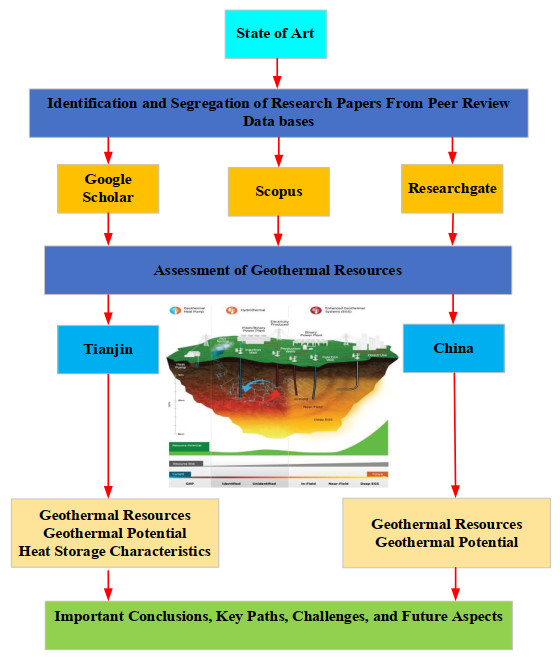
Tianjin, as one of the pioneering and most prominent cities in China, has a long history of harnessing geothermal energy. The geothermal resource available in Tianjin is primarily characterized as a low- to medium-temperature hydrothermal geothermal resource. This manuscript introduces the ongoing status and potential of geothermal utilization in China, with a particular focus on the characteristics and utilization status of geothermal resources in Tianjin, China. Moreover, the relevant strategies and challenges for cost-efficient sustainable utilization of Tianjin geothermal resources are identified. The formation parameters of heat storage characteristics of Tianjin geothermal resources are also discussed. In addition, the key paths, guidelines and challenges on how to solve the obstacles related to the geothermal resources development in Tianjin are also suggested. The summarized results indicate that the geothermal reservoirs exploited in Tianjin vary greatly, which include sandstone of Neogene Minghuazhen formation, Guantao formation, Ordovician and Cambrian and carbonate of Proterozoic Wumishan formation. Most of the exploitative geothermal resources (146 geothermal wells) in Tianjin have mainly been produced from the Wumishan formation of the Jixian system and the Guantao formation of the Neogene system. The current production capacity has been doubled, and a two-stage cascade utilization system has been established, incorporating geothermal power generation and geothermal heating. The geothermal utilization share in Tianjin is estimated to be 81.66% for heating, 16.6% for domestic hot water and 1.35% for bathing. In conclusion, notwithstanding the diversity of geothermal resources in Tianjin, it is difficult to guarantee the sustainable development and utilization of geothermal resources in Tianjin due to the unreasonable layout of geothermal wells, imbalance of production and reinjection. Hence, the integration of distributed temperature sensing and distributed strain sensing monitoring demonstrates significant promise and effectiveness in tracking water circulation and detecting flow localization problems as dynamic monitoring processes and smart thermal response tests should be recommended and established as a substantial feature required in the future utilization and development of geothermal resources in Tianjin.
Citation: Hongmei Yin, Mohamed E Zayed, Ahmed S Menesy, Jun Zhao, Kashif Irshad, Shafiqur Rehman. Present status and sustainable utilization of hydrothermal geothermal resources in Tianjin, China: a critical review[J]. AIMS Geosciences, 2023, 9(4): 734-753. doi: 10.3934/geosci.2023039
Tianjin, as one of the pioneering and most prominent cities in China, has a long history of harnessing geothermal energy. The geothermal resource available in Tianjin is primarily characterized as a low- to medium-temperature hydrothermal geothermal resource. This manuscript introduces the ongoing status and potential of geothermal utilization in China, with a particular focus on the characteristics and utilization status of geothermal resources in Tianjin, China. Moreover, the relevant strategies and challenges for cost-efficient sustainable utilization of Tianjin geothermal resources are identified. The formation parameters of heat storage characteristics of Tianjin geothermal resources are also discussed. In addition, the key paths, guidelines and challenges on how to solve the obstacles related to the geothermal resources development in Tianjin are also suggested. The summarized results indicate that the geothermal reservoirs exploited in Tianjin vary greatly, which include sandstone of Neogene Minghuazhen formation, Guantao formation, Ordovician and Cambrian and carbonate of Proterozoic Wumishan formation. Most of the exploitative geothermal resources (146 geothermal wells) in Tianjin have mainly been produced from the Wumishan formation of the Jixian system and the Guantao formation of the Neogene system. The current production capacity has been doubled, and a two-stage cascade utilization system has been established, incorporating geothermal power generation and geothermal heating. The geothermal utilization share in Tianjin is estimated to be 81.66% for heating, 16.6% for domestic hot water and 1.35% for bathing. In conclusion, notwithstanding the diversity of geothermal resources in Tianjin, it is difficult to guarantee the sustainable development and utilization of geothermal resources in Tianjin due to the unreasonable layout of geothermal wells, imbalance of production and reinjection. Hence, the integration of distributed temperature sensing and distributed strain sensing monitoring demonstrates significant promise and effectiveness in tracking water circulation and detecting flow localization problems as dynamic monitoring processes and smart thermal response tests should be recommended and established as a substantial feature required in the future utilization and development of geothermal resources in Tianjin.

| [1] |
El-Hadary MI, Senthilraja S, Zayed ME (2023) A hybrid system coupling spiral type solar photovoltaic thermal collector and electrocatalytic hydrogen production cell: Experimental investigation and numerical modeling. Process Saf Environ Prot 170: 1101–1120. https://doi.org/10.1016/j.psep.2022.12.079 doi: 10.1016/j.psep.2022.12.079

|
| [2] |
Zayed ME, Zhao J, Li W, et al. (2020) Recent progress in phase change materials storage containers: Geometries, design considerations and heat transfer improvement methods. J Energy Storage 30: 101341. https://doi.org/10.1016/j.est.2020.101341 doi: 10.1016/j.est.2020.101341
|
| [3] |
Zayed ME, Zhao J, Elsheikh AH, et al. (2021) A comprehensive review on Dish/Stirling concentrated solar power systems: Design, optical and geometrical analyses, thermal performance assessment, and applications. J Clean Prod 283: 124664. https://doi.org/10.1016/j.jclepro.2020.124664 doi: 10.1016/j.jclepro.2020.124664
|
| [4] |
Zhao J, Ma L, Zayed ME, et al. (2021) Industrial reheating furnaces: A review of energy efficiency assessments, waste heat recovery potentials, heating process characteristics and perspectives for steel industry. Process Saf Environ Prot 147: 1209–1228. https://doi.org/10.1016/j.psep.2021.01.045 doi: 10.1016/j.psep.2021.01.045
|
| [5] |
Zayed ME, Zhao J, Elsheikh AH, et al. (2020) Optimal design parameters and performance optimization of thermodynamically balanced dish/Stirling concentrated solar power system using multi-objective particle swarm optimization. Appl Therm Eng 178: 115539. https://doi.org/10.1016/j.applthermaleng.2020.115539 doi: 10.1016/j.applthermaleng.2020.115539
|
| [6] |
Aboelmaaref MM, Zayed ME, Zhao J, et al. (2020) Hybrid solar desalination systems driven by parabolic trough and parabolic dish CSP technologies: Technology categorization, thermodynamic performance and economical assessment. Energy Convers Manag 220: 113103. https://doi.org/10.1016/j.enconman.2020.113103 doi: 10.1016/j.enconman.2020.113103
|
| [7] |
Ma L, Li Y, Wang JY, et al. (2019) A thermal-dissipation correction method for in-situ soil thermal response test: Experiment and simulation under multi-operation conditions. Energy Build 194: 218–231. https://doi.org/10.1016/j.enbuild.2019.04.014 doi: 10.1016/j.enbuild.2019.04.014
|
| [8] |
Al-Kbodi BH, Rajeh T, Li Y, et al. (2023) Heat extraction analyses and energy consumption characteristics of novel designs of geothermal borehole heat exchangers with elliptic and oval double U-tube structures. Appl Therm Eng 235: 121418. https://doi.org/10.1016/j.applthermaleng.2023.121418 doi: 10.1016/j.applthermaleng.2023.121418
|
| [9] |
Nian YL, Cheng WL (2018) Insights into geothermal utilization of abandoned oil and gas wells. Renewable Sustainable Energy Rev 87: 44–60. https://doi.org/10.1016/j.rser.2018.02.004 doi: 10.1016/j.rser.2018.02.004
|
| [10] |
Kamazani M, Aghanajafi C (2022) Numerical simulation of geothermal-PVT hybrid system with PCM storage tank. Int J Energy Res 46: 397–414. https://doi.org/10.1002/er.7279 doi: 10.1002/er.7279
|
| [11] |
Ma L, Zhao Y, Yin HM, et al. (2019) A coupled heat transfer model of medium-depth downhole coaxial heat exchanger based on the piecewise analytical solution. Energy Convers Manage 204: 112308. https://doi.org/10.1016/j.enconman.2019.112308 doi: 10.1016/j.enconman.2019.112308
|
| [12] |
Gilbert GL, Instanes A, Sinitsyn AO, et al. (2019) Characterization of two sites for geotechnical testing in permafrost: Longyearbyen, Svalbard. AIMS Geosci 5: 868–885. https://doi.org/10.3934/geosci.2019.4.868 doi: 10.3934/geosci.2019.4.868
|
| [13] |
Marmelia PD, Andri DS, Yusuf L (2022) Investment decisions under uncertainties in geothermal power generation. AIMS Energy 4: 844–857. https://doi.org/10.3934/energy.2022038 doi: 10.3934/energy.2022038
|
| [14] |
Kelly JJ, McDermott CI (2022) Numerical modelling of a deep closed-loop geothermal system: evaluating the Eavor-Loop. AIMS Geosci 8: 175–212. https://doi.org/10.3934/geosci.2022011 doi: 10.3934/geosci.2022011
|
| [15] |
Zayed ME, Shboul B, Yin H, et al. (2022) Recent advances in geothermal energy reservoirs modeling: Challenges and potential of thermo-fluid integrated models for reservoir heat extraction and geothermal energy piles design. J Energy Storage 62: 106835. https://doi.org/10.1016/j.est.2023.106835 doi: 10.1016/j.est.2023.106835
|
| [16] |
Su Y, Yang F, Wang B, et al. (2018) Reinjection of cooled water into sandstone geothermal reservoirs in China: a review. Geosci J 22: 199–207. https://doi.org/10.1007/s12303-017-0019-3 doi: 10.1007/s12303-017-0019-3
|
| [17] |
Song W, Liu X, Zheng T, et al. (2020) A review of recharge and clogging in sandstone aquifer. Geothermics 87: 101857. https://doi.org/10.1016/j.geothermics.2020.101857 doi: 10.1016/j.geothermics.2020.101857
|
| [18] |
Dijkshoorn L, Speer S, Pechnig R (2013) Measurements and design calculations for a deep coaxial borehole heat exchanger in Aachen, Germany. Int J Geophys 2013: 916541. https://doi.org/10.1155/2013/916541 doi: 10.1155/2013/916541
|
| [19] |
Wu BS, Zhang X, Jeffrey RG, et al. (2016) A simplified model for heat extraction by circulating fluid through a closed-loop multiple-fracture enhanced geothermal system. Appl Energy 183: 1664–1681. https://doi.org/10.1016/j.apenergy.2016.09.113 doi: 10.1016/j.apenergy.2016.09.113
|
| [20] |
Willems CJL, Nick HM, Weltje GJ, et al. (2017) An evaluation of interferences in heat production from low enthalpy geothermal doublets systems. Energy 135: 500–512. https://doi.org/10.1016/j.energy.2017.06.129 doi: 10.1016/j.energy.2017.06.129
|
| [21] |
Lund JW, Boyd TL (2016) Direct utilization of geothermal energy worldwide: review. Geothermics 60: 66–93. https://doi.org/10.1016/j.geothermics.2015.11.004 doi: 10.1016/j.geothermics.2015.11.004
|
| [22] |
Babaei M, Nick HM (2019) Performance of low-enthalpy geothermal systems: interplay of spatially correlated heterogeneity and well-doublet spacings. Appl Energy 253: 113569. https://doi.org/10.1016/j.apenergy.2019.113569 doi: 10.1016/j.apenergy.2019.113569
|
| [23] |
Holmberg H, Acuña J, Næss E, et al. (2016) Thermal evaluation of coaxial deep borehole heat exchangers. Renew Energy 97: 65–76. https://doi.org/10.1016/j.renene.2016.05.048 doi: 10.1016/j.renene.2016.05.048
|
| [24] |
Liu H, Hou Z, Li X, et al. (2015) A preliminary site selection system for a CO2-AGES project and its application in China. Environ Earth Sci 73: 6855–6870. https://doi.org/10.1007/s12665-015-4249-2 doi: 10.1007/s12665-015-4249-2
|
| [25] |
Zhu JL, Hu K, Lu X, et al. (2015) A review of geothermal energy resources, development, and applications in China: Current status and prospects. Energy 93: 466–483. https://doi.org/10.1016/j.energy.2015.08.098 doi: 10.1016/j.energy.2015.08.098
|
| [26] |
An QS, Wang YZ, Zhao J, et al. (2016) Direct utilization status and power generation potential of low-medium temperature hydrothermal geothermal resources in Tianjin, China: A review. Geothermics 64: 426–438. https://doi.org/10.1016/j.geothermics.2016.06.005 doi: 10.1016/j.geothermics.2016.06.005
|
| [27] |
Wang YZ, Li CJ, Zhao J, et al. (2021) The above-ground strategies to approach the goal of geothermal power generation in China: State of art and future researches. Renewable Sustainable Energy Rev 138: 110557. https://doi.org/10.1016/j.rser.2020.110557 doi: 10.1016/j.rser.2020.110557
|
| [28] |
Zhang L, Chen S, Zhang C (2019) Geothermal power generation in China: Status and prospects. Energy Sci Eng 7: 1428–1450. https://doi.org/10.1002/ese3.365 doi: 10.1002/ese3.365
|
| [29] |
Xu YS, Wang XW, Shen SL, et al. (2020) Distribution characteristics and utilization of shallow geothermal energy in China. Energy Build 229: 110479. https://doi.org/10.1016/j.enbuild.2020.110479 doi: 10.1016/j.enbuild.2020.110479
|
| [30] |
He Z, Feng J, Luo J, et al. (2023) Distribution, exploitation, and utilization of intermediate-to-deep geothermal resources in eastern China. Energy Geosci 4: 100187. https://doi.org/10.1016/j.engeos.2023.100187 doi: 10.1016/j.engeos.2023.100187
|
| [31] |
Luo J, Zhang Q, Liang C, et al. (2023) An overview of the recent development of the Ground Source Heat Pump (GSHP) system in China, Renew. Energy 210: 269–279. https://doi.org/https://doi.org/10.1016/j.renene.2023.04.034 doi: 10.1016/j.renene.2023.04.034
|
| [32] | Duan YH, Wang JB, Wang YB, et al. (2004) Groundwater resources and its sustainable development in Tianjin. Hydrol Eng Geol 31: 29–39. |
| [33] |
Zhang WK, Wang KX, Guan CM, et al. (2023) Analysis and optimization of the performance for the ground source heat pump system with the middle-deep U-type well. Appl Therm Eng 219: 119404. https://doi.org/10.1016/j.applthermaleng.2022.119404 doi: 10.1016/j.applthermaleng.2022.119404
|
| [34] | Tian P (2015) Evaluation on the Potential of Geothermal Resource in Tianjin. China University of Geosciences, Thesis. |
| [35] | Yu Y (2014) Evaluation of geothermal resources in the Neogene geothermal reservoir in the New Coastal Area of Tianjin. China University of Geosciences, Thesis. |
| [36] |
Lei HY, Zhu JL (2013) Numerical modeling of exploitation and reinjection of the Guantao geothermal reservoir in Tanggu District, Tianjin, China. Geothermics 48: 60–68. https://doi.org/10.1016/j.geothermics.2013.03.008 doi: 10.1016/j.geothermics.2013.03.008
|
| [37] |
Rajeh T, Al-Kbodi BH, Li Y, et al. (2023) Modeling and techno-economic comparison of two types of coaxial with double U-tube ground heat exchangers. Appl Therm Eng 225: 120221. https://doi.org/10.1016/j.applthermaleng.2023.120221 doi: 10.1016/j.applthermaleng.2023.120221
|
| [38] | Qian H (2014) Study of the feasibility of geothermal well drilling technology in the Cambrian in the Dongli District of Tianjin. China University of Geosciences. A thesis. |
| [39] |
Parisio F, Yoshioka K (2020) Modeling fluid reinjection into an enhanced geothermal system. Geophys Res Lett 47. https://doi.org/10.1029/2020GL089886 doi: 10.1029/2020GL089886
|
| [40] |
Ke TT, Huang SP, Xu W, et al. (2022) Evaluation of the multi-doublet performance in sandstone reservoirs using thermal-hydraulic modeling and economic analysis. Geothermics 98: 102273. https://doi.org/10.1016/j.geothermics.2021.102273 doi: 10.1016/j.geothermics.2021.102273
|
| [41] |
Rajeh T, Al-Kbodi BH, Li Y, et al. (2023) A novel oval-shaped coaxial ground heat exchanger for augmenting the performance of ground-coupled heat pumps: Transient heat transfer performance and multi-parameter optimization. J Build Eng 79: 107781. https://doi.org/10.1016/j.jobe.2023.107781 doi: 10.1016/j.jobe.2023.107781
|
| [42] |
Wang GL, Wang WL, Zhang W, et al. (2020) The status quo and prospect of geothermal resources exploration and development in Beijing-Tianj in-Hebei region in China. China Geol 3: 173–181. https://doi.org/10.31035/cg2020013 doi: 10.31035/cg2020013
|
| [43] |
Wang Y, Liu Y, Dou J, et al. (2020) Geothermal energy in China: Status, challenges, and policy recommendations. Utilities Policy 64: 101020. https://doi.org/10.1016/j.jup.2020.101020 doi: 10.1016/j.jup.2020.101020
|
| [44] | Wang L, Bi Y, Yao J, et al. (2022) Comprehensive Utilization of Resources, Interpretation of Green Mine Evaluation Index, Springer, Singapore. https://doi.org/10.1007/978-981-16-5433-6_6 |
| [45] | Jian Z, Gui F, Yubei H (2023) The deep high temperature characteristics and geodynamic background of geothermal anomaly areas in Eastern China. Earth Sci Front 30: 316–332. |
| [46] |
Bing MR, Jia LX, Yang Y, et al. (2021) The development and utilization of geothermal energy in the world. Chin Geol 48: 1734–1747. https://doi.org/10.12029/gc20210606 doi: 10.12029/gc20210606
|










Figures(11) / Tables(3)

Hongmei Yin, Mohamed E Zayed, Ahmed S Menesy, Jun Zhao, Kashif Irshad, Shafiqur Rehman. Present status and sustainable utilization of hydrothermal geothermal resources in Tianjin, China: a critical review[J]. AIMS Geosciences, 2023, 9(4): 734-753. doi: 10.3934/geosci.2023039







 DownLoad:
DownLoad: