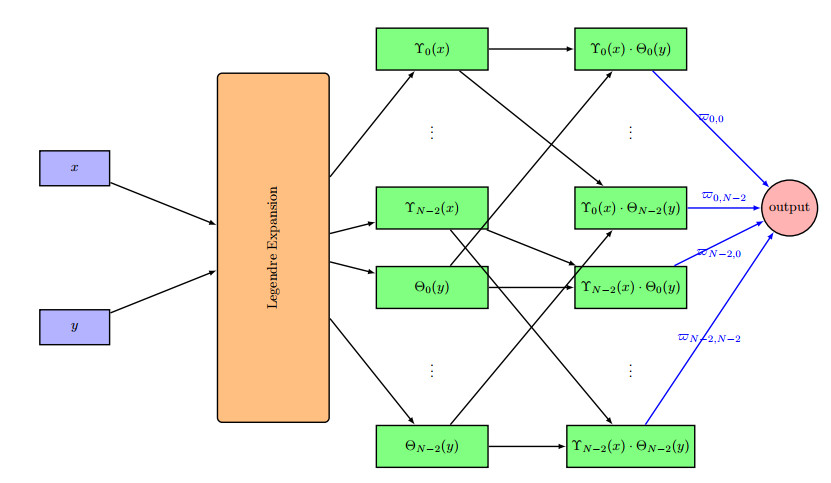
In this work, a novel approach based on a single-layer machine learning Legendre spectral neural network (LSNN) method is used to solve an elliptic partial differential equation. A Legendre polynomial based approach is utilized to generate neurons that fulfill the boundary conditions. The loss function is computed by using the error back-propagation principles and a feed-forward neural network model combined with automatic differentiation. The main advantage of using this methodology is that it does not need to solve a system of nonlinear and nonsparse equations compared with other traditional numerical schemes, which makes this algorithm more convenient for solving higher-dimensional equations. Further, the hidden layer is eliminated with the help of a Legendre polynomial to enlarge the input pattern. The neural network's training accuracy and efficiency were significantly enhanced by the innovative sampling technique and neuron architecture. Moreover, the Legendre spectral approach can handle equations on more complex domains because of numerous networks. Several test problems were used to validate the proposed scheme, and a comparison was made with other neural network schemes consisting of the physics-informed neural network (PINN) scheme. We found that our proposed scheme has a very good agreement with PINN, which further enhances the reliability and efficiency of our proposed method. The absolute and relative error in both $ L_2 $ and $ L_{\infty} $ between exact and numerical solutions are provided, which shows that our numerical method converges exponentially.
Citation: Ishtiaq Ali. Advanced machine learning technique for solving elliptic partial differential equations using Legendre spectral neural networks[J]. Electronic Research Archive, 2025, 33(2): 826-848. doi: 10.3934/era.2025037
In this work, a novel approach based on a single-layer machine learning Legendre spectral neural network (LSNN) method is used to solve an elliptic partial differential equation. A Legendre polynomial based approach is utilized to generate neurons that fulfill the boundary conditions. The loss function is computed by using the error back-propagation principles and a feed-forward neural network model combined with automatic differentiation. The main advantage of using this methodology is that it does not need to solve a system of nonlinear and nonsparse equations compared with other traditional numerical schemes, which makes this algorithm more convenient for solving higher-dimensional equations. Further, the hidden layer is eliminated with the help of a Legendre polynomial to enlarge the input pattern. The neural network's training accuracy and efficiency were significantly enhanced by the innovative sampling technique and neuron architecture. Moreover, the Legendre spectral approach can handle equations on more complex domains because of numerous networks. Several test problems were used to validate the proposed scheme, and a comparison was made with other neural network schemes consisting of the physics-informed neural network (PINN) scheme. We found that our proposed scheme has a very good agreement with PINN, which further enhances the reliability and efficiency of our proposed method. The absolute and relative error in both $ L_2 $ and $ L_{\infty} $ between exact and numerical solutions are provided, which shows that our numerical method converges exponentially.

| [1] | Y. Pinchover, J. Rubinstein, An Introduction to Partial Differential Equations, Cambridge University Press, 2005. https://doi.org/10.1017/CBO9780511801228 |
| [2] |
J. Douglas, B. F. Jones, On predictor-corrector methods for nonlinear parabolic differential equations, J. Soc. Ind. Appl. Math., 11 (1963), 195–204. https://doi.org/10.1137/0111015 doi: 10.1137/0111015

|
| [3] |
A. Wambecq, Rational Runge-Kutta methods for solving systems of ordinary differential equations, Computing, 20 (1978), 333–342. https://doi.org/10.1007/BF02252381 doi: 10.1007/BF02252381
|
| [4] | J. N. Reddy, An Introduction to the Finite Element Method, McGraw-Hill, 1993. |
| [5] | R. J. LeVeque, Finite Difference Methods for Ordinary and Partial Differential Equations: Steady-state and Time-dependent Problems, SIAM, 2007. https://doi.org/10.1137/1.9780898717839 |
| [6] |
I. E. Lagaris, A. Likas, D. I. Fotiadis, Artificial neural networks for solving ordinary and partial differential equations, IEEE Trans. Neural Networks, 9 (1998), 987–1000. https://doi.org/10.1109/72.712178 doi: 10.1109/72.712178
|
| [7] |
S. Mall, S. Chakraverty, Application of Legendre neural network for solving ordinary differential equations, Appl. Soft Comput., 43 (2016), 347–356. https://doi.org/10.1016/j.asoc.2015.10.069 doi: 10.1016/j.asoc.2015.10.069
|
| [8] |
T. T. Dufera, Deep neural network for system of ordinary differential equations: Vectorized algorithm and simulation, Mach. Learn. Appl., 5 (2021), 100058. https://doi.org/10.1016/j.mlwa.2021.100058 doi: 10.1016/j.mlwa.2021.100058
|
| [9] |
J. A. Rivera, J. M. Taylor, A. J. Omella, D. Pardo, On quadrature rules for solving partial differential equations using neural networks, Comput. Methods Appl. Mech. Eng., 393 (2022), 114710. https://doi.org/10.1016/j.cma.2022.114710 doi: 10.1016/j.cma.2022.114710
|
| [10] |
L. S. Tan, Z. Zainuddin, P. Ong, Wavelet neural networks based solutions for elliptic partial differential equations with improved butterfly optimization algorithm training, Appl. Soft Comput., 95 (2020), 106518. https://doi.org/10.1016/j.asoc.2020.106518 doi: 10.1016/j.asoc.2020.106518
|
| [11] |
Z. Sabir, S. A. Bhat, M. A. Z. Raja, S. E. Alhazmi, A swarming neural network computing approach to solve the Zika virus model, Eng. Appl. Artif. Intell., 126 (2023), 106924. https://doi.org/10.1016/j.engappai.2023.106924 doi: 10.1016/j.engappai.2023.106924
|
| [12] |
M. Raissi, P. Perdikaris, G. E. Karniadakis, Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations, J. Comput. Phys., 378 (2019), 686–707. https://doi.org/10.1016/j.jcp.2018.10.045 doi: 10.1016/j.jcp.2018.10.045
|
| [13] |
E. Schiassi, R. Furfaro, C. Leake, M. De Florio, H. Johnston, D. Mortari, Extreme theory of functional connections: A fast physics-informed neural network method for solving ordinary and partial differential equations, Neurocomputing, 457 (2021), 334–356. https://doi.org/10.1016/j.neucom.2021.06.015 doi: 10.1016/j.neucom.2021.06.015
|
| [14] |
S. Dong, Z. Li, Local extreme learning machines and domain decomposition for solving linear and nonlinear partial differential equations, Comput. Methods Appl. Mech. Eng., 387 (2021), 114129. https://doi.org/10.1016/j.cma.2021.114129 doi: 10.1016/j.cma.2021.114129
|
| [15] |
S. Dong, J. Yang, On computing the hyperparameter of extreme learning machines: Algorithm and application to computational PDEs, and comparison with classical and high-order finite elements, J. Comput. Phys., 463 (2022), 111290. https://doi.org/10.1016/j.jcp.2022.111290 doi: 10.1016/j.jcp.2022.111290
|
| [16] |
G. B. Huang, Q. Y. Zhu, C. K. Siew, Extreme learning machine: Theory and applications, Neurocomputing, 70 (2006), 489–501. https://doi.org/10.1016/j.neucom.2005.12.126 doi: 10.1016/j.neucom.2005.12.126
|
| [17] |
V. Dwivedi, B. Srinivasan, Physics-informed extreme learning machine (PIELM) – A rapid method for the numerical solution of partial differential equations, Neurocomputing, 391 (2020), 96–118. https://doi.org/10.1016/j.neucom.2019.12.099 doi: 10.1016/j.neucom.2019.12.099
|
| [18] |
F. Calabrò, G. Fabiani, C. Siettos, Extreme learning machine collocation for the numerical solution of elliptic PDEs with sharp gradients, Comput. Methods Appl. Mech. Eng., 387 (2021), 114188. https://doi.org/10.1016/j.cma.2021.114188 doi: 10.1016/j.cma.2021.114188
|
| [19] |
S. M. Sivalingam, P. Kumar, V. Govindaraj, A Chebyshev neural network-based numerical scheme to solve distributed-order fractional differential equations, Comput. Math. Appl., 164 (2024), 150–165. https://doi.org/10.1016/j.camwa.2024.04.005 doi: 10.1016/j.camwa.2024.04.005
|
| [20] |
A. Jafarian, M. Mokhtarpour, D. Baleanu, Artificial neural network approach for a class of fractional ordinary differential equations, Neural Comput. Appl., 28 (2017), 765–773. https://doi.org/10.1007/s00521-015-2104-8 doi: 10.1007/s00521-015-2104-8
|
| [21] |
I. Ali, S. U. Khan, A dynamic competition analysis of stochastic fractional differential equation arising in finance via the pseudospectral method, Mathematics, 11 (2023), 1328. https://doi.org/10.3390/math11061328 doi: 10.3390/math11061328
|
| [22] |
S. U. Khan, M. Ali, I. Ali, A spectral collocation method for stochastic Volterra integro-differential equations and its error analysis, Adv. Differ. Equ., 2019 (2019), 161. https://doi.org/10.1186/s13662-019-2096-2 doi: 10.1186/s13662-019-2096-2
|
| [23] |
I. Ali, S. U. Khan, Dynamics and simulations of stochastic COVID-19 epidemic model using Legendre spectral collocation method, AIMS Math., 8 (2023), 4220–4236. https://doi.org/10.3934/math.2023210 doi: 10.3934/math.2023210
|
| [24] |
S. U. Khan, I. Ali, Application of Legendre spectral-collocation method to delay differential and stochastic delay differential equations, AIP Adv., 8 (2018), 035301. https://doi.org/10.1063/1.5016680 doi: 10.1063/1.5016680
|
| [25] | C. Canuto, M. Y. Hussaini, A. Quarteroni, T. A. Zang, Spectral Methods: Fundamentals in Single Domains, Springer, 2006. https://doi.org/10.1007/978-3-540-30726-6 |
| [26] |
G. Mastroianni, D. Occorsio, Optimal systems of nodes for Lagrange interpolation on bounded intervals: A survey, J. Comput. Appl. Math., 134 (2001), 325–341. https://doi.org/10.1016/S0377-0427(00)00557-4 doi: 10.1016/S0377-0427(00)00557-4
|
| [27] | D. Gottlieb, S. A. Orszag, Numerical Analysis of Spectral Methods: Theory and Applications, SIAM, 1977. https://doi.org/10.1137/1.9781611970425 |
| [28] | J. P. Boyd, Chebyshev and Fourier Spectral Methods, Dover Publications, 2001. |
| [29] | J. S. Hesthaven, S. Gottlieb, D. Gottlieb, Spectral Methods for Time-dependent Problems, Cambridge University Press, 2007. https://doi.org/10.1017/CBO9780511618352 |
| [30] | C. Canuto, M. Y. Hussaini, A. Quarteroni, T. A. Zang, Spectral Methods in Fluid Dynamics, Springer, 2012. https://doi.org/10.1007/978-3-642-84108-8 |
| [31] | J. Shen, T. Tang, L. L. Wang, Spectral Methods: Algorithms, Analysis and Aapplications, Springer, 2011. https://doi.org/10.1007/978-3-540-71041-7 |
| [32] | N. Liu, Theory and Applications and Legendre Polynomials and Wavelets, Ph.D thesis, The University of Toledo, 2008. |
| [33] |
S. Wang, X. Yu, P. Perdikaris, When and why PINNs fail to train: A neural tangent kernel perspective, J. Comput. Phys., 449 (2022), 110768. https://doi.org/10.1016/j.jcp.2021.110768 doi: 10.1016/j.jcp.2021.110768
|
| [34] | P. Yin, S. Ling, W. Ying, Chebyshev spectral neural networks for solving partial differential equations, preprint, arXiv: 2407.03347. |
| [35] |
Y. Yang, M. Hou, H. Sun, T. Zhang, F. Weng, J. Luo, Neural network algorithm based on Legendre improved extreme learning machine for solving elliptic partial differential equations, Soft Comput., 24 (2020), 1083–1096. https://doi.org/10.1007/s00500-019-03944-1 doi: 10.1007/s00500-019-03944-1
|
| [36] |
M. Xia, X. Li, Q. Shen, T. Chou, Learning unbounded-domain spatiotemporal differential equations using adaptive spectral methods, J. Appl. Math. Comput., 70, (2024), 4395–4421. https://doi.org/10.1007/s12190-024-02131-2 doi: 10.1007/s12190-024-02131-2
|
| [37] |
Y. Ye, Y. Li, H. Fan, X. Liu, H. Zhang, SLeNN-ELM: A shifted Legendre neural network method for fractional delay differential equations based on extreme learning machine, Netw. Heterog. Media, 18 (2023), 494–512. https://doi.org/10.3934/nhm.2023020 doi: 10.3934/nhm.2023020
|
| [38] |
Y. Yang, M. Hou, J. Luo, A novel improved extreme learning machine algorithm in solving ordinary differential equations by Legendre neural network methods, Adv. Differ. Equ., 2018 (2018), 469. https://doi.org/10.1186/s13662-018-1927-x doi: 10.1186/s13662-018-1927-x
|
| [39] |
Y. Wang, S. Dong, An extreme learning machine-based method for computational PDEs in higher dimensions, Comput. Methods Appl. Mech. Eng., 418 (2024), 116578. https://doi.org/10.1016/j.cma.2023.116578 doi: 10.1016/j.cma.2023.116578
|
| [40] |
D. Yuan, W. Liu, Y. Ge, G. Cui, L. Shi, F. Cao, Artificial neural networks for solving elliptic differential equations with boundary layer, Math. Methods Appl. Sci., 45 (2022), 6583–6598. https://doi.org/10.1002/mma.8192 doi: 10.1002/mma.8192
|
| [41] |
H. Liu, B. Xing, Z. Wang, L. Li, Legendre neural network method for several classes of singularly perturbed differential equations based on mapping and piecewise optimization technology, Neural Process. Lett., 51 (2020), 2891–2913. https://doi.org/10.1007/s11063-020-10232-9 doi: 10.1007/s11063-020-10232-9
|
| [42] |
X. Li, J. Wu, X. Tai, J. Xu, Y. Wang, Solving a class of multi-scale elliptic PDEs by Fourier-based mixed physics-informed neural networks, J. Comput. Phys., 508 (2024), 113012. https://doi.org/10.1016/j.jcp.2024.113012 doi: 10.1016/j.jcp.2024.113012
|
| [43] |
S. Zhang, J. Deng, X. Li, Z. Zhao, J. Wu, W. Li, et al., Solving the one-dimensional vertical suspended sediment mixing equation with arbitrary eddy diffusivity profiles using temporal normalized physics-informed neural networks, Phys. Fluids, 36 (2024), 017132. https://doi.org/10.1063/5.0179223 doi: 10.1063/5.0179223
|
| [44] |
X. Li, J. Deng, J. Wu, S. Zhang, W. Li, Y. Wang, Physics-informed neural networks with soft and hard boundary constraints for solving advection-diffusion equations using Fourier expansions, Comput. Math. Appl., 159 (2024), 60–75. https://doi.org/10.1016/j.camwa.2024.01.021 doi: 10.1016/j.camwa.2024.01.021
|
| [45] |
X. Li, J. Wu, L. Zhang, X. Tai, Solving a class of high-order elliptic PDEs using deep neural networks based on its coupled scheme, Mathematics, 10 (2022), 4186. https://doi.org/10.3390/math10224186 doi: 10.3390/math10224186
|
| [46] | X. Li, J. Wu, Y. Huang, Z. Ding, X. Tai, L. Liu, et al., Augmented physics informed extreme learning machine to solve the biharmonic equations via Fourier expansions, preprint, arXiv: 2310.13947. |
| [47] |
Z. Fu, W. Xu, S. Liu, Physics-informed kernel function neural networks for solving partial differential equations, Neural Networks, 172 (2024), 106098. https://doi.org/10.1016/j.neunet.2024.106098 doi: 10.1016/j.neunet.2024.106098
|
| [48] |
J. Bai, G. Liu, A. Gupta, L. Alzubaidi, X. Feng, Y. Gu, Physics-informed radial basis network (PIRBN): A local approximating neural network for solving nonlinear partial differential equations, Comput. Methods Appl. Mech. Eng., 415 (2023), 116290. https://doi.org/10.1016/j.cma.2023.116290 doi: 10.1016/j.cma.2023.116290
|
| [49] | A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, et al., Automatic differentiation in PyTorch, in NIPS 2017 Workshop on Autodiff, (2017), 1–4. |
| [50] | D. P. Kingma, J. Ba, Adam: A method for stochastic optimization, preprint, arXiv: 1412.6980. |









Figures(10) / Tables(2)
Ishtiaq Ali. Advanced machine learning technique for solving elliptic partial differential equations using Legendre spectral neural networks[J]. Electronic Research Archive, 2025, 33(2): 826-848. doi: 10.3934/era.2025037







 DownLoad:
DownLoad: