Citation: Petko M. Kitanov, Allan R. Willms. Probability of Escherichia coli contamination spread in ground beef production[J]. Mathematical Biosciences and Engineering, 2018, 15(4): 1011-1032. doi: 10.3934/mbe.2018045

| [1] | [ M. Aslam,G. G. Greer,F. M. Nattress,C. O. Gill,L. M. McMullen, Genotypic analysis of Escherichia coli recovered from product and equipment at a beef-packing plant, Journal of Applied Microbiology, 97 (2004): 78-86. |
| [2] | [ M. Aslam,F. M. Nattress,G. G. Greer,C. Yost,C. O. Gill,L. McMullen, Origin of contamination and genetic diversity of Eschericia coli in beef cattle, Applied and Environmental Microbiology, 69 (2003): 2794-2799. |
| [3] | [ R. G. Bell, Distribution and sources of microbial contamination on beef carcasses, Journal of Applied Microbiology, 82 (1997): 292-300. |
| [4] | [ M. H. Cassin,A. M. Lammerding,E. C. D. Todd,W. Ross,R. S. McColl, Quantitative risk assessment for Escherichia coli O157: H7 in ground beef hamburgers, International Journal of Food Microbiology, 41 (1998): 21-44. |
| [5] | [ D. A. Drew,G. A. Koch,H. Vellante,R. Talati,O. Sanchez, Analyses of mechanisms for force generation during cell septation in Escherichia coli, Bulletin of Mathematical Biology, 71 (2009): 980-1005. |
| [6] | [ G. Duffy, F. Butler, E. Cummins, S. O'Brien, P. Nally, E. Carney, M. Henchion, D. Mahone and C. Cowan, E. coli O157: H7 in Beef burgers Produced in the Republic of Ireland: A Quantitative Microbial Risk Assessment, Technical report, Ashtown Food Research Centre, Teagasc, Dublin 15, Ireland, 2006. |
| [7] | [ G. Duffy,E. Cummins,P. Nally,S. O'Brien,F. Butler, A review of quantitative microbial risk assessment in the management of Escherichia coli O157:H7 on beef, Meat Science, 74 (2006): 76-88. |
| [8] | [ E. Ebel,W. Schlosser,J. Kause,K. Orloski,T. Roberts,C. Narrod,S. Malcolm,M. Coleman,M. Powell, Draft risk assessment of the public health impact of Escherichia coli O157:H7 in ground beef, Journal of Food Protection, 67 (2004): 1991-1999. |
| [9] | [ P. M. Kitanov and A. R. Willms, Estimating Escherichia coli contamination spread in ground beef production using a discrete probability model, in Mathematical and Computational Approaches in Advancing Modern Science and Engineering (eds. J. Bélair, I. F. I, H. Kunze, R. Makarov, R. Melnik and R. Spiteri), Springer, AMMCS-CAIMS 2015, Waterloo, Canada, 2016,245-254. |
| [10] | [ A. Rabner,E. Martinez,R. Pedhazur,T. Elad,S. Belkin,Y. Shacham, Mathematical modeling of a bioluminescent E. Coli based biosensor, Nonlinear Analysis: Modelling and Control, 14 (2009): 505-529. |
| [11] | [ E. Salazar-Cavazos,M. Santillán, Optimal performance of the tryptophan operon of E. coli: A stochastic, dynamical, mathematical-modeling approach, Bulletin of Mathematical Biology, 76 (2014): 314-334. |
| [12] | [ E. Scallan,R. M. Hoekstra,F. J. Angulo,R. V. Tauxe,M. A. Widdowson,S. L. Roy,J. L. Jones,P. M. Griffin, Foodborne illness acquired in the United States -Major pathogens, Emerging Infectious Diseases, 17 (2011): 7-15. |
| [13] | [ M. Signorini,H. Tarabla, Quantitative risk assessment for verocytotoxigenic Escherichia coli in ground beef hamburgers in Argentina, International Journal of Food Microbiology, 132 (2009): 153-161. |
| [14] | [ B. A. Smith,A. Fazil,A. M. Lammerding, A risk assessment model for Escherichia coli O157:H7 in ground beef and beef cuts in canada: Evaluating the effects of interventions, Food Control, 29 (2013): 364-381. |
| [15] | [ J. Turner,R. G. Bowers,M. Begon,S. E. Robinson,N. P. French, A semi-stochastic model of the transmission of Escherichia coli O157 in a typical UK dairy herd: Dynamics, sensitivity analysis and intervention prevention strategies, Journal of Theoretical Biology, 241 (2006): 806-822. |
| [16] | [ J. Turner,R. G. Bowers,D. Clancy,M. C. Behnke,R. M. Christley, A network model of E.coli O157 transmission within a typical UK dairy herd: The effect of heterogeneity and clustering on the prevalence of infection, Journal of Theoretical Biology, 254 (2008): 45-54. |
| [17] | [ J. Tuttle,T. Gomez,M. P. Doyle,J. G. Wells,T. Zhao,R. V. Tauxe,P. M. Griffin, Lessons from a large outbreak of Escherichia coli O157:H7 infections: Insights into the infectious dose and method of widespread contamination of hamburger patties, Epidemiology and Infection, 122 (1999): 185-192. |
| [18] | [ X. Wang,R. Gautam,P. J. Pinedo,L. J. S. Allen,R. Ivanek, A stochastic model for transmission, extinction and outbreak of Escherichia coli O157:H7 in cattle as affected by ambient temperature and cleaning practices, Journal of Mathematical Biology, 69 (2014): 501-532. |
| [19] | [ X. Yang,M. Badoni,M. K. Youssef,C. O. Gill, Enhanced control of microbiological contamination of product at a large beef packing plant, Journal of Food Protection, 75 (2012): 144-149. |
| [20] | [ X. S. Zhang,M. E. Chase-Topping,I. J. McKendrick,N. J. Savill,M. E. J. Woolhouse, Spread of Escherichia coli O157:H7 infection among Scottish cattle farms: Stochastic models and model selection, Epidemics, 2 (2010): 11-20. |
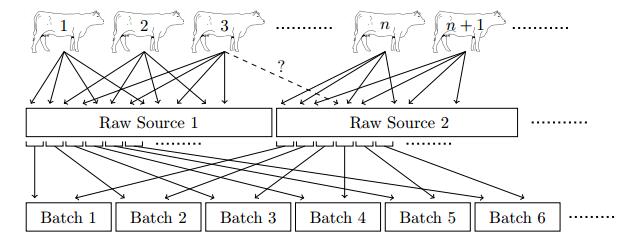
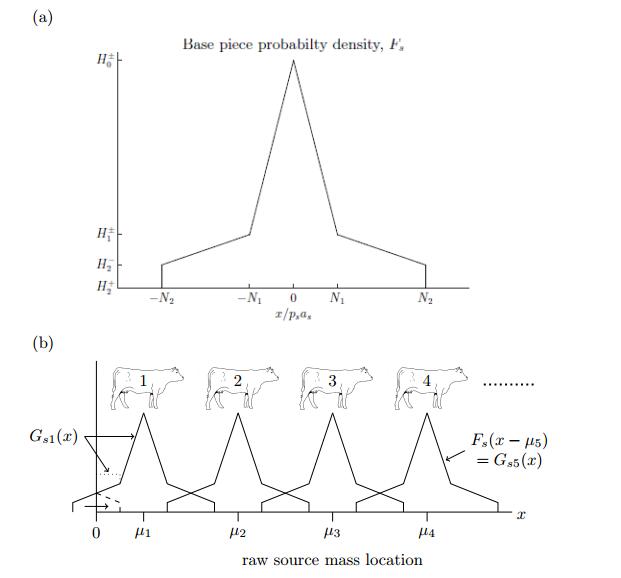
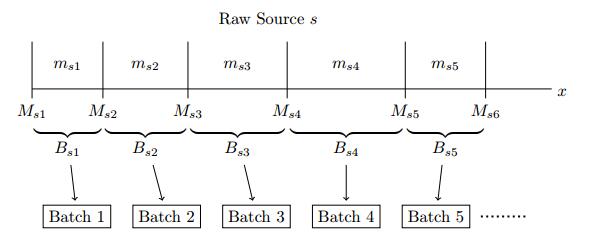
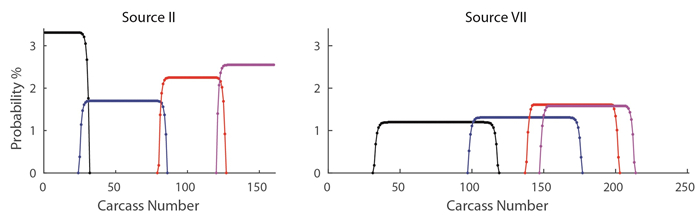

Figures(7) / Tables(11)

Petko M. Kitanov, Allan R. Willms. Probability of Escherichia coli contamination spread in ground beef production[J]. Mathematical Biosciences and Engineering, 2018, 15(4): 1011-1032. doi: 10.3934/mbe.2018045







 DownLoad:
DownLoad: