Citation: Yanmei Zhang, Mu Fan, Zhongmin Xiao. Nonlinear elastic-plastic stress investigations on two interacting 3-D cracks in offshore pipelines subjected to different loadings[J]. AIMS Materials Science, 2016, 3(4): 1321-1339. doi: 10.3934/matersci.2016.4.1321

| [1] | Cherry MC (1997) Residual strength of unstiffened aluminum panels with multiple site damage. Eng Fract Mech 57: 701–713. |
| [2] |
Haghpanah JB, Vaziri A (2012) Instability of cylindrical shells with single and multiple cracks under axial compression. Thin Wall Struct 54: 35–43. doi: 10.1016/j.tws.2012.01.014

|
| [3] |
Tu ST, Dai SH (1994) Engineering assessment of fatigue crack growth of irregularly oriented multiple cracks. Fatigue Fract Eng M 17: 1235–1246. doi: 10.1111/j.1460-2695.1994.tb01412.x
|
| [4] | Wang L, Brust FW, Atluri SN (1997) The Elastic-Plastic Finite Element Alternating Method (EPFEAM) and the prediction of fracture under WFD conditions in aircraft structures Part II: Fracture and the T*-Integral Parameter. Comput Mech 19: 370–379. |
| [5] | Wang L, Brust FW, Atluri SN (1997) The Elastic-Plastic Finite Element Alternating Method (EPFEAM) and the prediction of fracture under WFD conditions in aircraft structures Part I: EPFEAM Theory. Comput Mech 19: 356–369. |
| [6] |
Pyo CR, Okada H, Atluri SN (1995) Residual strength prediction for aircraft panels with Multiple Site Damage, using the "EPFEAM" for stable crack growth analysis. Comput Mech 16: 190–196. doi: 10.1007/BF00369780
|
| [7] |
Moukawsher EJ, Heinimann MB, Grandt Jr AF (1996) Residual strength of panels with multiple site damage. J Aircraft 33: 1014–1021. doi: 10.2514/3.47048
|
| [8] | Leis BN, Mohan R (1997) Coalescence conditions for stress-corrosion cracking based on interacting crack pairs. In Proceedings of the International Offshore and Polar Engineering Conference. |
| [9] |
Jiang ZD, Petit J, Bezine G (1991) Stress intensity factors of two parallel 3d surface cracks. Eng Fract Mech 40: 345–354. doi: 10.1016/0013-7944(91)90269-7
|
| [10] |
Moussa WA, Bell R, Tan CL (1999) The interaction of two parallel semi-elliptical surface cracks under tension and bending. J Press Vess-T ASME 121: 323–326. doi: 10.1115/1.2883710
|
| [11] |
Soboyejo WO, Knot JF, Walsh MJ, et al. (1990) Fatigue crack propagation of coplanar semi-elliptical cracks in pure bending. Eng Fract Mech 37: 323–340. doi: 10.1016/0013-7944(90)90044-H
|
| [12] | Kamaya M (2008) Growth evaluation of multiple interacting surface cracks. Part I: Experiments and simulation of coalesced crack. Eng Fract Mech 75: 1336–1349. |
| [13] | Kamaya M (2008) Growth evaluation of multiple interacting surface cracks. Part II: Growth evaluation of parallel cracks. Eng Fract Mech 75: 1350–1366. |
| [14] | Konosu S, Kasahara K (2012) Multiple fatigue crack growth prediction using stress intensity factor solutions modified by empirical interaction factors. J Press Vess-T ASME 134. |
| [15] |
Kotousov A, Chang D (2014) Local plastic collapse conditions for a plate weakened by two closely spaced collinear cracks. Eng Fract Mech 127: 1–11. doi: 10.1016/j.engfracmech.2014.05.009
|
| [16] |
Ouinas D, Bachir BB, Benderdouche N, et al. (2011) Numerical modelling of the interaction macro-multimicrocracks in a plate under tensile stress. J Comput Sci-Neth 2: 153–164. doi: 10.1016/j.jocs.2010.12.009
|
| [17] |
Moussa WA, Bell R, Tan CL (2002) Investigating the effect of crack shape on the interaction behavior of noncoplanar surface cracks using finite element analysis. J Press Vess-T ASME 124: 234–238. doi: 10.1115/1.1427690
|
| [18] | Konosu S (2009) Assessment procedure for multiple cracklike flaws in Failure Assessment Diagram (FAD). J Press Vess-T ASME 131. |
| [19] | Institution BS (2005) Guide to methods for assessing the acceptability of flaws in metallic structures. |
| [20] |
Allouti M, Jallouf S, Schmitt C, et al. (2011) Comparison between hot surface stress and effective stress acting at notch-like defect tip in a pressure vessel. Eng Fail Anal 18: 846–854. doi: 10.1016/j.engfailanal.2010.10.001
|
| [21] |
Allouti M, Schmitt C, Pluvinage G (2014) Assessment of a gouge and dent defect in a pipeline by a combined criterion. Eng Fail Anal 36: 1–13. doi: 10.1016/j.engfailanal.2013.10.002
|
| [22] | Pluvinage G, Capelle J, Schmitt C (2015) Methods for assessing defects leading to gas pipe failure, in Handbook of Materials Failure Analysis with Case Studies from the Oil and Gas Industry. |
| [23] |
Jayadevan KR, Østby E, Thaulow C (2004) Fracture response of pipelines subjected to large plastic deformation under tension. Int J Pres Ves Pip 81: 771–783. doi: 10.1016/j.ijpvp.2004.04.005
|
| [24] |
Nourpanah N, Taheri F (2010) Development of a reference strain approach for assessment of fracture response of reeled pipelines. Eng Fract Mech 77: 2337–2353. doi: 10.1016/j.engfracmech.2010.04.030
|
| [25] |
Nourpanah N, Taheri F (2011) A numerical study on the crack tip constraint of pipelines subject to extreme plastic bending. Eng Fract Mech 78: 1201–1217. doi: 10.1016/j.engfracmech.2010.11.021
|
| [26] | Østby E (2005) Fracture control—Offshore pipelines: New strain-based fracture mechanics equations including the effects of biaxial loading, mismatch and misalignment. In Proceedings of the International Conference on Offshore Mechanics and Arctic Engineering—OMAE. |
| [27] |
Adib H, Jallouf S, Schmitt C, et al. (2007) Evaluation of the effect of corrosion defects on the structural integrity of X52 gas pipelines using the SINTAP procedure and notch theory. Int J Pres Ves Pip 84: 123–131. doi: 10.1016/j.ijpvp.2006.10.005
|
| [28] |
Guidara MA, Bouaziz MA, Schmitt C, et al. (2015) Structural integrity assessment of defected high density poly-ethylene pipe: Burst test and finite element analysis based on J-integral criterion. Eng Fail Anal 57: 282–295. doi: 10.1016/j.engfailanal.2015.07.042
|
| [29] |
Zhang YM, Xiao ZM, Zhang WG, et al. (2014) Strain-based CTOD estimation formulations for fracture assessment of offshore pipelines subjected to large plastic deformation. Ocean Eng 91: 64–72. doi: 10.1016/j.oceaneng.2014.08.020
|
| [30] | DNV-OS-F101 (2013) Offshore Standard—submarine Pipeline Systems. Hovik, Norway: DET NORSKE VERITAS AS. |
| [31] |
Budden PJ (2006) Failure assessment diagram methods for strain-based fracture. Eng Fract Mech 73: 537–552. doi: 10.1016/j.engfracmech.2005.09.008
|
| [32] |
Yi D, Sridhar I, Xiao ZM, et al. (2012) Fracture capacity of girth welded pipelines with 3D surface cracks subjected to biaxial loading conditions. Int J Pres Ves Pip 92: 115–126. doi: 10.1016/j.ijpvp.2011.10.019
|
| [33] |
Yi D, Xiao ZM, Idapalapati S, et al. (2012) Fracture analysis of girth welded pipelines with 3D embedded cracks subjected to biaxial loading conditions. Eng Fract Mech 96: 570–587. doi: 10.1016/j.engfracmech.2012.09.005
|
| [34] | Kyriakides S, Corona E (2007) Mechanics of Offshore Pipelines: Buckling and Collapse, Elsevier Ltd. |
| [35] | Fyrileiv O, Collberg L (2005) Influence of pressure in pipeline design—Effective axial force. In Proceedings of the International Conference on Offshore Mechanics and Arctic Engineering—OMAE. |
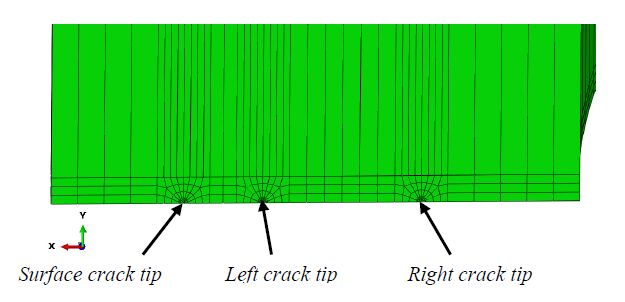
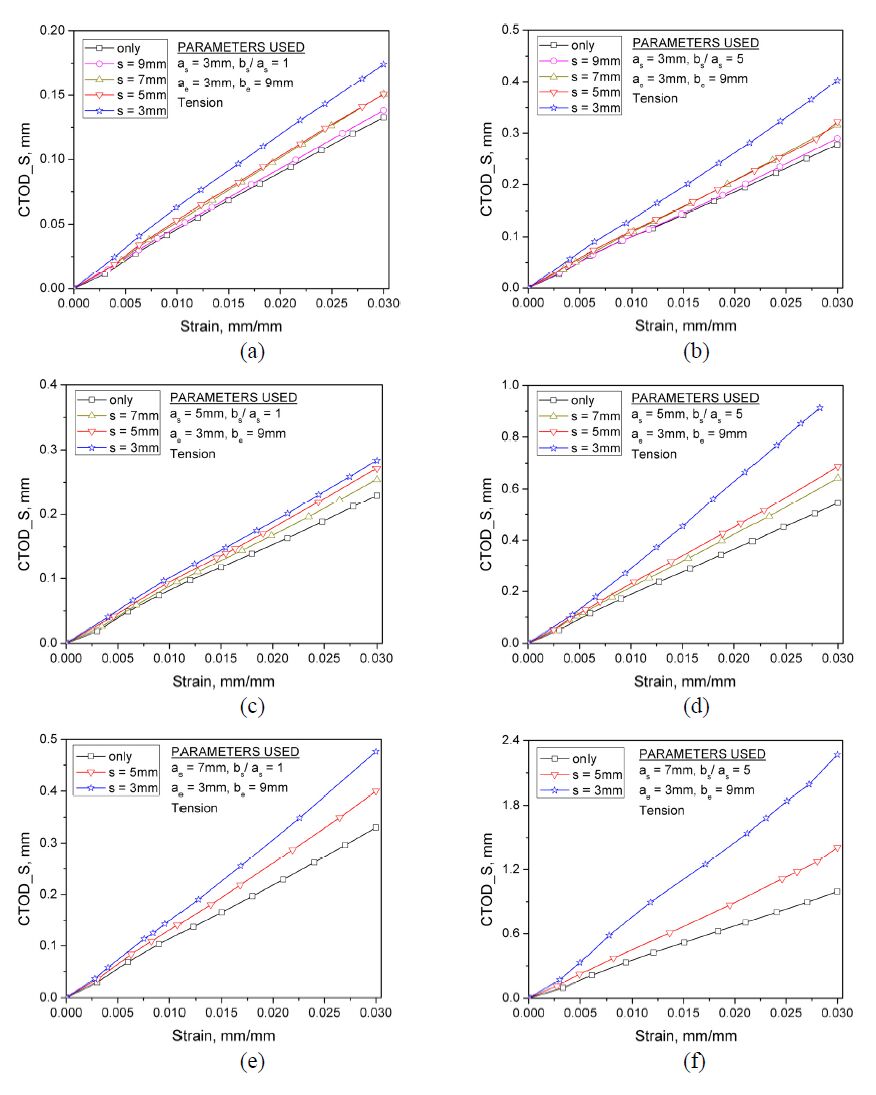
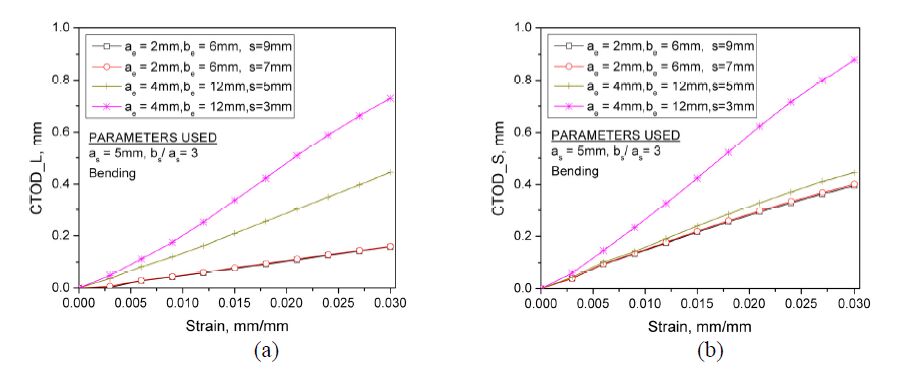
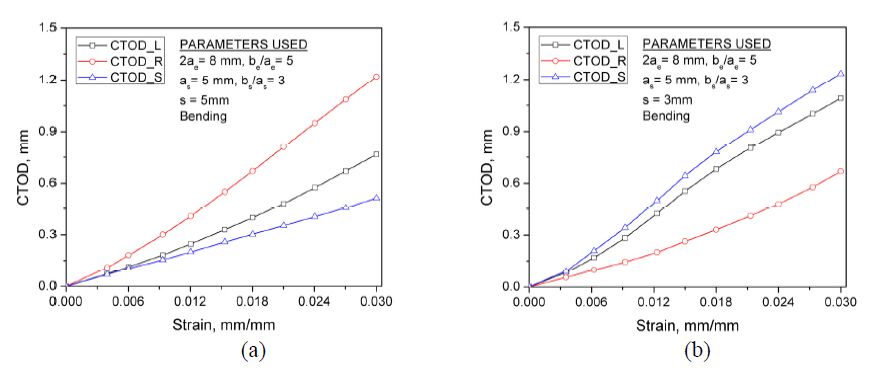
Figures(12) / Tables(3)

Yanmei Zhang, Mu Fan, Zhongmin Xiao. Nonlinear elastic-plastic stress investigations on two interacting 3-D cracks in offshore pipelines subjected to different loadings[J]. AIMS Materials Science, 2016, 3(4): 1321-1339. doi: 10.3934/matersci.2016.4.1321







 DownLoad:
DownLoad: