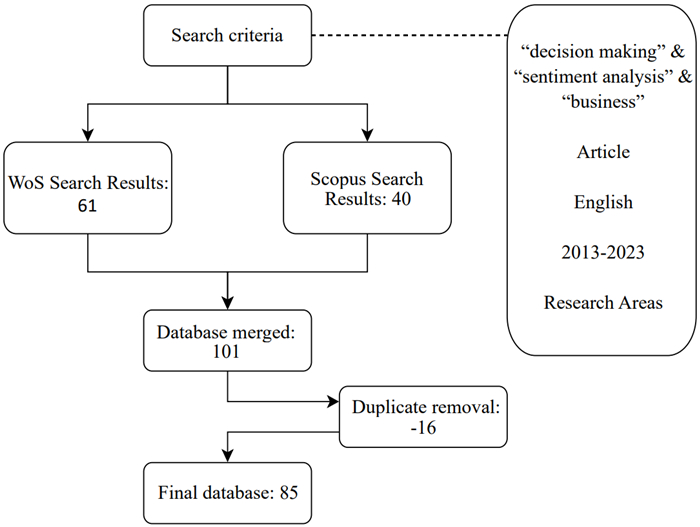
Customer feedback on online platforms is an unstructured database of growing importance for organizations, which, together with the rise of Natural Language Processing algorithms, is increasingly present when making decisions. In this paper, a bibliometric analysis is carried out with the intention of understanding the prevailing state of research about the adoption of sentiment analysis methods in organizations when making decisions. It is also a goal to comprehend which business sectors, and areas within the company, they are most applied, and to identify what future challenges that in this area may arise, as well as the main topics, authors, articles, countries, and universities most influential in the scientific literature. To this end, a total of 101 articles have been gathered from the Scopus and Clarivate Analytics Web of Science (WoS) databases, of which 85 were selected for analysis using the Bibliometrix tool. This study highlights the growing popularity of sentiment analysis methods combined with Multicriteria Decision Making and predictive algorithms. Twitter and Amazon are commonly used data sources, with applications across multiple sectors (supply chain, financial, etc.). Sentiment analysis enhances decision-making and promotes customer-centric approaches.
Citation: J. A. Aguilar-Moreno, P. R. Palos-Sanchez, R. Pozo-Barajas. Sentiment analysis to support business decision-making. A bibliometric study[J]. AIMS Mathematics, 2024, 9(2): 4337-4375. doi: 10.3934/math.2024215
Customer feedback on online platforms is an unstructured database of growing importance for organizations, which, together with the rise of Natural Language Processing algorithms, is increasingly present when making decisions. In this paper, a bibliometric analysis is carried out with the intention of understanding the prevailing state of research about the adoption of sentiment analysis methods in organizations when making decisions. It is also a goal to comprehend which business sectors, and areas within the company, they are most applied, and to identify what future challenges that in this area may arise, as well as the main topics, authors, articles, countries, and universities most influential in the scientific literature. To this end, a total of 101 articles have been gathered from the Scopus and Clarivate Analytics Web of Science (WoS) databases, of which 85 were selected for analysis using the Bibliometrix tool. This study highlights the growing popularity of sentiment analysis methods combined with Multicriteria Decision Making and predictive algorithms. Twitter and Amazon are commonly used data sources, with applications across multiple sectors (supply chain, financial, etc.). Sentiment analysis enhances decision-making and promotes customer-centric approaches.

| [1] |
S. Kameswaran, V. S. F. Enigo, ScranViz: A tool for analytics and visualisation of unstructured data, Int. J. Bus. Intell. Data Min., 17 (2020), 179–192. https://doi.org/10.1504/IJBIDM.2020.108769 doi: 10.1504/IJBIDM.2020.108769

|
| [2] |
Y. Zhao, L. Wen, X. Feng, R. Li, X. Lin, How managerial responses to online reviews affect customer satisfaction: An empirical study based on additional reviews, J. Retail. Consum. Serv., 57 (2020), 102205. https://doi.org/10.1016/J.JRETCONSER.2020.102205 doi: 10.1016/J.JRETCONSER.2020.102205
|
| [3] |
A. M. Abirami, A. Askarunisa, Sentiment analysis model to emphasize the impact of online reviews in healthcare industry, Online Inform. Rev., 41 (2017), 471–486. https://doi.org/10.1108/OIR-08-2015-0289 doi: 10.1108/OIR-08-2015-0289
|
| [4] |
Z. Peng, Y. Wan, Generating business intelligence through automated textual analysis: measuring corporate image with online information, Chin. Manag. Stud., 17 (2022). https://doi.org/10.1108/CMS-07-2021-0318 doi: 10.1108/CMS-07-2021-0318
|
| [5] | D. Summers, Longman business English dictionary, Pearson Longman, India, 2007. |
| [6] | W. C. Burton, Burton's legal thesaurus, LexisNexis, 2021. |
| [7] |
H. Lizano-Mora, P. R. Palos-Sanchez, M. Aguayo-Camacho, The evolution of business process management: A bibliometric analysis, IEEE Access, 9 (2021), 51088–51105. https://doi.org/10.1109/ACCESS.2021.3066340 doi: 10.1109/ACCESS.2021.3066340
|
| [8] |
C. D. Maio, G. Fenza, V. Loia, F. Orciuoli, E. Herrera-Viedma, A framework for context-aware heterogeneous group decision making in business processes, Knowl.-Based Syst., 102 (2016), 39–50. https://doi.org/10.1016/j.knosys.2016.03.019 doi: 10.1016/j.knosys.2016.03.019
|
| [9] |
C. Zhang, Y. X. Tian, L. W. Fan, Y. H. Li, Customized ranking for products through online reviews: A method incorporating prospect theory with an improved VIKOR, Appl. Intell., 50 (2020), 1725–1744. https://doi.org/10.1007/S10489-019-01577-3 doi: 10.1007/S10489-019-01577-3
|
| [10] |
N. Gobi, A. Rathinavelu, Analyzing cloud based reviews for product ranking using feature based clustering algorithm, Clust. Comput., 22 (2019), 6977–6984. https://doi.org/10.1007/S10586-018-1996-3 doi: 10.1007/S10586-018-1996-3
|
| [11] |
W. N. Chan, T. Thein, Sentiment analysis system in big data environment, Comput. Syst. Sci. Eng., 3 (2018), 187–202. https://doi.org/10.32604/csse.2018.33.187 doi: 10.32604/csse.2018.33.187
|
| [12] |
B. Liu, Sentiment analysis: Mining opinions, sentiments, and emotions, Sentim. Anal. Min. Opin. Sentim. Emot., 2015, 1–367. https://doi.org/10.1017/CBO9781139084789 doi: 10.1017/CBO9781139084789
|
| [13] |
R. Sathyan, P. Parthiban, R. Dhanalakshmi, A. Minz, A combined big data analytics and Fuzzy DEMATEL technique to improve the responsiveness of automotive supply chains, J. Amb. Intel. Hum. Comput., 12 (2021), 7949–7963. https://doi.org/10.1007/S12652-020-02524-8 doi: 10.1007/S12652-020-02524-8
|
| [14] |
K. Kim, S. Y. T. Lee, S. Assar, The dynamics of cryptocurrency market behavior: Sentiment analysis using Markov chains, Ind. Manag. Data Syst., 122 (2022), 365–395. https://doi.org/10.1108/IMDS-04-2021-0232 doi: 10.1108/IMDS-04-2021-0232
|
| [15] |
A. D. Ganesh, P. Kalpana, Supply chain risk identification: a real-time data-mining approach, Ind. Manag. Data Syst., 122 (2022), 1333–1354. https://doi.org/10.1108/IMDS-11-2021-0719 doi: 10.1108/IMDS-11-2021-0719
|
| [16] | L. Zhang, B. Liu, Sentiment analysis and opinion mining, In: Encyclopedia of Machine Learning and Data Mining (eds. C. Sammut and G. I. Webb), Springer, Boston, MA, 2017, 1152–1161. https://doi.org/10.1007/978-1-4899-7687-1_907 |
| [17] |
C. Bhadane, H. Dalal, H. Doshi, Sentiment analysis: Measuring opinions, Procedia Comput. Sci., 45 (2015), 808–814. https://doi.org/10.1016/J.PROCS.2015.03.159 doi: 10.1016/J.PROCS.2015.03.159
|
| [18] |
H. R. Batista, J. C. G. Junior, M. D. Miranda, A. Martiniano, R. J. Sassi, M. A. Gaspar, et al., "If we only knew how you feel"—A comparative study of automated vs. manual classification of opinions of customers on digital media, Soc. Netw., 8 (2018), 74–83. https://doi.org/10.4236/SN.2019.81005 doi: 10.4236/SN.2019.81005
|
| [19] | A. Esuli, F. Sebastiani, SENTIWORDNET: A publicly available lexical resource for opinion mining, In: Proceedings of the 5th International Conference on Language Resources and Evaluations (LREC), 2006. Available from: http://www.lrec-conf.org/proceedings/lrec2006/pdf/384_pdf.pdf. |
| [20] |
M. Taboada, J. Brooke, M. Tofiloski, K. Voll, M. Stede, Lexicon-based methods for sentiment analysis, Comput. Linguist., 37 (2011), 267–307. https://doi.org/10.1162/COLI_A_00049 doi: 10.1162/COLI_A_00049
|
| [21] | B. Pang, L. Lee, Opinion mining and sentiment analysis, Now Publishers, Boston, MA, 2008, 1−135. https://doi.org/10.1561/1500000011 |
| [22] |
J. Serrano-Guerrero, M. Bani-Doumi, F. P. Romero, J. A. Olivas, A 2-tuple fuzzy linguistic model for recommending health care services grounded on aspect-based sentiment analysis, Expert Syst. Appl., 238 (2024). https://doi.org/10.1016/j.eswa.2023.122340 doi: 10.1016/j.eswa.2023.122340
|
| [23] |
G. G. Chowdhury, Natural language processing, Annu. Rev. Inf. Sci. Technol., 37 (2003), 51–89. https://doi.org/10.1002/ARIS.1440370103 doi: 10.1002/ARIS.1440370103
|
| [24] |
C. G. García, E. Núñ ez-Valdez, V. García-Díaz, C. P. G-Bustelo, J. M. Cueva-Lovelle, A review of artificial intelligence in the internet of things, Int. J. Interact. Multi., 5 (2019). https://doi.org/10.9781/IJIMAI.2018.03.004 doi: 10.9781/IJIMAI.2018.03.004
|
| [25] | R. Lopez-Martinez, G. Sierra, Research trends in the international literature on natural language processing, 2000−2019—A bibliometric study, J. Scientometr. Res., 9 (2020), 310–318. https://doi.org/10.5530/jscires.9.3.38 |
| [26] |
M. Regona, T. Yigitcanlar, B. Xia, R. Y. M. Li, Opportunities and adoption challenges of AI in the construction industry: A PRISMA review, J. Open Innov. Technol. Mark. Complex., 8 (2022), 45. https://doi.org/10.3390/JOITMC8010045 doi: 10.3390/JOITMC8010045
|
| [27] |
R. I. Mukhamediev, Y. Popova, Y. Kuchin, E. Zaitseva, A. Kalimoldayev, A. Symagulov, et al., Review of artificial intelligence and machine learning technologies: Classification, restrictions, opportunities and challenges, Mathematics, 10 (2022). https://doi.org/10.3390/math10152552 doi: 10.3390/math10152552
|
| [28] |
S. O. Abioye, L. O. Oyedele, L. Akanbi, A. Ajayi, J. M. D. Delgado, M. Bilal, et al., Artificial intelligence in the construction industry: A review of present status, opportunities and future challenges, J. Build. Eng., 44 (2021). https://doi.org/10.1016/J.JOBE.2021.103299 doi: 10.1016/J.JOBE.2021.103299
|
| [29] |
I. Bueno, R. A. Carrasco, R. Ureñ a, E. Herrera-Viedma, A business context aware decision-making approach for selecting the most appropriate sentiment analysis technique in e-marketing situations, Inf. Sci., 589 (2022), 300–320. https://doi.org/10.1016/J.INS.2021.12.080 doi: 10.1016/J.INS.2021.12.080
|
| [30] |
P. Nandwani, R. Verma, A review on sentiment analysis and emotion detection from text, Soc. Netw. Anal. Min., 11 (2021), 1–19. https://doi.org/10.1007/S13278-021-00776-6 doi: 10.1007/S13278-021-00776-6
|
| [31] | O. Kolchyna, T. T. P. Souza, P. C. Treleaven, T. Aste, Twitter sentiment analysis: Lexicon method, machine learning method and their combination, arXiv: 1507.00955, 2015. https://doi.org/10.48550/arXiv.1507.00955 |
| [32] |
C. J. Hutto, E. Gilbert, VADER: A parsimonious rule-based model for sentiment analysis of social media text, Proc. Int. AAAI Conf. Web Soc. Media, 8 (2014), 216–225. https://doi.org/10.1609/ICWSM.V8I1.14550 doi: 10.1609/ICWSM.V8I1.14550
|
| [33] |
W. Medhat, A. Hassan, H. Korashy, Sentiment analysis algorithms and applications: A survey, Ain Shams Eng. J., 5 (2014), 1093–1113. https://doi.org/10.1016/J.ASEJ.2014.04.011 doi: 10.1016/J.ASEJ.2014.04.011
|
| [34] |
A. A. A. Ahmed, S. Agarwal, I. G. A. Kurniawan, S. P. D. Anantadjaya, C. Krishnan, Business boosting through sentiment analysis using Artificial Intelligence approach, Int. J. Syst. Assur. Eng., 13 (2022), 699–709. https://doi.org/10.1007/S13198-021-01594-X doi: 10.1007/S13198-021-01594-X
|
| [35] |
A. Keramatfar, H. Amirkhani, Bibliometrics of sentiment analysis literature, J. Inf. Sci., 45 (2019), 3–15. https://doi.org/10.1177/0165551518761013 doi: 10.1177/0165551518761013
|
| [36] |
M. Hajiali, Big data and sentiment analysis: A comprehensive and systematic literature review, Concurr. Comp.-Pract. E., 32 (2020). https://doi.org/10.1002/cpe.5671 doi: 10.1002/cpe.5671
|
| [37] |
R. E. Bawack, S. F. Wamba, K. D. A. Carillo, S. Akter, Artificial intelligence in E-Commerce: A bibliometric study and literature review, Electron. Mark., 32 (2022), 297–338. https://doi.org/10.1007/s12525-022-00537-z doi: 10.1007/s12525-022-00537-z
|
| [38] |
F. Mirzaalian, E. Halpenny, Social media analytics in hospitality and tourism: A systematic literature review and future trends, J. Hosp. Tour. Technol., 10 (2019), 764–790. https://doi.org/10.1108/JHTT-08-2018-0078 doi: 10.1108/JHTT-08-2018-0078
|
| [39] |
Z. Drus, H. Khalid, Sentiment analysis in social media and its application: Systematic literature review, Procedia Comput. Sci., 161 (2019), 707–714. https://doi.org/10.1016/j.procs.2019.11.174 doi: 10.1016/j.procs.2019.11.174
|
| [40] |
S. Shayaa, N. I. Jaafar, S. Bahri, A. Sulaiman, P. S. Wai, Y. W. Chung, et al., Sentiment analysis of big data: Methods, applications, and open challenges, IEEE Access, 6 (2018). https://doi.org/10.1109/ACCESS.2018.2851311 doi: 10.1109/ACCESS.2018.2851311
|
| [41] |
A. Kumar, A. Jaiswal, Systematic literature review of sentiment analysis on Twitter using soft computing techniques, Concurr. Comp.-Pract. E., 32 (2020). https://doi.org/10.1002/cpe.5107 doi: 10.1002/cpe.5107
|
| [42] |
A. Sarirete, A bibliometric analysis of COVID-19 vaccines and sentiment analysis, Procedia Comput. Sci., 194 (2021), 280–287. https://doi.org/10.1016/j.procs.2021.10.083 doi: 10.1016/j.procs.2021.10.083
|
| [43] |
P. K. Jain, R. Pamula, G. Srivastava, A systematic literature review on machine learning applications for consumer sentiment analysis using online reviews, Comput. Sci. Rev., 41 (2021). https://doi.org/10.1016/j.cosrev.2021.100413 doi: 10.1016/j.cosrev.2021.100413
|
| [44] |
I. H. Musa, I. Zamit, K. Xu, K. Boutouhami, G. Qi, A comprehensive bibliometric analysis on opinion mining and sentiment analysis global research output, J. Inf. Sci., 49 (2023), 1506–1516. https://doi.org/10.1177/01655515211061866 doi: 10.1177/01655515211061866
|
| [45] |
S. Verma, Sentiment analysis of public services for smart society: Literature review and future research directions, Gov. Inform. Q., 39 (2022). https://doi.org/10.1016/j.giq.2022.101708 doi: 10.1016/j.giq.2022.101708
|
| [46] |
M. V. Mä ntylä , D. Graziotin, M. Kuutila, The evolution of sentiment analysis—A review of research topics, venues, and top cited papers, Comput. Sci. Rev., 27 (2018), 16–32. https://doi.org/10.1016/j.cosrev.2017.10.002 doi: 10.1016/j.cosrev.2017.10.002
|
| [47] |
J. Serrano-Guerrero, F. P. Romero, J. A. Olivas, Fuzzy logic applied to opinion mining: A review, Knowl.-Based Syst., 222 (2021). https://doi.org/10.1016/j.knosys.2021.107018 doi: 10.1016/j.knosys.2021.107018
|
| [48] |
M. Levine-Clark, E. L. Gil, A new comparative citation analysis: Google Scholar, Microsoft Academic, Scopus, and Web of Science, J. Bus. Financ. Libr., 26 (2021), 145–163. https://doi.org/10.1080/08963568.2021.1916724 doi: 10.1080/08963568.2021.1916724
|
| [49] |
M. A. Rojas-Sánchez, P. R. Palos-Sánchez, J. A. Folgado-Fernández, Systematic literature review and bibliometric analysis on virtual reality and education, Educ. Inf. Technol., 28 (2022), 155–192. https://doi.org/10.1007/S10639-022-11167-5 doi: 10.1007/S10639-022-11167-5
|
| [50] | G. Haddow, Bibliometric research, In: Research Methods (2 Eds.) (eds. K. Williamson and G. Johanson), Chandos Publishing, Oxford, UK, 2017,241−266. https://doi.org/10.1016/B978-0-08-102220-7.00010-8 |
| [51] |
N. Donthu, S. Kumar, D. Mukherjee, N. Pandey, W. M. Lim, How to conduct a bibliometric analysis: An overview and guidelines, J. Bus. Res., 133 (2021), 285–296. https://doi.org/10.1016/J.JBUSRES.2021.04.070 doi: 10.1016/J.JBUSRES.2021.04.070
|
| [52] | B. Kitchenham, S. Charters, Guidelines for performing systematic literature reviews in software engineering, Technical Report, EBSE Technical Report EBSE-2007-01, 2007. |
| [53] |
R. S. Rocha, M. Fantinato, The use of software product lines for business process management: A systematic literature review, Inf. Softw. Technol., 55 (2013), 1355–1373. https://doi.org/10.1016/j.infsof.2013.02.007 doi: 10.1016/j.infsof.2013.02.007
|
| [54] |
M. Aria, C. Cuccurullo, Bibliometrix: An R-tool for comprehensive science mapping analysis, J. Informetr. 11 (2017), 959–975. https://doi.org/10.1016/J.JOI.2017.08.007 doi: 10.1016/J.JOI.2017.08.007
|
| [55] |
E. F. Bonilla-Chaves, P. R. Palos-Sánchez, Exploring the evolution of human resource analytics: A bibliometric study, Behav. Sci., 13 (2023). https://doi.org/10.3390/bs13030244 doi: 10.3390/bs13030244
|
| [56] |
P. R. Palos-Sánchez, P. Baena-Luna, A. Badicu, J. C. Infante-Moro, Artificial intelligence and human resources management: A bibliometric analysis, Appl. Artif. Intell., 36 (2022). https://doi.org/10.1080/08839514.2022.2145631 doi: 10.1080/08839514.2022.2145631
|
| [57] |
Y. Qamar, R. K. Agrawal, T. A. Samad, C. J. C. Jabbour, When technology meets people: The interplay of artificial intelligence and human resource management, J. Enterp. Inf. Manag., 34 (2021), 1339–1370. https://doi.org/10.1108/JEIM-11-2020-0436 doi: 10.1108/JEIM-11-2020-0436
|
| [58] |
A. Singh, W. M. Lim, S. Jha, S. Kumar, M. V. Ciasullo, The state of the art of strategic leadership, J. Bus. Res., 158 (2023). https://doi.org/10.1016/j.jbusres.2023.113676 doi: 10.1016/j.jbusres.2023.113676
|
| [59] |
J. F. Arenas-Escaso, J. A. Folgado-Fernández, P. R. Palos-Sanchez, Digital disconnection as an opportunity for the tourism business: A bibliometric analysis, Emerg. Sci. J., 6 (2022), 1100–1113. https://doi.org/10.28991/ESJ-2022-06-05-013 doi: 10.28991/ESJ-2022-06-05-013
|
| [60] |
A. Mora-Cruz, P. R. Palos-Sanchez, Crowdfunding platforms: A systematic literature review and a bibliometric analysis, Int. Entrep. Manag. J., 19 (2023), 1257–1288. https://doi.org/10.1007/s11365-023-00856-3 doi: 10.1007/s11365-023-00856-3
|
| [61] |
J. A. Marino-Romero, P. R. Palos-Sánchez, F. Velicia-Martín, Evolution of digital transformation in SMEs management through a bibliometric analysis, Technol. Forecast. Soc., 199 (2024). https://doi.org/10.1016/j.techfore.2023.123014 doi: 10.1016/j.techfore.2023.123014
|
| [62] |
V. M. G. Abarca, P. R. Palos-Sanchez, E. Rus-Arias, Working in virtual teams: A systematic literature review and a bibliometric analysis, IEEE Access, 8 (2020). https://doi.org/10.1109/ACCESS.2020.3023546 doi: 10.1109/ACCESS.2020.3023546
|
| [63] |
A. Reyes, P. Rosso, T. Veale, A multidimensional approach for detecting irony in Twitter, Lang. Resour. Eval., 47 (2013), 239–268. https://doi.org/10.1007/S10579-012-9196-X doi: 10.1007/S10579-012-9196-X
|
| [64] |
F. H. Khan, S. Bashir, U. Qamar, TOM: Twitter opinion mining framework using hybrid classification scheme, Decis. Support Syst., 57 (2014), 245–257. https://doi.org/10.1016/J.DSS.2013.09.004 doi: 10.1016/J.DSS.2013.09.004
|
| [65] |
P. D. Vecchio, G. Mele, V. Ndou, G. Secundo, Creating value from social big data: Implications for smart tourism destinations, Inf. Process. Manag., 54 (2018), 847–860. https://doi.org/10.1016/J.IPM.2017.10.006 doi: 10.1016/J.IPM.2017.10.006
|
| [66] |
J. Sheng, J. Amankwah-Amoah, X. Wang, A multidisciplinary perspective of big data in management research, Int. J. Prod. Econ., 191 (2017), 97–112. https://doi.org/10.1016/J.IJPE.2017.06.006 doi: 10.1016/J.IJPE.2017.06.006
|
| [67] |
Y. C. Chang, C. H. Ku, C. H. Chen, Social media analytics: Extracting and visualizing Hilton hotel ratings and reviews from TripAdvisor, Int. J. Inf. Manag., 48 (2019), 263–279. https://doi.org/10.1016/J.IJINFOMGT.2017.11.001 doi: 10.1016/J.IJINFOMGT.2017.11.001
|
| [68] | S. M. Mohammad, Challenges in sentiment analysis, In: A Practical Guide to Sentiment Analysis (eds. E Cambria, D Das, S Bandyopadhyay, A Feraco), Springer, Cham, 2017, 61–83. https://doi.org/10.1007/978-3-319-55394-8_4 |
| [69] |
A. Nazir, Y. Rao, L. Wu, L. Sun, Issues and challenges of aspect-based sentiment analysis: A comprehensive survey, IEEE Trans. Affect. Comput., 13 (2022), 845–863. https://doi.org/10.1109/TAFFC.2020.2970399 doi: 10.1109/TAFFC.2020.2970399
|
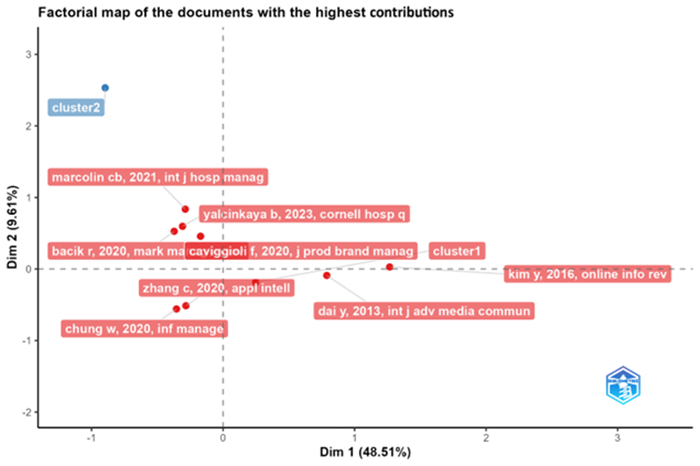
| [70] |
C. B. Marcolin, J. L. Becker, F. Wild, A. Behr, G. Schiavi, Listening to the voice of the guest: A framework to improve decision-making processes with text data, Int. J. Hosp. Manag., 94 (2021). https://doi.org/10.1016/J.IJHM.2020.102853 doi: 10.1016/J.IJHM.2020.102853
|
| [71] |
R. Bacik, R. Fedorko, B. Gavurova, M. Olearova, M. Rigelsky, Hotel marketing policy: Role of rating in consumer decision making, Mark. Manag. Innov., 11 (2020), 11–25. https://doi.org/10.21272/MMI.2020.2-01 doi: 10.21272/MMI.2020.2-01
|
| [72] |
B. Yalcinkaya, D. R. Just, Comparison of customer reviews for local and chain restaurants: Multilevel approach to google reviews data, Cornell Hosp. Q., 64 (2023), 63–73. https://doi.org/10.1177/19389655221102388 doi: 10.1177/19389655221102388
|
| [73] |
F. Caviggioli, L. Lamberti, P. Landoni, P. Meola, Technology adoption news and corporate reputation: Sentiment analysis about the introduction of Bitcoin, J. Prod. Brand Manag., 29 (2020), 877–897. https://doi.org/10.1108/JPBM-03-2018-1774 doi: 10.1108/JPBM-03-2018-1774
|
| [74] |
Y. Kim, R. Dwivedi, J. Zhang, S. R. Jeong, Competitive intelligence in social media Twitter: IPhone 6 vs. Galaxy S5, Online Inf. Rev., 40 (2016), 42–61. https://doi.org/10.1108/OIR-03-2015-0068 doi: 10.1108/OIR-03-2015-0068
|
| [75] |
W. Chung, D. Zeng, Dissecting emotion and user influence in social media communities: An interaction modeling approach, Inform. Manage. 57 (2020), 103−108. https://doi.org/10.1016/J.IM.2018.09.008 doi: 10.1016/J.IM.2018.09.008
|
| [76] |
Y. Dai, T. Kakkonen, E. Arendarenko, D. Liao, E. Sutinen, MOETA: A novel text-mining model for collecting and analysing competitive intelligence, Int. J. Adv. Media Commun., 5 (2013), 19–39. https://doi.org/10.1504/IJAMC.2013.053672 doi: 10.1504/IJAMC.2013.053672
|
| [77] |
S. F. Eletter, Sentiment analysis towards actionable intelligence via deep learning, TEM J., 9 (2020), 1663–1668. https://doi.org/10.18421/TEM94-44 doi: 10.18421/TEM94-44
|
| [78] |
Y. Basani, H. V. Sibuea, S. I. P. Sianipar, J. P. Samosir, Application of sentiment analysis on product review E-commerce, J. Phys. Conf. Ser., 1175 (2019). https://doi.org/10.1088/1742-6596/1175/1/012103 doi: 10.1088/1742-6596/1175/1/012103
|
| [79] |
B. Balusamy, T. Murali, A. Thangavelu, P. V. Krishna, A multi-level text classifier for feedback analysis using tweets to enhance product performance, Int. J. Electron. Mark. Retail., 6 (2015), 315–338. https://doi.org/10.1504/IJEMR.2015.073455 doi: 10.1504/IJEMR.2015.073455
|
| [80] |
A. Boumhidi, A. Benlahbib, E. H. Nfaoui, Cross-platform reputation generation system based on aspect-based sentiment analysis, IEEE Access, 10 (2022), 2515–2531. https://doi.org/10.1109/ACCESS.2021.3139956 doi: 10.1109/ACCESS.2021.3139956
|
| [81] |
G. A. O. Júnior, R. O. Albuquerque, C. A. B. Andrade, R. T. Sousa, A. L. S. Orozco, L. J. G. Villalba, Anonymous real-time analytics monitoring solution for decision making supported by sentiment analysis, Sensors, 20 (2020), 4557. https://doi.org/10.3390/s20164557 doi: 10.3390/s20164557
|
| [82] |
J. Serrano-Guerrero, J. A. Olivas, F. P. Romero, E. Herrera-Viedma, Sentiment analysis: A review and comparative analysis of web services, Inf. Sci., 311 (2015), 18–38. https://doi.org/10.1016/j.ins.2015.03.040 doi: 10.1016/j.ins.2015.03.040
|
| [83] |
M. Binder, B. Heinrich, M. Hopf, A. Schiller, Global reconstruction of language models with linguistic rules—Explainable AI for online consumer reviews, Electron. Mark., 32 (2022), 2123–2138. https://doi.org/10.1007/S12525-022-00612-5 doi: 10.1007/S12525-022-00612-5
|
| [84] |
L. Xia, Historical profile will tell? A deep learning-based multi-level embedding framework for adverse drug event detection and extraction, Decis. Support Syst., 160 (2022), 113832. https://doi.org/10.1016/J.DSS.2022.113832 doi: 10.1016/J.DSS.2022.113832
|
| [85] |
J. R. Saura, D. Ribeiro-Soriano, D. Palacios-Marqués, Data-driven strategies in operation management: Mining user-generated content in Twitter, Ann. Oper. Res., 2022, 1–21. https://doi.org/10.1007/S10479-022-04776-3 doi: 10.1007/S10479-022-04776-3
|
| [86] |
P. Eachempati, P. R. Srivastava, A. Kumar, K. H. Tan, S. Gupta, Validating the impact of accounting disclosures on stock market: A deep neural network approach, Technol. Forecast. Soc., 170 (2021), 120903. https://doi.org/10.1016/J.TECHFORE.2021.120903 doi: 10.1016/J.TECHFORE.2021.120903
|
| [87] |
R. K. Singh, H. K. Verma, Influence of social media analytics on online food delivery systems, Int. J. Inf. Syst. Model., 11 (2020), 1–21. https://doi.org/10.4018/IJISMD.2020070101 doi: 10.4018/IJISMD.2020070101
|
| [88] |
Y. Luo, Z. Yang, Y. Liang, X. Zhang, H. Xiao, Exploring energy-saving refrigerators through online e-commerce reviews: an augmented mining model based on machine learning methods, Kybernetes, 51 (2022), 2768–2794. https://doi.org/10.1108/K-11-2020-0788 doi: 10.1108/K-11-2020-0788
|
| [89] |
D. Liang, Z. Dai, M. Wang, J. Li, Web celebrity shop assessment and improvement based on online review with probabilistic linguistic term sets by using sentiment analysis and fuzzy cognitive map, Fuzzy Optim. Decis. Mak., 19 (2020), 561–586. https://doi.org/10.1007/S10700-020-09327-8 doi: 10.1007/S10700-020-09327-8
|
| [90] |
F. Zhou, M. K. Lim, Y. He, S. Pratap, What attracts vehicle consumers' buying: A Saaty scale-based VIKOR (SSC-VIKOR) approach from after-sales textual perspective?, Ind. Manag. Data Syst., 120 (2020), 57–78. https://doi.org/10.1108/IMDS-01-2019-0034 doi: 10.1108/IMDS-01-2019-0034
|
| [91] |
H. Shi, Z. Ma, D. Chong, W. He, The impact of Facebook on real estate sales, J. Manag. Anal., 8 (2021), 101–112. https://doi.org/10.1080/23270012.2020.1858985 doi: 10.1080/23270012.2020.1858985
|
| [92] |
A. Alamsyah, A. A. Indraswari, Social network and sentiment analysis for social customer relationship management in Indonesia banking sector, Adv. Sci. Lett., 23 (2017), 3808–3812. https://doi.org/10.1166/ASL.2017.9279 doi: 10.1166/ASL.2017.9279
|
| [93] |
C. M. Q. Ramos, A. M. Casado-Molina, J. Ignácio-Peláez, An innovative management perspective for organizations through a reputation intelligence management model, Int. J. Inf. Syst. Model., 11 (2019), 1–20. https://doi.org/10.4018/IJISSS.2019100101 doi: 10.4018/IJISSS.2019100101
|
| [94] |
S. Symeonidis, G. Peikos, A. Arampatzis, Unsupervised consumer intention and sentiment mining from microblogging data as a business intelligence tool, Oper. Res., 22 (2022), 6007–6036. https://doi.org/10.1007/S12351-022-00714-0 doi: 10.1007/S12351-022-00714-0
|
| [95] |
E. Kauffmann, J. Peral, D. Gil, A. Ferrández, R. Sellers, H. Mora, Managing marketing decision-making with sentiment analysis: An evaluation of the main product features using text data mining, Sustainability, 11 (2019). https://doi.org/10.3390/su11154235 doi: 10.3390/su11154235
|
| [96] |
H. Tufail, M. U. Ashraf, K. Alsubhi, H. M. Aljahdali, The effect of fake reviews on e-commerce during and after Covid-19 pandemic: SKL-based fake reviews detection, IEEE Access, 10 (2022), 25555–25564. https://doi.org/10.1109/ACCESS.2022.3152806 doi: 10.1109/ACCESS.2022.3152806
|
| [97] |
Y. Luo, X. Xu, Comparative study of deep learning models for analyzing online restaurant reviews in the era of the COVID-19 pandemic, Int. J. Hosp. Manag., 94 (2021), 102849. https://doi.org/10.1016/J.IJHM.2020.102849 doi: 10.1016/J.IJHM.2020.102849
|
| [98] |
H. Li, B. X. B. Yu, G. Li, H. Gao, Restaurant survival prediction using customer-generated content: An aspect-based sentiment analysis of online reviews, Tour. Manag., 96 (2023), 104707. https://doi.org/10.1016/J.TOURMAN.2022.104707 doi: 10.1016/J.TOURMAN.2022.104707
|
| [99] | P. Basu, T. S. Roy, A. Singhal, But how robust is RoBERTa actually?: A benchmark of SOTA transformer networks for sexual harassment detection on Twitter, In: 2021 Fifth International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), 2021, 1328–1333. https://doi.org/10.1109/I-SMAC52330.2021.9640861 |
| [100] |
D. Perea-Khalifi, A. I. Irimia-Diéguez, P. Palos-Sánchez, Exploring the determinants of the user experience in P2P payment systems in Spain: A text mining approach, Financ. Innov., 10 (2024), 2. https://doi.org/10.1186/s40854-023-00496-0 doi: 10.1186/s40854-023-00496-0
|


Figures(12) / Tables(13)

J. A. Aguilar-Moreno, P. R. Palos-Sanchez, R. Pozo-Barajas. Sentiment analysis to support business decision-making. A bibliometric study[J]. AIMS Mathematics, 2024, 9(2): 4337-4375. doi: 10.3934/math.2024215







 DownLoad:
DownLoad: