Citation: Mowffaq M. Oreijah, Mohammed Yunus. A parametric analysis to evaluate the performance metrics of power generation system involving Trilateral Flash Cycle using three different working fluids for low grade waste heat[J]. AIMS Energy, 2019, 7(4): 483-492. doi: 10.3934/energy.2019.4.483

| [1] | DiPippo R (2008). Geothermal Power Plants: Principles, Applications, Case Studies and Environmental Impact, 2 Eds., Oxford: Butterworth Heinemann. |
| [2] | Oreijah M, Date A, Akbarzadaha A (2014) Comparison between rankine cycle and trilateral cycle in binary system for power generation. Appl Mech Mater 464: 151–155. |
| [3] |
Fischer J (2011). Comparison of trilateral cycles and organic Rankine cycles. Energy 36: 6208–6219. doi: 10.1016/j.energy.2011.07.041

|
| [4] |
Forman C, Muritala IK, Pardemann R, et al. (2016) Estimating the global waste heat potential. Renewable Sustainable Energy Rev 57: 1568–1579. doi: 10.1016/j.rser.2015.12.192
|
| [5] |
Di Battista D, Mauriello M, Cipollone R (2015) Waste heat recovery of an ORC-based power unit in a turbocharged diesel engine propelling a light duty vehicle. Appl Energy 152: 109–120. doi: 10.1016/j.apenergy.2015.04.088
|
| [6] | Cipollone R, Bianchi G, Gualtieri A, et al. (2015) Development of an Organic Rankine Cycle system for exhaust energy recovery in internal combustion engines, J Phys: Conf Ser 655: 012015. |
| [7] | Hu L, Wang Z, Fan W, et al. (1989) An organic total flow system for geothermal energy and waste heat conversion. Proceedings of the 24th Intersociety Energy Conversion Engineering Conference 5: 2161–2165. |
| [8] |
Smith IK (1992) Matching and work ratio in elementary thermal power plant theory. Proc Inst Mech Eng, Part A: J Power Energy 206: 257–262. doi: 10.1243/PIME_PROC_1992_206_042_02
|
| [9] |
DiPippo R (2007). Ideal thermal efficiency for geothermal binary plants. Geothermic 36: 276–285. doi: 10.1016/j.geothermics.2007.03.002
|
| [10] |
Ibrahim OM, Klein SA (1996) Absorption power cycles. Energy 21: 21–27. doi: 10.1016/0360-5442(95)00083-6
|
| [11] | White FM (1986) Fluid Mechanics, 2 Eds., New York: McGraw-Hill Book Company. |
| [12] |
Saleh B, Koglbauer G, Wendland M, et al. (2007) Working fluids for low-temperature organic Rankine cycles. Energy 32: 1210–1221. doi: 10.1016/j.energy.2006.07.001
|
| [13] | Da Silva RPM (1989) Organic fluid mixtures as working fluids for the trilateral flash cycle system. Doctoral thesis, City University, London. |
| [14] |
Ho T, Mao SS, Greif R (2012) Comparison of the Organic Flash Cycle (OFC) to other advanced vapor cycles for intermediate and high temperature waste heat reclamation and solar thermal energy. Energy 42: 213–223. doi: 10.1016/j.energy.2012.03.067
|
| [15] |
Cipollonea R, Bianchia G, Di Bartolomeoa M, et al. (2017) Low grade thermal recovery based on trilateral flash cycles using recent pure fluids and mixtures. Energy Procedia 123: 289–296. doi: 10.1016/j.egypro.2017.07.246
|
| [16] |
Bianchi G, McGinty R, Oliver D, et al. (2017) Development and analysis of a packaged Trilateral Flash Cycle system for low grade heat to power conversion applications. Therm Sci Eng Prog 4: 113–121. doi: 10.1016/j.tsep.2017.09.009
|
| [17] | Md Arbab I, Sohel R, Mahdi A, et al. (2018)Thomas Close, Abhijit Date, Aliakbar Akbarzadeh, Prospects of Trilateral Flash Cycle (TFC) for power generation from low grade heat sources. 3rd International Conference on Power and Renewable Energy, Berlin, Germany. |
| [18] |
Varma GVP, Srinivas T (2017) Power generation from low temperature heat recovery. Renewable Sustainable Energy Rev 75: 402–414. doi: 10.1016/j.rser.2016.11.005
|
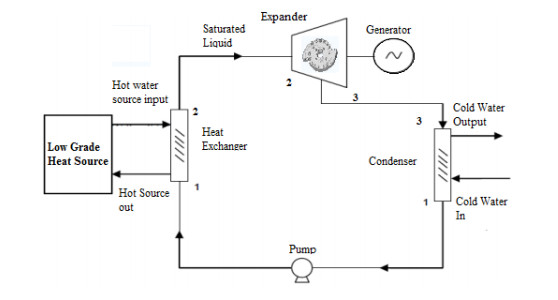
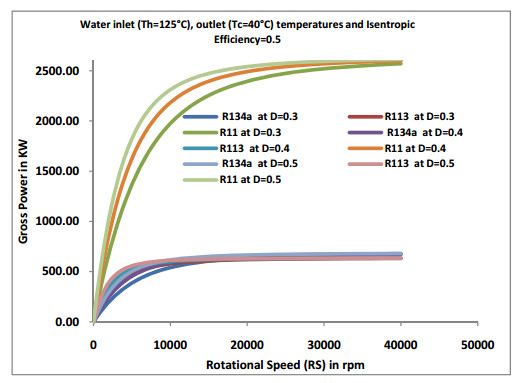
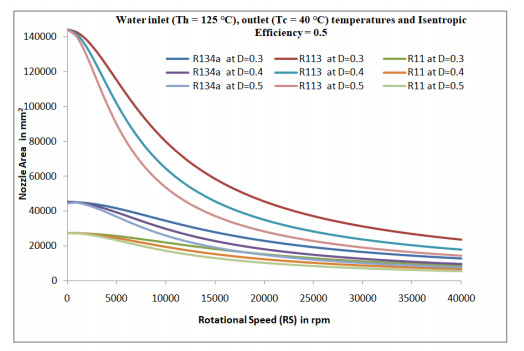
Figures(5)

Mowffaq M. Oreijah, Mohammed Yunus. A parametric analysis to evaluate the performance metrics of power generation system involving Trilateral Flash Cycle using three different working fluids for low grade waste heat[J]. AIMS Energy, 2019, 7(4): 483-492. doi: 10.3934/energy.2019.4.483







 DownLoad:
DownLoad: