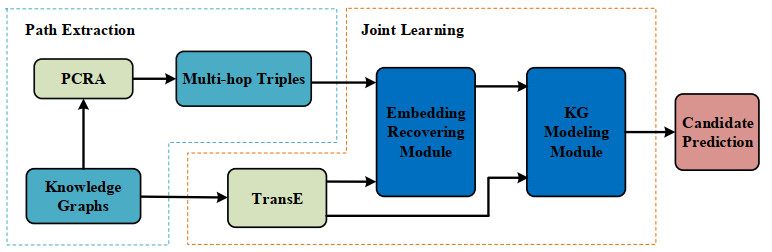
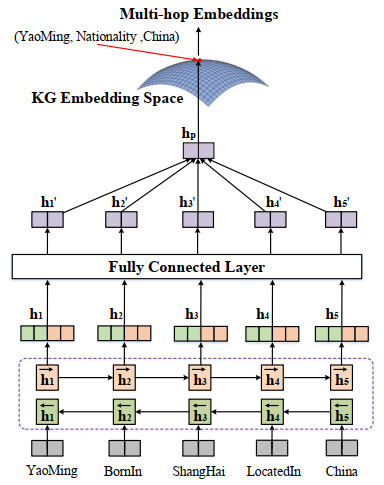
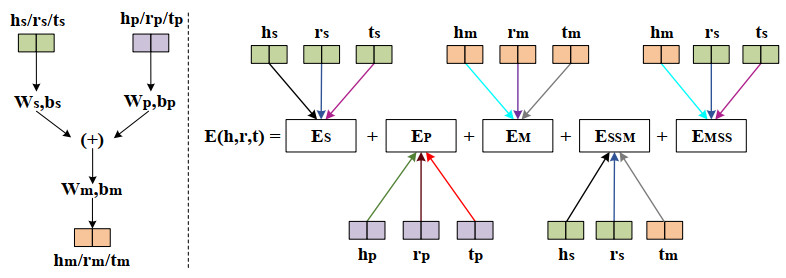
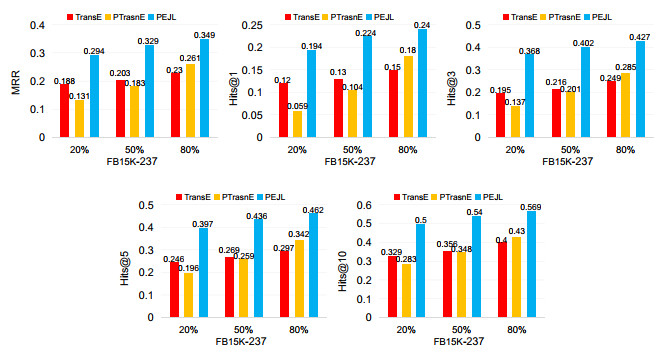
Knowledge graphs (KGs) often suffer from incompleteness. Knowledge graph completion (KGC) is proposed to complete missing components in a KG. Most KGC methods focus on direct relations and fail to leverage rich semantic information in multi-hop paths. In contrast, path-based embedding methods can capture path information and utilize extra semantics to improve KGC. However, most path-based methods cannot take advantage of full multi-hop information and neglect to capture multiple semantic associations between single and multi-hop triples. To bridge the gap, we propose a novel path-enhanced joint learning approach called PEJL for KGC. Rather than learning multi-hop representations, PEJL can recover multi-hop embeddings by encoding full multi-hop components. Meanwhile, PEJL extends the definition of translation energy functions and generates new semantic representations for each multi-hop component, which is rarely considered in path-based methods. Specifically, we first use the path constraint resource allocation (PCRA) algorithm to extract multi-hop triples. Then we use an embedding recovering module consisting of a bidirectional gated recurrent unit (GRU) layer and a fully connected layer to obtain multi-hop embeddings. Next, we employ a KG modeling module to leverage various semantic information and model the whole knowledge graph based on translation methods. Finally, we define a joint learning approach to train our proposed PEJL. We evaluate our model on two KGC datasets: FB15K-237 and NELL-995. Experiments show the effectiveness and superiority of PEJL.
Citation: Xinyu Lu, Lifang Wang, Zejun Jiang, Shizhong Liu, Jiashi Lin. PEJL: A path-enhanced joint learning approach for knowledge graph completion[J]. AIMS Mathematics, 2023, 8(9): 20966-20988. doi: 10.3934/math.20231067
Knowledge graphs (KGs) often suffer from incompleteness. Knowledge graph completion (KGC) is proposed to complete missing components in a KG. Most KGC methods focus on direct relations and fail to leverage rich semantic information in multi-hop paths. In contrast, path-based embedding methods can capture path information and utilize extra semantics to improve KGC. However, most path-based methods cannot take advantage of full multi-hop information and neglect to capture multiple semantic associations between single and multi-hop triples. To bridge the gap, we propose a novel path-enhanced joint learning approach called PEJL for KGC. Rather than learning multi-hop representations, PEJL can recover multi-hop embeddings by encoding full multi-hop components. Meanwhile, PEJL extends the definition of translation energy functions and generates new semantic representations for each multi-hop component, which is rarely considered in path-based methods. Specifically, we first use the path constraint resource allocation (PCRA) algorithm to extract multi-hop triples. Then we use an embedding recovering module consisting of a bidirectional gated recurrent unit (GRU) layer and a fully connected layer to obtain multi-hop embeddings. Next, we employ a KG modeling module to leverage various semantic information and model the whole knowledge graph based on translation methods. Finally, we define a joint learning approach to train our proposed PEJL. We evaluate our model on two KGC datasets: FB15K-237 and NELL-995. Experiments show the effectiveness and superiority of PEJL.

| [1] |
W. Lee, W. Shin, B. Jagvaral, J. Roh, M. Kim, M. Lee, et al., A path-based relation networks model for knowledge graph completion, Expert Syst. Appl., 182 (2021), 115273. https://doi.org/10.1016/j.eswa.2021.115273 doi: 10.1016/j.eswa.2021.115273

|
| [2] | K. D. Bollacker, C. Evans, P. K. Paritosh, T. Sturge, J. Taylor, Freebase: A collaboratively created graph database for structuring human knowledge, In: Proceedings of the ACM SIGMOD International Conference on Management of Data, SIGMOD 2008, Vancouver, BC, Canada, June 10–12, 2008 (Ed. J. T. Wang), ACM, 2008, 1247–1250. |
| [3] |
G. A. Miller, Wordnet: A lexical database for english, Commun. ACM, 38 (1995), 39–41. https://doi.org/10.1145/219717.219748 doi: 10.1145/219717.219748
|
| [4] |
M. Chen, T. Ma, X. Zhou, Cocnn: Co-occurrence CNN for recommendation, Expert Syst. Appl., 195 (2022), 116595. https://doi.org/10.1016/j.eswa.2022.116595 doi: 10.1016/j.eswa.2022.116595
|
| [5] |
Z. A. Guven, M. O. Ünalir, Natural language based analysis of squad: An analytical approach for BERT, Expert Syst. Appl., 195 (2022), 116592. https://doi.org/10.1016/j.eswa.2022.116592 doi: 10.1016/j.eswa.2022.116592
|
| [6] |
Z. Zhao, Z. Gou, Y. Du, J. Ma, T. Li, R. Zhang, A novel link prediction algorithm based on inductive matrix completion, Expert Syst. Appl., 188 (2022), 116033. https://doi.org/10.1016/j.eswa.2021.116033 doi: 10.1016/j.eswa.2021.116033
|
| [7] |
J. Lehmann, R. Isele, M. Jakob, A. Jentzsch, D. Kontokostas, P. N. Mendes, et al., Dbpedia-A large-scale, multilingual knowledge base extracted from wikipedia, Semant. Web, 6 (2015), 167–195. https://doi.org/10.1093/emph/eov017 doi: 10.1093/emph/eov017
|
| [8] | X. Chen, S. Jia, Y. Xiang, A review: Knowledge reasoning over knowledge graph, Expert Syst. Appl., 141. |
| [9] | A. Bordes, N. Usunier, A. García-Durán, J. Weston, O. Yakhnenko, Translating embeddings for modeling multi-relational data, In: Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013. Proceedings of a meeting held December 5–8, 2013, Lake Tahoe, Nevada, United States (Eds. C. J. C. Burges, L. Bottou, Z. Ghahramani, K. Q. Weinberger), 2013, 2787–2795. |
| [10] | Z. Wang, J. Zhang, J. Feng, Z. Chen, Knowledge graph embedding by translating on hyperplanes, In: Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, July 27–31, 2014, Québec City, Québec, Canada (Eds. C. E. Brodley, P. Stone), AAAI Press, 2014, 1112–1119. |
| [11] | Y. Lin, Z. Liu, M. Sun, Y. Liu, X. Zhu, Learning entity and relation embeddings for knowledge graph completion, In: Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, January 25–30, 2015, Austin, Texas, USA (Eds. B. Bonet, S. Koenig), AAAI Press, 2015, 2181–2187. |
| [12] | M. Nickel, V. Tresp, H. Kriegel, A three-way model for collective learning on multi-relational data, In: Proceedings of the 28th International Conference on Machine Learning, ICML 2011, Bellevue, Washington, USA, June 28–July 2, 2011 (Eeds. L. Getoor, T. Scheffer), Omnipress, 2011,809–816. |
| [13] | B. Yang, W. Yih, X. He, J. Gao, L. Deng, Embedding entities and relations for learning and inference in knowledge bases, In: 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7–9, 2015, Conference Track Proceedings (Eds. Y. Bengio, Y. LeCun), 2015. |
| [14] | T. Trouillon, J. Welbl, S. Riedel, É. Gaussier, G. Bouchard, Complex embeddings for simple link prediction, In: Proceedings of the 33nd International Conference on Machine Learning, ICML 2016, New York City, NY, USA, June 19-24, 2016 (Eds. M. Balcan, K. Q. Weinberger), vol. 48 of JMLR Workshop and Conference Proceedings, JMLR.org, 2016, 2071–2080. |
| [15] | Y. Lin, Z. Liu, H. Luan, M. Sun, S. Rao, S. Liu, Modeling relation paths for representation learning of knowledge bases, In: Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, EMNLP 2015, Lisbon, Portugal, September 17–21, 2015 (Eds. L. Màrquez, C. Callison-Burch, J. Su, D. Pighin, Y. Marton), The Association for Computational Linguistics, 2015,705–714. |
| [16] | S. Guo, Q. Wang, L. Wang, B. Wang, L. Guo, Knowledge graph embedding with iterative guidance from soft rules, In: Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, Louisiana, USA, February 2–7, 2018 (Eds. S. A. McIlraith, K. Q. Weinberger), AAAI Press, 2018, 4816–4823. |
| [17] | R. Biswas, M. Alam, H. Sack, Madlink: Attentive multihop and entity descriptions for link prediction in knowledge graphs, 2021. |
| [18] | X. Long, M. Yao, L. Zhuang, H. Li, S. Wang, Path ranking model for entity prediction, In: 2021 IEEE International Conference on Multimedia and Expo, ICME 2021, Shenzhen, China, July 5–9, 2021, IEEE, 2021, 1–6. |
| [19] |
G. Niu, B. Li, Y. Zhang, Y. Sheng, C. Shi, J. Li, et al., Joint semantics and data-driven path representation for knowledge graph reasoning, Neurocomputing, 483 (2022), 249–261. https://doi.org/10.1016/j.neucom.2022.02.011 doi: 10.1016/j.neucom.2022.02.011
|
| [20] | N. Lao, T. M. Mitchell, W. W. Cohen, Random walk inference and learning in A large scale knowledge base, In: Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, EMNLP 2011, 27–31 July 2011, John McIntyre Conference Centre, Edinburgh, UK, A meeting of SIGDAT, a Special Interest Group of the ACL, ACL, 2011,529–539. |
| [21] | M. Nickel, L. Rosasco, T. A. Poggio, Holographic embeddings of knowledge graphs, In: Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, February 12–17, 2016, Phoenix, Arizona, USA (Eds. D. Schuurmans, M. P. Wellman), AAAI Press, 2016, 1955–1961. |
| [22] | L. Guo, Q. Zhang, W. Ge, W. Hu, Y. Qu, DSKG: A deep sequential model for knowledge graph completion, In: Knowledge Graph and Semantic Computing. Knowledge Computing and Language Understanding-Third China Conference, CCKS 2018, Tianjin, China, August 14–17, 2018, Revised Selected Papers, (Eds. J. Zhao, F. van Harmelen, J. Tang, X. Han, Q. Wang, X. Li), vol. 957 of Communications in Computer and Information Science, Springer, 2018, 65–77. |
| [23] | Z. Zhang, J. Cai, Y. Zhang, J. Wang, Learning hierarchy-aware knowledge graph embeddings for link prediction, In: The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, February 7–12, 2020, AAAI Press, 2020, 3065–3072. |
| [24] | Y. Bai, Z. Ying, H. Ren, J. Leskovec, Modeling heterogeneous hierarchies with relation-specific hyperbolic cones, Advances in Neural Information Processing Systems, 34. |
| [25] | Z. Cao, Q. Xu, Z. Yang, X. Cao, Q. Huang, Dual quaternion knowledge graph embeddings, In: Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, February 2–9, 2021, AAAI Press, 2021, 6894–6902. |
| [26] |
A. Zeb, A. U. Haq, D. Zhang, J. Chen, Z. Gong, KGEL: A novel end-to-end embedding learning framework for knowledge graph completion, Expert Syst. Appl., 167 (2021), 114164. https://doi.org/10.1016/j.eswa.2020.114164 doi: 10.1016/j.eswa.2020.114164
|
| [27] | M. Zhang, Q. Wang, W. Xu, W. Li, S. Sun, Discriminative path-based knowledge graph embedding for precise link prediction, In: Advances in Information Retrieval - 40th European Conference on IR Research, ECIR 2018, Grenoble, France, March 26–29, 2018, Proceedings (Eds. G. Pasi, B. Piwowarski, L. Azzopardi, A. Hanbury), vol. 10772 of Lecture Notes in Computer Science, Springer, 2018,276–288. |
| [28] |
M. Taghian, A. Asadi, R. Safabakhsh, Learning financial asset-specific trading rules via deep reinforcement learning, Expert Syst. Appl., 195 (2022), 116523. https://doi.org/10.1016/j.eswa.2022.116523 doi: 10.1016/j.eswa.2022.116523
|
| [29] | W. Xiong, T. Hoang, W. Y. Wang, Deeppath: A reinforcement learning method for knowledge graph reasoning, In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, EMNLP 2017, Copenhagen, Denmark, September 9–11, 2017 (Eds. M. Palmer, R. Hwa, S. Riedel), Association for Computational Linguistics, 2017,564–573. |
| [30] | S. Guo, Q. Wang, L. Wang, B. Wang, L. Guo, Jointly embedding knowledge graphs and logical rules, In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, EMNLP 2016, Austin, Texas, USA, November 1–4, 2016 (eds. J. Su, X. Carreras, K. Duh), The Association for Computational Linguistics, 2016,192–202. |
| [31] | Y. Shen, N. Ding, H. Zheng, Y. Li, M. Yang, Modeling relation paths for knowledge graph completion, IEEE Trans. Knowl. Data Eng., 33 (2021), 3607–3617. |
| [32] |
X. Lu, L. Wang, Z. Jiang, S. He, S. Liu, MMKRL: A robust embedding approach for multi-modal knowledge graph representation learning, Appl. Intell., 52 (2022), 7480–7497. https://doi.org/10.1007/s10489-021-02693-9 doi: 10.1007/s10489-021-02693-9
|
| [33] | X. Huang, J. Zhang, D. Li, P. Li, Knowledge graph embedding based question answering, In: Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, WSDM 2019, Melbourne, VIC, Australia, February 11–15, 2019 (Eds. J. S. Culpepper, A. Moffat, P. N. Bennett, K. Lerman), ACM, 2019,105–113. |
| [34] | K. Cho, B. van Merrienboer, Ç. Gülçehre, D. Bahdanau, F. Bougares, H. Schwenk, et al., Learning phrase representations using RNN encoder-decoder for statistical machine translation, In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, EMNLP 2014, October 25-29, 2014, Doha, Qatar, A meeting of SIGDAT, a Special Interest Group of the ACL (Eds. A. Moschitti, B. Pang, W. Daelemans), ACL, 2014, 1724–1734. |
| [35] |
R. Xie, S. Heinrich, Z. Liu, C. Weber, Y. Yao, S. Wermter, et al., Integrating image-based and knowledge-based representation learning, IEEE Trans. Cogn. Dev. Syst., 12 (2020), 169–178. https://doi.org/10.1109/TCDS.2019.2906685 doi: 10.1109/TCDS.2019.2906685
|
| [36] | T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, J. Dean, Distributed representations of words and phrases and their compositionality, In: Advances in Neural Information Processing Systems 26: 27th Annual Conference on Neural Information Processing Systems 2013. Proceedings of a meeting held December 5-8, 2013, Lake Tahoe, Nevada, United States (Eds. C. J. C. Burges, L. Bottou, Z. Ghahramani, K. Q. Weinberger), 2013, 3111–3119. |
| [37] | Q. Wang, Z. Mao, B. Wang, L. Guo, Knowledge graph embedding: A survey of approaches and applications, IEEE Trans. Knowl. Data Eng., 29 (2017), 2724–2743. |

Figures(7) / Tables(6)

Xinyu Lu, Lifang Wang, Zejun Jiang, Shizhong Liu, Jiashi Lin. PEJL: A path-enhanced joint learning approach for knowledge graph completion[J]. AIMS Mathematics, 2023, 8(9): 20966-20988. doi: 10.3934/math.20231067







 DownLoad:
DownLoad: