gang Zhou, Jingsheng Lei. Reliable data transmission in wireless sensor networks with data decomposition and ensemble recovery[J]. Mathematical Biosciences and Engineering, 2019, 16(5): 4526-4545. doi: 10.3934/mbe.2019226







 DownLoad:
DownLoad: