Citation: Jesús Gómez-Gardeñes, Ernesto Estrada. Network bipartitioning in the anti-communicability Euclidean space[J]. AIMS Mathematics, 2021, 6(2): 1153-1174. doi: 10.3934/math.2021070

| [1] | A. Pothen, Graph Partitioning Algorithms with Applications to Scientific Computing, Technical Report TR-97-03, Old Dominion University, Norfolk, Virginia, 1997. |
| [2] | D. A. Spielman, S.-H. Teng, Spectral Partitioning Works: Planar Graphs and Finite Element Meshes. In 37th Annual Symposium on Foundations of Computer Science, IEEE Computer Society, New York, New York, (1997), 96-105. |
| [3] |
T. Bui, C. Leland, Finding good approximate vertex and edge partitions is NP-hard, Inform. Proces. Lett., 42 (1992), 153-159. doi: 10.1016/0020-0190(92)90140-Q

|
| [4] |
C. J. Alpert, A. B. Kahng, Recent directions in netlist partitioning, Integration, 19 (1995), 1-81. doi: 10.1016/0167-9260(95)00008-4
|
| [5] | B. Kernighan, S. Lin, An effective heuristic algorithm for partitioning graphs, Bell Syst. Tech J., 49 (1972), 291-307. |
| [6] | R. Battiti, A. Bertossi, Differential Greedy for the 0-1 Equicut Problem. In D. Du and P. Pardalos, Editors, Proceedings of the DIMACS Workshop on Network Design: Connectivity and Facilities Location, Volume 40 of DIMACS Series in Discrete Mathematics and Theoretical Computer Science, American Mathematical Society, Providence, Rhode Island, (1998), 3-21. |
| [7] |
H. D. Simon, Partitioning of Unstructured Problems for Parallel Processing, Comput. Syst. Eng., 2 (1991), 135-148. doi: 10.1016/0956-0521(91)90014-V
|
| [8] |
B. Hendrickson, R. Leland, An Improved Spectral Graph Partitioning Algorithm for Mapping Parallel Computations, SIAM J. Scient. Comput., 16 (1995), 452-469. doi: 10.1137/0916028
|
| [9] | G. Karypis, V. Kumar, MultilevelGraph Partitioning Schemes. In Proceedings of the Twenty- fourth International Conference on Parallel Processing, Oconomowoc, Wisconsin, (1995), 113-122. |
| [10] |
D. S. Johnson, C. R. Aragon, L. A. McGeoch, C. Schevon, Optimization by Simulated Annealing; Part Ⅰ, Graph Partitioning, Oper. Res., 37 (1989), 865-892. doi: 10.1287/opre.37.6.865
|
| [11] | R. Battiti, A. Bertossi, Greedy, Prohibition, and Reactive Heuristics for Graph- Partitioning, IEEE Trans. Comput., 48 (1997), 361-385. |
| [12] |
T. N. Bui, B. R. Moon, Genetic Algorithm and Graph Partitioning, IEEE Trans. Comput., 45 (1996), 841-855. doi: 10.1109/12.508322
|
| [13] | A. G. Steenbeek, E. Marchiori, A. E. Eiben, Finding Balanced Graph Bi-Partitions Using a Hybrid Genetic Algorithm. In: Proceedings of the IEEE International Conference on Evolutionary Computation ICEC'98, IEEE Press, Piscataway, New Jersey, (1998), 90-95. |
| [14] | C. Hohn, C. Reeves, Graph Partitioning Using Genetic Algorithms. In Sechi, G. R., Editor, Proceedings of the Second International Conference on Massively Parallel Computing Systems, IEEE Computer Society Press, Piscataway, New Jersey, (1996), 27-43. |
| [15] |
H. Inayoshi, B. Manderick, The Weighted Graph Bi-Partitioning Problem: A Look at GA Performance, Lect. Notes Comput. Sci., 866 (1994), 617-625. doi: 10.1007/3-540-58484-6_304
|
| [16] |
G. Laszewski, H. Muhlenbein, Partitioning a Graph with a Parallel Genetic Algorithm, Lect. Notes Comput. Sci., 496 (1991), 165-169. doi: 10.1007/BFb0029748
|
| [17] | J. C. Angles D'Auriac, M. Preissmann, A. Sebő. Optimal Cuts in Graphs and Statistical Mechanics, Math. Comput. Model., 26 (1997), 1-11. |
| [18] |
S. Kirkpatrick, C. D. Gelatt, M. P. Vecchi, Optimization by Simulated Annealing, Science, 220 (1983), 671-680. doi: 10.1126/science.220.4598.671
|
| [19] | M. Mezard, G. Parisi, M. A. Virasoro, Spin Glass Theory and Beyond, World Scientific, Singapore, 1987. |
| [20] |
Y. Fu, P. W. Anderson, Application of statistical mechanics to NP-complete problems in combinatorial optimisation, J. Phys. A: Math. Gen., 19 (1986), 1605. doi: 10.1088/0305-4470/19/9/033
|
| [21] | W. Wietheget, D. Sherrington, Bipartitioning of random graphs of fixed extensive valence, J. Phys. A: Math. Gen., 20 (1987), L9-L11. |
| [22] |
W. Liao, Graph-Bipartitioning Problem, Phys. Rev. Lett., 59 (1987), 1625. doi: 10.1103/PhysRevLett.59.1625
|
| [23] |
P. Facchi, G. Florio, U. Marzolino, G. Parisi, S. Pascazio, Multipartite entanglement and frustration, New. J. Phys., 12 (2010), 025015. doi: 10.1088/1367-2630/12/2/025015
|
| [24] | E. Estrada, The structure of complex networks: theory and applications, Oxford University Press, 2012. |
| [25] |
M. E. Newman, The structure and function of complex networks, SIAM Rev., 45 (2003), 167-256. doi: 10.1137/S003614450342480
|
| [26] |
M. E. Newman, Finding community structure in networks using the eigenvectors of matrices, Phys. Rev. E, 74 (2006), 036104. doi: 10.1103/PhysRevE.74.036104
|
| [27] | A. Concas, S. Noschese, L. Reichel, G. Rodriguez, A spectral method for bipartizing a network and detecting a large anti-community, J. Comput. Appl. Math., (2019), in press. |
| [28] |
M. Zarei, K. A. Samani, Eigenvectors of network complement reveal community structure more accurately, Physica A, 388 (2009), 1721-1730. doi: 10.1016/j.physa.2009.01.007
|
| [29] |
Q. Yu, L. Chen, A new method for detecting anti-community structures in complex networks, J. Phys.: Conf. Ser., 410 (2013), 012103. doi: 10.1088/1742-6596/410/1/012103
|
| [30] |
L. Chen, Q. Yu, B. Chen, Anti-modularity and anti-community detecting in complex networks, Inform. Sci., 275 (2014), 293-313. doi: 10.1016/j.ins.2014.02.040
|
| [31] | K. N. Bales, Z. D. Eager, A. A. Harkin, Efficiency-modularity for finding communities and anticommunities in networks, J. Complex Net., 5 (2016), 70-83. |
| [32] |
P. Holme, F. Liljeros, C. R. Edling, B. J. Kim, Network bipartivity, Phys. Rev. E, 68 (2003), 056107. doi: 10.1103/PhysRevE.68.056107
|
| [33] |
E. Estrada, J. A. Rodriguez-Velazquez, Spectral measures of bipartivity in complex networks, Phys. Rev. E, 72 (2005), 046105. doi: 10.1103/PhysRevE.72.046105
|
| [34] | E. Estrada, J. Gomez-Gardenes, Network bipartivity and the transportation efficiency of european passenger airlines, Physica D, 323 (2016), 57-63. |
| [35] |
T. Pisanski, M. Randić, Use of the Szeged index and the revised Szeged index for measuring network bipartivity, Discr. Appl. Math., 158 (2010), 1936-1944. doi: 10.1016/j.dam.2010.08.004
|
| [36] |
E. Estrada, N. Hatano, Communicability in complex networks, Phys. Rev. E, 77 (2008), 036111. doi: 10.1103/PhysRevE.77.036111
|
| [37] |
E. Estrada, N. Hatano, Statistical-mechanical approach to subgraph centrality in complex networks, Chem. Phys. Lett., 439 (2007), 247-251. doi: 10.1016/j.cplett.2007.03.098
|
| [38] |
E. Estrada, N. Hatano, M. Benzi, The physics of communicability in complex networks, Phys. Rep., 514 (2012), 89-119. doi: 10.1016/j.physrep.2012.01.006
|
| [39] |
E. Estrada, The communicability distance in graphs, Lin. Algebra Appl., 436 (2012), 4317-4328. doi: 10.1016/j.laa.2012.01.017
|
| [40] |
E. Estrada, Complex networks in the Euclidean space of communicability distances, Phys. Rev. E, 85 (2012), 066122. doi: 10.1103/PhysRevE.85.066122
|
| [41] |
E. Estrada, N. Hatano, Communicability angle and the spatial efficiency of networks, SIAM Rev., 58 (2016), 692-715. doi: 10.1137/141000555
|
| [42] |
E. Estrada, M. G. Sanchez-Lirola, J. A. de la Pena, Hyperspherical Embedding of Graphs and Networks in Communicability Spaces, Discr. Appl. Math., 176 (2014), 53-77. doi: 10.1016/j.dam.2013.05.032
|
| [43] |
M. Pereda, E. Estrada, Visualization and machine learning analysis of complex networks in hyperspherical space, Pattern Recog., 86 (2019), 320-331. doi: 10.1016/j.patcog.2018.09.018
|
| [44] |
A. K. Jain, Data clustering: 50 years beyond k-means, Patt. Recog. Lett., 31 (2010), 651-666. doi: 10.1016/j.patrec.2009.09.011
|
| [45] |
D. Steinley, K-means clustering: A half-century synthesis, Brit. J. Math. Stat. Psychol., 59 (2006), 1-34. doi: 10.1348/000711005X48266
|
| [46] |
M. Halkidi, Y. Batistakis, M. Vazirgiannis, On clustering validation techniques, J. Intel. Inform. Syst., 17 (2001), 107-145. doi: 10.1023/A:1012801612483
|
| [47] | Y. Liu, Z. Li, H. Xiong, X. Gao, J. Wu, Understanding of internal clustering validation measures. In: 2010 IEEE International Conference on Data Mining, IEEE, (2010), 911-916. |
| [48] |
T. Calinski, J. Harabasz, A dendrite method for cluster analysis, Commu. Stat. Theor. Meth., 3 (1974), 1-27. doi: 10.1080/03610927408827109
|
| [49] |
P. J. Rousseeuw, Silhouettes: A graphical aid to the interpretation and validation of cluster analysis, J. Comput. Appl. Math., 20 (1987), 53-65. doi: 10.1016/0377-0427(87)90125-7
|
| [50] | D. L. Davies, D. W. Bouldin, A cluster separation measure, IEEE Trans. Patt. Anal. Mach. Intel., 2 (1979), 224-227. |
| [51] |
D. Aloise, A. Deshpande, P. Hansen, P. Popat, NP-hardness of Euclidean sum-of-squares clustering, Mach. Learn., 75 (2009), 245-249. doi: 10.1007/s10994-009-5103-0
|
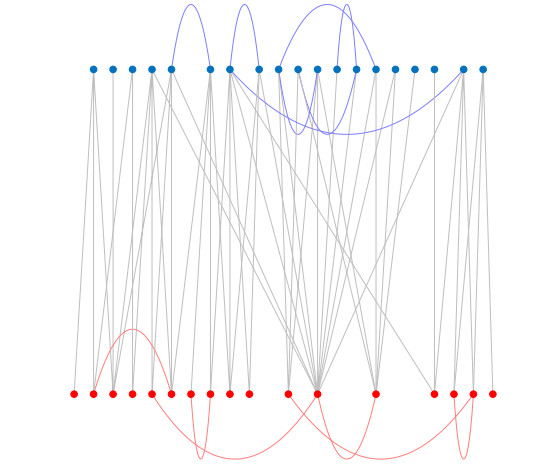
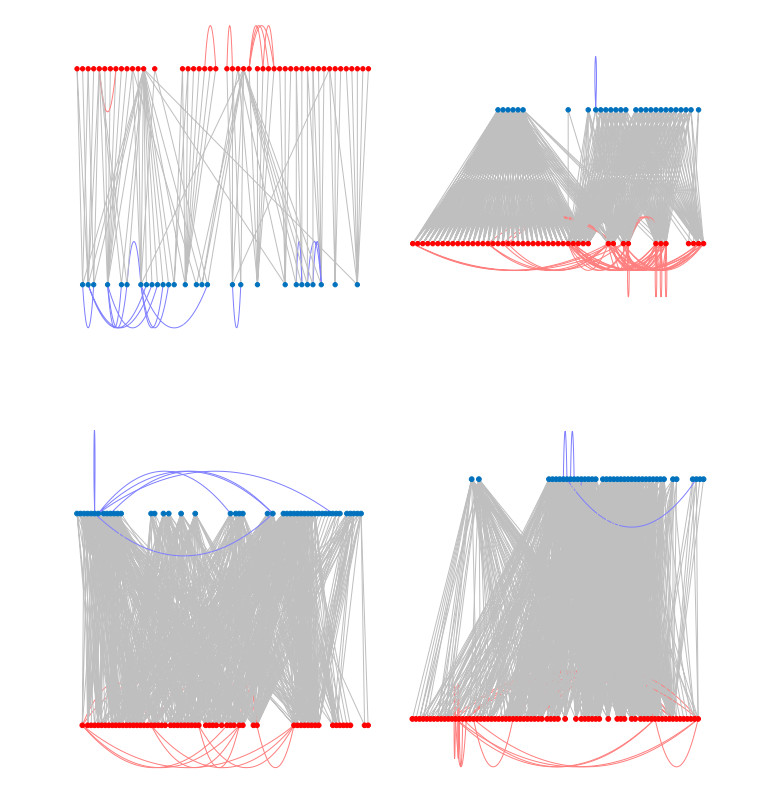
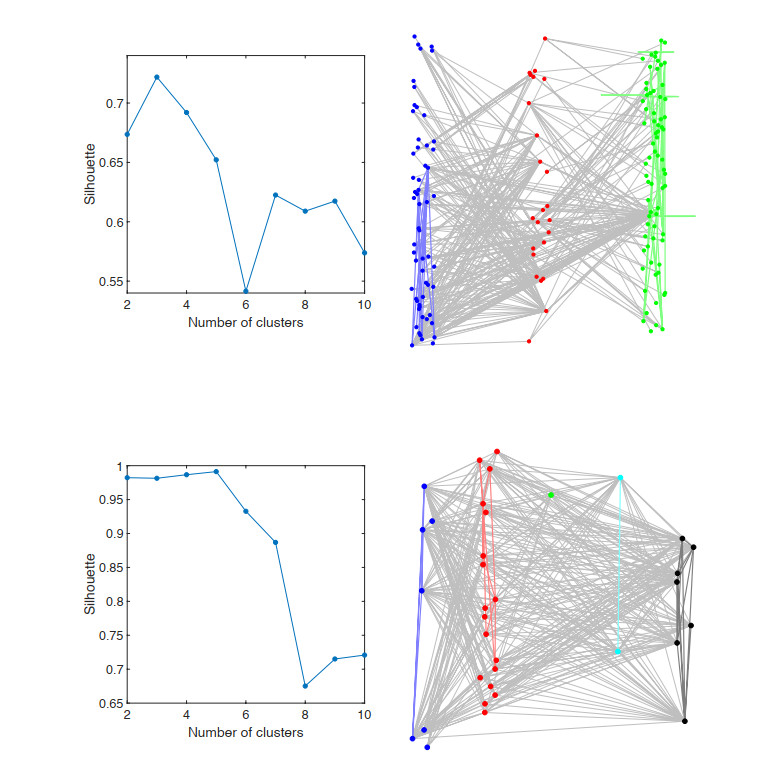
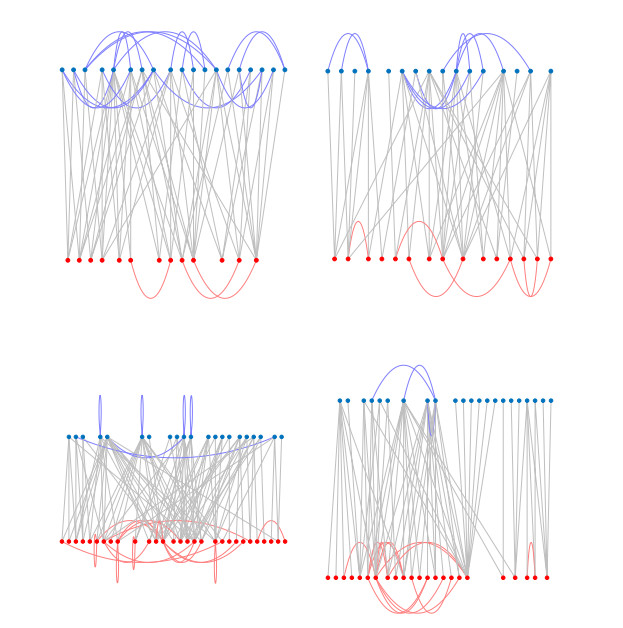
Figures(10) / Tables(1)

Jesús Gómez-Gardeñes, Ernesto Estrada. Network bipartitioning in the anti-communicability Euclidean space[J]. AIMS Mathematics, 2021, 6(2): 1153-1174. doi: 10.3934/math.2021070







 DownLoad:
DownLoad: