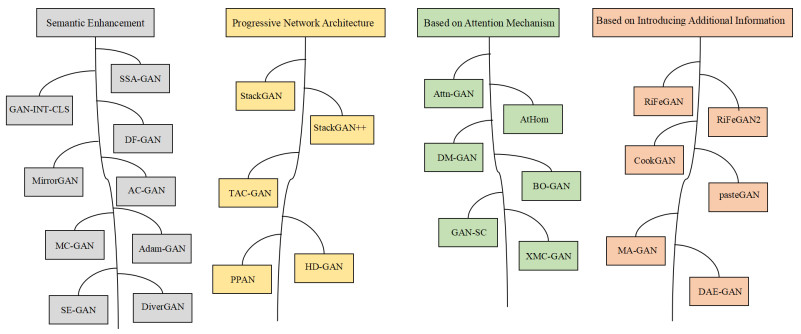
With the continuous development of science and technology (especially computational devices with powerful computing capabilities), the image generation technology based on deep learning has also made significant achievements. Most cross-modal technologies based on deep learning can generate information from text into images, which has become a hot topic of current research. Text-to-image (T2I) synthesis technology has applications in multiple fields of computer vision, such as image enhancement, artificial intelligence painting, games and virtual reality. The T2I generation technology using generative adversarial networks can generate more realistic and diverse images, but there are also some shortcomings and challenges, such as difficulty in generating complex backgrounds. This review will be introduced in the following order. First, we introduce the basic principles and architecture of basic and classic generative adversarial networks (GANs). Second, this review categorizes T2I synthesis methods into four main categories. There are methods based on semantic enhancement, methods based on progressive structure, methods based on attention and methods based on introducing additional signals. We have chosen some of the classic and latest T2I methods for introduction and explain their main advantages and shortcomings. Third, we explain the basic dataset and evaluation indicators in the T2I field. Finally, prospects for future research directions are discussed. This review provides a systematic introduction to the basic GAN method and the T2I method based on it, which can serve as a reference for researchers.
Citation: Wu Zeng, Heng-liang Zhu, Chuan Lin, Zheng-ying Xiao. A survey of generative adversarial networks and their application in text-to-image synthesis[J]. Electronic Research Archive, 2023, 31(12): 7142-7181. doi: 10.3934/era.2023362
With the continuous development of science and technology (especially computational devices with powerful computing capabilities), the image generation technology based on deep learning has also made significant achievements. Most cross-modal technologies based on deep learning can generate information from text into images, which has become a hot topic of current research. Text-to-image (T2I) synthesis technology has applications in multiple fields of computer vision, such as image enhancement, artificial intelligence painting, games and virtual reality. The T2I generation technology using generative adversarial networks can generate more realistic and diverse images, but there are also some shortcomings and challenges, such as difficulty in generating complex backgrounds. This review will be introduced in the following order. First, we introduce the basic principles and architecture of basic and classic generative adversarial networks (GANs). Second, this review categorizes T2I synthesis methods into four main categories. There are methods based on semantic enhancement, methods based on progressive structure, methods based on attention and methods based on introducing additional signals. We have chosen some of the classic and latest T2I methods for introduction and explain their main advantages and shortcomings. Third, we explain the basic dataset and evaluation indicators in the T2I field. Finally, prospects for future research directions are discussed. This review provides a systematic introduction to the basic GAN method and the T2I method based on it, which can serve as a reference for researchers.

| [1] | W. Yu, M. Luo, P. Zhou, C. Si, Y. Zhou, X. Wang, et al., MetaFormer is actually what you need for vision, in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2022), 10809–10819. https://doi.org/10.1109/CVPR52688.2022.01055 |
| [2] | Y. Chen, X. Dai, D. Chen, M. Liu, X. Dong, L. Yuan, et al., Mobile-former: Bridging mobilenet and transforme, in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2022), 5270–5279. https://doi.org/10.1109/CVPR52688.2022.00520 |
| [3] |
A. Priya, K. M. Narendra, F. Binish, S. Pushpendra, A. Gupta, S. D. Joshi, COVID-19 image classification using deep learning: Advances, challenges and opportunities, Comput. Biol. Med., 144 (2022), 105350. https://doi.org/10.1016/j.compbiomed.2022.105350 doi: 10.1016/j.compbiomed.2022.105350

|
| [4] | Y. L. Li, Research and application of deep learning in image recognition, in 2022 IEEE 2nd International Conference on Power, Electronics and Computer Applications (ICPECA), IEEE, (2022), 994–999. https://doi.org/10.1109/ICPECA53709.2022.9718847 |
| [5] |
H. E. Kim, A. Cosa-Linan, N. Santhanam, M. Jannesari, M. E. Maros, T. Ganslandt, Transfer learning for medical image classification: A literature review, BMC Med. Imaging, 22 (2022), 69. https://doi.org/10.1186/s12880-022-00793-7 doi: 10.1186/s12880-022-00793-7
|
| [6] |
Z. Zou, K. Chen, Z. Shi, Y. Guo, J. Ye, Object detection in 20 years: A survey, Proc. IEEE, 111 (2023), 257–276. https://doi.org/10.1109/JPROC.2023.3238524 doi: 10.1109/JPROC.2023.3238524
|
| [7] |
S. B. Xu, M. H. Zhang, W. Song, H. B. Mei, Q. He, A. Liotta, A systematic review and analysis of deep learning-based underwater object detection, Neurocomputing, 527 (2023), 204–232. https://doi.org/10.1016/j.neucom.2023.01.056 doi: 10.1016/j.neucom.2023.01.056
|
| [8] |
T. Diwan, G. Anirudh, J. V. Tembhurne, Object detection using YOLO: Challenges, architectural successors, datasets and applications, Multimedia Tools Appl., 82 (2023), 9243–9275. https://doi.org/10.1007/s11042-022-13644-y doi: 10.1007/s11042-022-13644-y
|
| [9] | S. Frolov, A. Sharma, J. Hees, T. Karayil, F. Raue, A. Dengel, AttrLostGAN: Attribute controlled image synthesis from reconfigurable layout and style, in DAGM German Conference on Pattern Recognition, Springer International Publishing, (2021), 361–375. https://doi.org/10.1007/978-3-030-92659-5_23 |
| [10] | D. Pavllo, A. Lucchi, T. Hofmann, Controlling style and semantics in weakly-supervised image generation, in Computer Vision–ECCV 2020: 16th European Conference, Springer International Publishing, (2020), 482–499. https://doi.org/10.1007/978-3-030-58539-6_29 |
| [11] | R. Wadhawan, T. Drall, S. Singh, S. Chakraverty, Multi-attributed and structured text-to-face synthesis, in 2020 IEEE International Conference on Technology, Engineering, Management for Societal impact using Marketing, Entrepreneurship and Talent (TEMSMET), IEEE, (2020), 1–7. https://doi.org/10.1109/TEMSMET51618.2020.9557583 |
| [12] |
Y. Mei, Y. Fan, Y. Zhang, J. Yu, Y. Zhou, D. Liu, et al., Pyramid attention network for image restoration, Int. J. Comput. Vis., 131 (2023), 1–19. https://doi.org/10.1007/s11263-023-01843-5 doi: 10.1007/s11263-023-01843-5
|
| [13] |
N. Liu, W. Li, Y. Wang, Q. Du, J. Chanussot, A survey on hyperspectral image restoration: From the view of low-rank tensor approximation, Sci. China Inf. Sci., 66 (2023), 140302. https://doi.org/10.1007/s11432-022-3609-4 doi: 10.1007/s11432-022-3609-4
|
| [14] | A. Dabouei, S. Soleymani, F. Taherkhani, N. M. Nasrabadi, SuperMix: Supervising the mixing data augmentation, in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2021), 13789–13798. https://doi.org/10.1109/CVPR46437.2021.01358 |
| [15] |
S. C. Huang, W. N. Fu, Z. Y. Zhang, S. Liu, Global-local fusion based on adversarial sample generation for image-text matching, Inf. Fusion, 103 (2023), 102084. https://doi.org/10.1016/j.inffus.2023.102084 doi: 10.1016/j.inffus.2023.102084
|
| [16] | M. Hong, J. Choi, G. Kim, StyleMix: Separating content and style for enhanced data augmentation, in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2021), 14857–14865. https://doi.org/10.1109/CVPR46437.2021.01462 |
| [17] |
L. Liu, Z. X. Xi, R. R. Ji, W. G. Ma, Advanced deep learning techniques for image style transfer: A survey, Signal Process. Image Commun., 78 (2019), 465–470. https://doi.org/10.1016/j.image.2019.08.006 doi: 10.1016/j.image.2019.08.006
|
| [18] | I. Goodfellow, P. A. Jean, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, et al., Generative adversarial nets, in Advances in Neural Information Processing Systems 27, 27 (2014), 1–9. |
| [19] |
S. Singh, H. Singh, N. Mittal, H. Singh, A. G. Hussien, F. Sroubek, A feature level image fusion for Night-Vision context enhancement using Arithmetic optimization algorithm based image segmentation, Expert Syst. Appl., 209 (2022), 118272. https://doi.org/10.1016/j.eswa.2022.118272 doi: 10.1016/j.eswa.2022.118272
|
| [20] |
N. E. Khalifa, M. Loey, S. Mirjalili, A comprehensive survey of recent trends in deep learning for digital images augmentation, Artif. Intell. Rev., 55 (2022), 2351–2377. https://doi.org/10.1007/s10462-021-10066-4 doi: 10.1007/s10462-021-10066-4
|
| [21] |
Z. L. Chen, K. Pawar, M. Ekanayake, C. Pain, S. J. Zhong, G. F. Egan, Deep learning for image enhancement and correction in magnetic resonance imaging—state-of-the-art and challenges, J. Digital Imaging, 36 (2023), 204–230. https://doi.org/10.1007/s10278-022-00721-9 doi: 10.1007/s10278-022-00721-9
|
| [22] |
Q. Jiang, Y. F. Zhang, F. X. Bao, X. Y. Zhao, C. M. Zhang, P. Liu, Two-step domain adaptation for underwater image enhancement, Pattern Recognit., 122 (2022), 108324. https://doi.org/10.1016/j.patcog.2021.108324 doi: 10.1016/j.patcog.2021.108324
|
| [23] |
T. Rahman, A. Khandakar, Y. Qiblawey, A. Tahir, S. Kiranyaz, S. B. A. Kashem, et al., Exploring the effect of image enhancement techniques on COVID-19 detection using chest X-ray images, Comput. Biol. Med., 132 (2021), 104319. https://doi.org/10.1016/j.compbiomed.2021.104319 doi: 10.1016/j.compbiomed.2021.104319
|
| [24] |
G. F. Li, Y. F. Yang, X. D. Qu, D. P. Cao, K. Q. Li, A deep learning based image enhancement approach for autonomous driving at night, Knowledge-Based Syst., 213 (2021), 106617. https://doi.org/10.1016/j.knosys.2020.106617 doi: 10.1016/j.knosys.2020.106617
|
| [25] | M. Mirza, S. Osindero, Conditional generative adversarial nets, preprint, arXiv: 1411.1784v1. |
| [26] | A. Radford, L. Metz, S. Chintala, Unsupervised representation learning with deep convolutional generative adversarial networks, preprint, arXiv: 1511.06434. |
| [27] | K. R. Chowdhary, Natural language processing, in Fundamentals of Artificial Intelligence, Springer, (2020), 603–649. https://doi.org/10.1007/978-81-322-3972-7_19 |
| [28] |
W. Xu, H. Peng, X. Zeng, F. Zhou, X. Tian, X. Peng, A hybrid modelling method for time series forecasting based on a linear regression model and deep learning, Appl. Intell., 49 (2019), 3002–3015. https://doi.org/10.1007/s10489-019-01426-3 doi: 10.1007/s10489-019-01426-3
|
| [29] |
M. Atlam, H. Torkey, N. El-Fishawy, H. Salem, Coronavirus disease 2019 (COVID-19): Survival analysis using deep learning and Cox regression model, Pattern Anal. Appl., 24 (2021), 993–1005. https://doi.org/10.1007/s10044-021-00958-0 doi: 10.1007/s10044-021-00958-0
|
| [30] |
X. A. Yan, D. M. She, Y. D. Xu, Deep order-wavelet convolutional variational autoencoder for fault identification of rolling bearing under fluctuating speed conditions, Expert Syst. Appl., 216 (2023), 119479. https://doi.org/10.1016/j.eswa.2022.119479 doi: 10.1016/j.eswa.2022.119479
|
| [31] |
W. Khan, M. Haroon, A. N. Khan, M. K. Hasan, A. Khan, U. A. Mokhtar, et al., DVAEGMM: Dual variational autoencoder with gaussian mixture model for anomaly detection on attributed networks, IEEE Access, 10 (2022), 91160–91176. https://doi.org/10.1109/ACCESS.2022.3201332 doi: 10.1109/ACCESS.2022.3201332
|
| [32] |
H. Li, Deep learning for natural language processing: Advantages and challenges, Natl. Sci. Rev., 5 (2018), 24–26. https://doi.org/10.1093/nsr/nwx110 doi: 10.1093/nsr/nwx110
|
| [33] |
B. Pandey, D. K. Pandey, B. P. Mishra, W. Rhmann, A comprehensive survey of deep learning in the field of medical imaging and medical natural language processing: Challenges and research directions, J. King Saud Univ. Comput. Inf. Sci., 34 (2022), 5083–5099. https://doi.org/10.1016/j.jksuci.2021.01.007 doi: 10.1016/j.jksuci.2021.01.007
|
| [34] |
A. G. Russo, A. Ciarlo, S. Ponticorvo, F. D. Salle, G. Tedeschi, F. Esposito, Explaining neural activity in human listeners with deep learning via natural language processing of narrative text, Sci. Rep., 12 (2022), 17838. https://doi.org/10.1038/s41598-022-21782-4 doi: 10.1038/s41598-022-21782-4
|
| [35] |
Y. T. Vuong, Q. M. Bui, H. Nguyen, T. Nguyen, V. Tran, X. Phan, et al., SM-BERT-CR: A deep learning approach for case law retrieval with supporting model, Artif. Intell. Law, 31 (2023), 601–628. https://doi.org/10.1007/s10506-022-09319-6 doi: 10.1007/s10506-022-09319-6
|
| [36] |
R. K. Kaliyar, A. Goswami, P. Narang, FakeBERT: Fake news detection in social media with a BERT-based deep learning approach, Multimedia Tools Appl., 80 (2021), 11765–11788. https://doi.org/10.1007/s11042-020-10183-2 doi: 10.1007/s11042-020-10183-2
|
| [37] |
B. Palani, S. Elango, K. V. Viswanathan, CB-Fake: A multimodal deep learning framework for automatic fake news detection using capsule neural network and BERT, Multimedia Tools Appl., 81 (2022), 5587–5620. https://doi.org/10.1007/s11042-021-11782-3 doi: 10.1007/s11042-021-11782-3
|
| [38] | S. Reed, Z. Akata, X. C. Yan, L. Logeswaran, B. Schiele, H. Lee, Generative adversarial text to image synthesis, in Proceedings of the 33rd International Conference on International Conference on Machine Learning, PMLR, (2016), 1060–1069. |
| [39] | J. Y. Zhu, T. Park, P. Isola, A. A. Efros, Unpaired image-to-image translation using cycle-consistent adversarial networks, in 2017 IEEE International Conference on Computer Vision (ICCV), IEEE, (2017), 2242–2251. https://doi.org/10.1109/ICCV.2017.244 |
| [40] | T. Karras, T. Aila, S. Laine, J. Lehtinen, Progressive growing of GANs for improved quality, stability, and variation, preprint, arXiv: 1710.10196. |
| [41] | H. Zhang, I. Goodfellow, D. Metaxas, A. Odena, Self-attention generative adversarial networks, in Proceedings of the 36th International Conference on Machine Learning, PMLR, (2019), 7354–7363. |
| [42] | A. Odena, C. Olah, J. Shlens, Conditional image synthesis with auxiliary classifier GANs, in Proceedings of the 34rd International Conference on International Conference on Machine Learning, PMLR, (2017), 2642–2651. |
| [43] | H. Park, Y. Yoo, N. Kwak, MC-GAN: Multi-conditional generative adversarial network for image synthesis, preprint, arXiv: 1805.01123. |
| [44] | T. T. Qiao, J. Zhang, D. Q. Xu, D. C. Tao, MirrorGAN: Learning text-to-image generation by redescription, in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2019), 1505–1514. https://doi.org/10.1109/CVPR.2019.00160 |
| [45] | H. C. Tan, X. P. Liu, X. Li, Y. Zhang, B. C. Yin, Semantics-enhanced adversarial nets for text-to-image synthesis, in 2019 IEEE/CVF International Conference on Computer Vision (ICCV), IEEE, (2019), 10500–10509. https://doi.org/10.1109/ICCV.2019.01060 |
| [46] | M. Tao, H. Tang, F. Wu, X. Jing, B. Bao, C. Xu, DF-GAN: A simple and effective baseline for text-to-image synthesis, in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2022), 16494–16504. https://doi.org/10.1109/CVPR52688.2022.01602 |
| [47] | W. T. Liao, K. Hu, M. Y. Yang, B. Rosenhahn, Text to image generation with semantic-spatial aware GAN, in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2022), 18166–18175. https://doi.org/10.1109/CVPR52688.2022.01765 |
| [48] | X. T. Wu, H. B. Zhao, L. L. Zheng, S. H. Ding, X. Li, Adma-GAN: Attribute-driven memory augmented GANs for text-to-image generation, in Proceedings of the 30th ACM International Conference on Multimedia, ACM, (2022), 1593–1602. https://doi.org/10.1145/3503161.3547821 |
| [49] |
Z. X. Zhang, L. Schomaker, DiverGAN: An efficient and effective single-stage framework for diverse text-to-image generation, Neurocomputing, 473 (2022), 182–198. https://doi.org/10.1016/j.neucom.2021.12.005 doi: 10.1016/j.neucom.2021.12.005
|
| [50] | H. Zhang, T. Xu, H. S. Li, S. T. Zhang, X. G. Wang, X. L. Huang, et al., StackGAN: Text to photo-realistic image synthesis with stacked generative adversarial networks, in 2017 IEEE International Conference on Computer Vision (ICCV), IEEE, (2017), 5908–5916. https://doi.org/10.1109/ICCV.2017.629 |
| [51] |
H. Zhang, T. Xu, H. S. Li, S. T. Zhang, X. G. Wang, X. L. Huang, et al., StackGAN++: Realistic image synthesis with stacked generative adversarial networks, IEEE Trans. Pattern Anal. Mach. Intell., 41 (2019), 1947–1962. https://doi.org/10.1109/TPAMI.2018.2856256 doi: 10.1109/TPAMI.2018.2856256
|
| [52] | A. Dash, J. C. B. Gamboa, S. Ahmed, M. Liwicki, M. Z. Afzal, TAC-GAN - text conditioned auxiliary classifier generative adversarial network, preprint, arXiv: 1703.06412. |
| [53] | Z. Z. Zhang, Y. P. Xie, L. Yang, Photographic text-to-image synthesis with a hierarchically-nested adversarial network, in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, IEEE, (2018), 6199–6208. https://doi.org/10.1109/CVPR.2018.00649 |
| [54] | L. L. Gao, D. Y. Chen, J. G. Song, X. Xu, D. X. Zhang, H. T. Shen, Perceptual pyramid adversarial networks for text-to-image synthesis, in Proceedings of the AAAI Conference on Artificial Intelligence, AAAI, (2019), 8312–8319. https://doi.org/10.1609/aaai.v33i01.33018312 |
| [55] | T. Xu, P. C. Zhang, Q. Y. Huang, H. Zhang, Z. Gan, X. L. Huang, et al., AttnGAN: Fine-grained text to image generation with attentional generative adversarial networks, in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, IEEE, (2018), 1316–1324. https://doi.org/10.1109/CVPR.2018.00143 |
| [56] | T. Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, et al., Microsoft COCO: Common objects in context, in Computer Vision–ECCV 2014: 13th European Conference, Springer, (2014), 740–755. https://doi.org/10.1007/978-3-319-10602-1_48 |
| [57] | T. Salimans, I. Goodfellow, W. Zaremba, V. Cheung, A. Radford, X. Chen, Improved techniques for training GANs, in Advances in Neural Information Processing Systems 29, 29 (2016), 1–9. |
| [58] | M. F. Zhu, P. B. Pan, W. Chen, Y. Yang, DM-GAN: Dynamic memory generative adversarial networks for text-to-image synthesis, in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2019), 5795–5803. https://doi.org/10.1109/CVPR.2019.00595 |
| [59] | H. Zhang, J. Y. Koh, J. Baldridge, H. Lee, Y. Yang, Cross-modal contrastive learning for text-to-image generation, in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2021), 833–842. https://doi.org/10.1109/CVPR46437.2021.00089 |
| [60] | Z. B. Shi, Z. Chen, Z. B. Xu, W. Yang, L. Huang, AtHom: Two divergent attentions stimulated by homomorphic training in text-to-image synthesis, in Proceedings of the 30th ACM International Conference on Multimedia, ACM, (2022), 2211–2219. https://doi.org/10.1145/3503161.3548159 |
| [61] | Z. W. Chen, Z. D. Mao, S. C. Fang, B. Hu, Background layout generation and object knowledge transfer for text-to-image generation, in Proceedings of the 30th ACM International Conference on Multimedia, ACM, (2022), 4327–4335. https://doi.org/10.1145/3503161.3548154 |
| [62] |
Y. Ma, L. Liu, H. X. Zhang, C. J. Wang, Z. K. Wang, Generative adversarial network based on semantic consistency for text-to-image generation, Appl. Intell., 53 (2023), 4703–4716. https://doi.org/10.1007/s10489-022-03660-8 doi: 10.1007/s10489-022-03660-8
|
| [63] | Y. K. Li, T. Ma, Y. Q. Bai, N. Duan, S. Wei, X. Wang, Pastegan: A semi-parametric method to generate image from scene graph, in Advances in Neural Information Processing Systems 32, 32 (2019), 1–11. |
| [64] | B. Zhu, C. W. Ngo, CookGAN: Causality based text-to-image stynthesis, in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2020), 5518–5526. https://doi.org/10.1109/CVPR42600.2020.00556 |
| [65] | J. Cheng, F. X. Wu, Y. L. Tian, L. Wang, D. Tao, RiFeGAN: Rich feature generation for text-to-image synthesis from prior knowledge, in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2020), 10908–10917. https://doi.org/10.1109/CVPR42600.2020.01092 |
| [66] |
J. Cheng, F. X. Wu, Y. L. Tian, L. Wang, D. Tao, RiFeGAN2: Rich feature generation for text-to-image synthesis from constrained prior knowledge, IEEE Trans. Circuits Syst. Video Technol., 32 (2022), 5187–5200. https://doi.org/10.1109/TCSVT.2021.3136857 doi: 10.1109/TCSVT.2021.3136857
|
| [67] |
Y. H. Yang, L. Wang, D. Xie, C. Deng, D. Tao, Multi-sentence auxiliary adversarial networks for fine-grained text-to-image synthesis, IEEE Trans. Image Process., 30 (2021), 2798–2809. https://doi.org/10.1109/TIP.2021.3055062 doi: 10.1109/TIP.2021.3055062
|
| [68] | S. L. Ruan, Y. Zhang, K. Zhang, Y. B. Fan, F. Tang, Q. Liu, et al., DAE-GAN: Dynamic aspect-aware GAN for text-to-image synthesis, in 2021 IEEE/CVF International Conference on Computer Vision (ICCV), IEEE, (2021), 13940–13949. https://doi.org/10.1109/ICCV48922.2021.01370 |
| [69] |
M. Lee, J. Seok, Controllable generative adversarial network, IEEE Access, 7 (2019), 28158–28169. https://doi.org/10.1109/ACCESS.2019.2899108 doi: 10.1109/ACCESS.2019.2899108
|
| [70] | T. T. Qiao, J. Zhang, D. Q. Xu, D. C. Tao, Learn, imagine and create: Text-to-image generation from prior knowledge, in Advances in Neural Information Processing Systems 32, 32 (2019), 1–11. |
| [71] | S. Nam, Y. Kim, S. J. Kim, Text-adaptive generative adversarial networks: Manipulating images with natural language, in 2018 Advances in Neural Information Processing Systems 31, 31 (2018), 42–51. |
| [72] | B. W. Li, X. J. Qi, T. Lukasiewicz, P. Torr, ManiGAN: Text-guided image manipulation, in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2020), 7877–7886. https://doi.org/10.1109/CVPR42600.2020.00790 |
| [73] |
J. Peng, Y. Y. Zhou, X. S. Sun, L. J. Cao, Y. J. Wu, F. Y. Huang, et al., Knowledge-driven generative adversarial network for text-to-image synthesis, IEEE Trans. Multimedia, 24 (2020), 4356–4366. https://doi.org/10.1109/TMM.2021.3116416 doi: 10.1109/TMM.2021.3116416
|
| [74] |
T. Hinz, S. Heinrich, S. Wermter, Semantic object accuracy for generative text-to-image synthesis, IEEE Trans. Pattern Anal. Mach. Intell., 44 (2022), 1552–1565. https://doi.org/10.1109/TPAMI.2020.3021209 doi: 10.1109/TPAMI.2020.3021209
|
| [75] | H. Wang, G. H. Lin, S. C. H. Hoi, C. Y. Miao, Cycle-consistent inverse GAN for text-to-image synthesis, in Proceedings of the 29th ACM International Conference on Multimedia, ACM, (2021), 630–638. https://doi.org/10.1145/3474085.3475226 |
| [76] |
H. C. Tan, X. P. Liu, B. C. Yin, X. Li, Cross-modal semantic matching generative adversarial networks for text-to-image synthesis, IEEE Trans. Multimedia, 24 (2022), 832–845. https://doi.org/10.1109/TMM.2021.3060291 doi: 10.1109/TMM.2021.3060291
|
| [77] | M. Cha, Y. L. Gwon, H. T. Kung, Adversarial learning of semantic relevance in text to image synthesis, in 2019 Proceedings of the AAAI conference on artificial intelligence, AAAI, (2019), 3272–3279. https://doi.org/10.1609/aaai.v33i01.33013272 |
| [78] |
K. E. Ak, J. H. Lim, J. Y. Tham, A. A. Kassim, Semantically consistent text to fashion image synthesis with an enhanced attentional generative adversarial network, Pattern Recognit. Lett., 135 (2020), 22–29. https://doi.org/10.1016/j.patrec.2020.02.030 doi: 10.1016/j.patrec.2020.02.030
|
| [79] | G. J. Yin, B. Liu, L. Sheng, N. H. Yu, X. G. Wang, J. Shao, Semantics disentangling for text-to-image generation, in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2019), 2322–2331. https://doi.org/10.1109/CVPR.2019.00243 |
| [80] | W. H. Xia, Y. J. Yang, J. H. Xue, B. Y. Wu, TediGAN: Text-guided diverse face image generation and manipulation, in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2021), 2256–2265. https://doi.org/10.1109/CVPR46437.2021.00229 |
| [81] | J. C. Sun, Y. M. Zhou, B. Zhang, ResFPA-GAN: Text-to-image synthesis with generative adversarial network based on residual block feature pyramid attention, in 2019 IEEE International Conference on Advanced Robotics and its Social Impacts (ARSO), IEEE, (2019), 317–322. https://doi.org/10.1109/ARSO46408.2019.8948717 |
| [82] | M. E. Nilsback, A. Zisserman, Automated flower classification over a large number of classes, in 2008 Sixth Indian Conference on Computer Vision, Graphics & Image Processing, IEEE, (2008), 722–729. https://doi.org/10.1109/ICVGIP.2008.47 |
| [83] | C. Wah, S. Branson, P. Welinder, P. Perona, S. Belongie, The caltech-ucsd birds-200-2011 dataset: Technical report CNS-TR-2011-001, (2011), 1–8. |
| [84] | Y. Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, A. Y. Ng, Reading digits in natural images with unsupervised feature learning, in NIPS Workshop on Deep Learning and Unsupervised Feature Learning 2011, NeurIPS, (2011), 1–9. |
| [85] | A. Krizhevsky, Learning Multiple Layers of Features from Tiny Images, Master's thesis, University of Toronto, 2009. |
| [86] | T. Karras, T. Aila, S. Laine, J. Lehtinen, Progressive growing of GANs for improved quality, stability, and variation, preprint, arXiv: 1710.10196. |
| [87] |
Y. Lecun, L. Bottou, Y. Bengio, P. Haffner, Gradient-based learning applied to document recognition, Proc. IEEE, 86 (1998), 2278–2324. https://doi.org/10.1109/5.726791 doi: 10.1109/5.726791
|
| [88] | M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, S. Hochreiter, GANs trained by a two time-scale update rule converge to a local nash equilibrium, in Advances in Neural Information Processing Systems 30, 30 (2017), 1–12. |
| [89] | T. Sylvain, P. C. Zhang, Y. Bengio, R. D. Hjelm, S. Sharma, Object-centric image generation from layouts, preprint, arXiv: 2003.07449. |
| [90] |
Z. Wang, A. C. Bovik, H. R. Sheikh, E. P. Simoncelli, Image quality assessment: From error visibility to structural similarity, IEEE Trans. Image Process., 13 (2004), 600–612. https://doi.org/10.1109/TIP.2003.819861 doi: 10.1109/TIP.2003.819861
|
| [91] | R. Zhang, P. Isola, A. A. Efros, E. Shechtman, O. Wang, The unreasonable effectiveness of deep features as a perceptual metric, in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2018), 586–595. https://doi.org/10.1109/CVPR.2018.00068 |
| [92] | S. R. Zhou, M. L. Gordon, R. Krishna, A. Narcomey, L. F. Fei-Fei, M. Bernstein, HYPE: A benchmark for human eye perceptual evaluation of generative models, in Advances in Neural Information Processing Systems 32, 32 (2019), 3449–3461. |
| [93] |
M. Wang, C. Y. Lang, L. Q. Liang, S. H. Feng, T. Wang, Y. T. Gao, End-to-end text-to-image synthesis with spatial constrains, ACM Trans. Intell. Syst. Technol., 11 (2020), 2157–6904. https://doi.org/10.1145/3391709 doi: 10.1145/3391709
|
| [94] | F. W. Tan, S. Feng, V. Ordonez, Text2Scene: Generating compositional scenes from textual descriptions, in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2019), 6703–6712. https://doi.org/10.1109/CVPR.2019.00687 |
| [95] |
B. Zhao, W. D. Yin, L. L. Meng, L. Sigal, Layout2image: Image generation from layout, Int. J. Comput. Vision, 128 (2020), 2418–2435. https://doi.org/10.1007/s11263-020-01300-7 doi: 10.1007/s11263-020-01300-7
|
| [96] | S. Hong, D. D. Yang, J. Choi, H. Lee, Inferring semantic layout for hierarchical text-to-image synthesis, in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2018), 7986–7994. https://doi.org/10.1109/CVPR.2018.00833 |
| [97] | M. Q. Huang, Z. D. Mao, P. H. Wang, Q. Wang, Y. D. Zhang, DSE-GAN: Dynamic semantic evolution generative adversarial network for text-to-image generation, in Proceedings of the 30th ACM International Conference on Multimedia, ACM, (2022), 4345–4354. https://doi.org/10.1145/3503161.3547881 |
| [98] | F. Fang, Z. Q. Li, F. Luo, C. J. Long, S. Hu, C. Xiao, PhraseGAN: Phrase-boost generative adversarial network for text-to-image generation, in 2022 IEEE International Conference on Multimedia and Expo (ICME), IEEE, (2022), 1–6. https://doi.org/10.1109/ICME52920.2022.9859623 |
| [99] | Z. H. Li, M. R. Min, K. Li, C. L. Xu, StyleT2I: Toward compositional and high-fidelity text-to-image synthesis, in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2022), 18176–18186. https://doi.org/10.1109/CVPR52688.2022.01766 |
| [100] |
H. Luo, Y. R. Wang, J. Cui, A SVDD approach of fuzzy classification for analog circuit fault diagnosis with FWT as preprocessor, Expert Syst. Appl., 38 (2011), 10554–10561. https://doi.org/10.1016/j.eswa.2011.02.087 doi: 10.1016/j.eswa.2011.02.087
|
| [101] |
M. Versaci, F. C. Morabito, G. Angiulli, Adaptive image contrast enhancement by computing distances into a 4-dimensional fuzzy unit hypercube, IEEE Access, 5 (2017), 26922–26931. https://doi.org/10.1109/ACCESS.2017.2776349 doi: 10.1109/ACCESS.2017.2776349
|






















Figures(23) / Tables(2)
Wu Zeng, Heng-liang Zhu, Chuan Lin, Zheng-ying Xiao. A survey of generative adversarial networks and their application in text-to-image synthesis[J]. Electronic Research Archive, 2023, 31(12): 7142-7181. doi: 10.3934/era.2023362







 DownLoad:
DownLoad: