Citation: Irina A. Zamulaeva, Kristina A. Churyukina, Olga N. Matchuk, Alexander A. Ivanov, Vyacheslav O. Saburov, Alexei L. Zhuze. Dimeric bisbenzimidazoles DB(n) in combination with ionizing radiation decrease number and clonogenic activity of MCF-7 breast cancer stem cells[J]. AIMS Biophysics, 2020, 7(4): 339-361. doi: 10.3934/biophy.2020024

| [1] | Peitzch C, Kurth I, Ebert N, et al. (2019) Cancer stem cells in radiation response: current views and future perspectives in radiation oncology. Int J Radiat Biol 95: 900-911. |
| [2] | Zhu P, Fan Z (2018) Cancer stem cells and tumorigenesis. Biophys Rep 4: 178-188. |
| [3] | Lytle NK, Barber AG, Reya T (2018) Stem cells fate in cancer growth, progression and therapy resistance. Nat Rev Cancer 18: 669-680. |
| [4] | Battle E, Clevers H (2017) Cancer stem cells revisited. Nat Med 23: 1124-1134. |
| [5] | Matchuk ON, Zamulaeva IA, Selivanova EI, et al. (2012) Sensitivity of melanoma B16 side population to low- and high-LET radiation. Radiats Biol Radioecol 52: 261-267. |
| [6] | Kaiser J (2015) The cancer stem cell gamble. Science 347: 226-229. |
| [7] | Ahmed M, Chaudhari K, Babaeli-Jadidi R, et al. (2017) Concise review: Emerging drugs targeting epithelial cancer stem-like cells. Stem Celsl 35: 839-850. |
| [8] | Desai A, Yan Y, Gerson SL (2019) Concise reviews: Cancer stem cell targeted therapies: toward clinical success. Stem Cells Transl Med 8: 75-81. |
| [9] | Kim YJ, Siegler EL, Siriwon N, et al. (2016) Therapeutic strategies for targeting cancer stem cells. J Cancer Metastasis Treat 2: 233-242. |
| [10] | Pan Y, Ma S, Cao K, et al. (2018) Therapeutic approaches targeting cancer stem cells. J Cancer Res Ther 14: 1469-1475. |
| [11] | Dominik Kuhlmann J, Hein L, Kurth I, et al. (2016) Targeting cancer stem cells: Promises and challenges. Anticancer Agents Med Chem 16: 38-58. |
| [12] | Nunes T, Hamdan D, Leboeuf C, et al. (2018) Targeting cancer stem cells to overcome chemoresistance. Int J Mol Sci 19: e4036. |
| [13] | Phi LTH, Sari IN, Yang YG, et al. (2018) Cancer stem cells (CSCs) in drug resistance and their therapeutic implications in cancer treatment. Stem Cells Int 2018: 5416923. |
| [14] | Wainwright EN, Scaffidi P (2017) Epigenetics and cancer stem cells: Unleashing hijacking, and restricting cellular plasticity. Trends Cancer 3: 372-386. |
| [15] | Toh TB, Lim JJ, Chow EK (2017) Epigenetics in cancer stem cells. Mol Cancer 16: 29. |
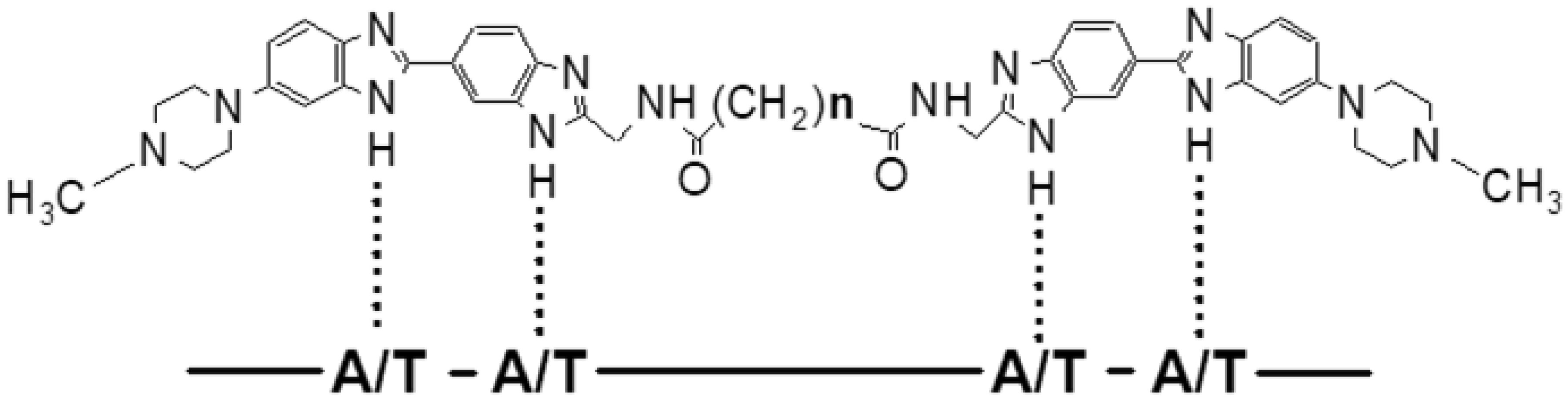
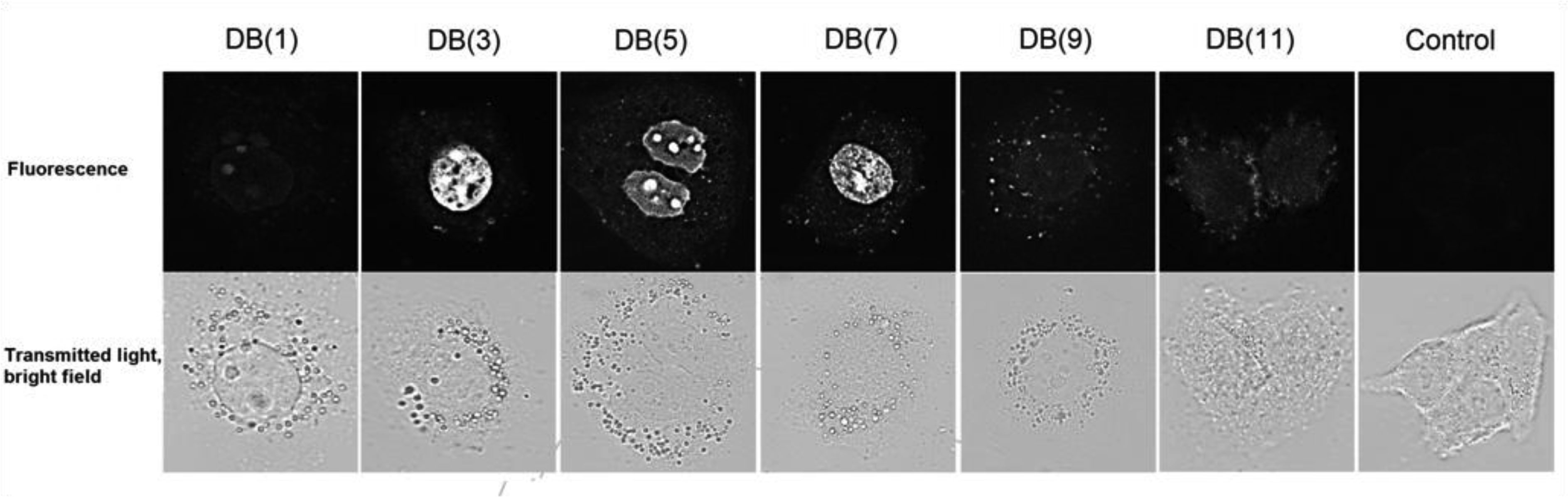
| [16] | Ivanov AA, Salyanov VI, Strel'tsov SA, et al. (2011) DNA sequence-specific ligands: XIV. Synthesis of fluorescent biologicaly active dimeric bisbenzimidazoles-DB (3, 4, 5, 7, 11). Russ J Bioorgan Chem 37: 472-482. |
| [17] | Ivanov AA, Salyanov VI, Zhuze AL (2016) DNA sequence specific ligands: XV. synthesis and spectral characteristics of a new series of dimeric bisbenzimidazoles DB(1, 2, 6, 8, 9, 10, 12). Russ J Bioorgan Chem 42: 183-190. |
| [18] | Cherepanova NA, Ivanov AA, Maltseva DV, et al. (2011) Dimeric bisbenzimidazoles inhibit the DNA methylation catalyzed by the Dnmt3a catalytic domain. J Ensyme Inhib Med Chem 26: 295-300. |
| [19] | Susova OY, Ivanov AA, Ruiz SSM, et al. (2010) Minor groove dimeric bisbenzimidazoles inhibit in vitro DNA binding to eukaryotic DNA topoisomerase I. Biochemistry (Mosc) 75: 695-701. |
| [20] | Loewe H, Urbanietz J (1974) Basic-substituted 2,6-bisbenzimidazole derivates, a novel class of substances with chemotherapeutic activity. Arzneimittel-forschung 24: 1927-1933. |
| [21] | Popov KV, Egorova EI, Ivanov AA, et al. (2008) Dimeric bisbenzimidazole Hoechst 33258-related dyes as novel AT-specific DNA-binding fluorochromes for human and plant cytogenetics. Biochem (Mosc) Suppl Ser A: Membr Cell Biol 2: 203-209. |
| [22] | Petin VG, Kim JK (2016) Synergistic Interaction and Cell Responses to Environmental Factors New York: Nova Science Publishers, 100-101. |
| [23] | Lee SY, Jeong EK, Ju MK, et al. (2017) Induction of metastasis, cancer stem cell phenotype, and oncogenic metabolism in cancer cells by ionizing radiation. Mol Cancer 16: 10. |
| [24] | Li F, Zhou K, Gao L, et al. (2016) Radiation induced the generation of cancer stem cells: A novel mechanism for cancer radioresistance. Oncol Lett 12: 3059-3065. |
| [25] | Chi HC, Tsai CY, Tsai MM, et al. (2017) Roles of long noncoding RNAs in recurrence and metastasis of radiotherapy-resistant cancer stem cells. Int J Mol Sci 18: e1903. |
| [26] | Lyubimova NV, Coultas PG, Yuen K, et al. (2001) In vivo radioprotection of mouse brain endothelial cells by Hoechst 33342. Br J Radiol 74: 77-82. |
| [27] | Lobachevsky P, Ivashkevich A, Martin OA, et al. (2011) DNA-binding radioprotectors. Selected Topics in DNA Repair London: IntechOpen, 497-519. |
| [28] | Martin RF, Broadhurst S, Reum ME, et al. (2004) In vitro studies with methylproamine: A potent new radioprotector. Cancer Res 64: 1067-1070. |
| [29] | Tawar U, Jain AK, Dwarakanath BS, et al. (2003) Influence of phenyl ring disubstitution on bisbenzimidazole and terbenzimidazole cytotoxicity: synthesis and biological evaluation as radioprotectors. J Med Chem 46: 3785-3792. |
| [30] | Martin RF, Denison L (1992) DNA ligands as radiomodifiers: studies with minor-groove binding bibenzimidazoles. Int J Rad Oncol Biol Phys 23: 579-584. |
| [31] | Kim JS, Sun Q, Yu C, et al. (1998) Quantitative structure-activity relationships on 5-substituted terbenzimidazoles as topoisomerase I poisons and antitumor agents. Bioorg Med Chem 6: 163-172. |
| [32] | Shunkwiler L, Ferris G, Kunos C (2013) Inhibition of poly(ADP-Ribose) polymerase enhances radiochemosensitivity in cancers proficient in DNA double-strand break repair. Int J Mol Sci 14: 3773-3785. |
| [33] | Sun Q, Gatto B, Yu C, et al. (1994) Structure activity of topoisomerase I poisons related to Hoechst 333342. Bioorg Med Chem Lett 4: 2871-2876. |
| [34] | Parchment RE, Pessina A (1998) Topoisomerase I inhibitors and drug resistance. Cytotechnology 27: 149-164. |
| [35] | Berney DM, Shamash J, Gaffney J, et al. (2002) DNA topoisomerase I and II expression in drug resistant germ cell tumours. Br J Cancer 87: 624-629. |
| [36] | Dwarakanath BS, Singh S, Jain V (1999) Optimization of tumor radiotherapy: Part V-radiosensitization by 2-deoxy-D-glucose and DNA ligand hoechest-33342 in a murine tumor. Indian J Exp Biol 37: 865-870. |
| [37] | Adhikari JS, Khaitan D, Arya MB, et al. (2005) Heterogeneity in the radiosensitizing effects of the DNA ligands hoechst-33342 in human tumor cell lines. J Cancer Res Ther 1: 151-161. |
| [38] | Wera AC, Lobbens A, Stoyanov M, et al. (2019) Radiation-induced synthetic lethality: combination of poly(ADP-ribose) polymerase and RAD51 inhibitors to sensitize cells to proton irradiation. Cell Cycle 18: 1770-1783. |
| [39] | Ashworth A (2008) A synthetic lethal therapeutic approach: Poly(ADP) ribose polymerase inhibitors for the treatment of cancers deficient in DNA double-strand break repair. J Clin Oncol 26: 3785-3790. |
| [40] | Begicevic RR, Falasca M (2017) ABC transporters in cancer stem cells: beyond chemoresistance. Int J Mol Sci 18: e2362. |
| [41] | Krause M, Dubrovska A, Linge A, et al. (2017) Cancer stem cells: Radioresistance, prediction of radiotherapy outcome and specific targets for combined treatments. Adv Drug Deliv Rev 109: 63-73. |
| [42] | Lagadec C, Vlashi E, Donna LD, et al. (2012) Radiation-induced reprogramming of breast cancer cells. Stem Cells 30: 833-844. |
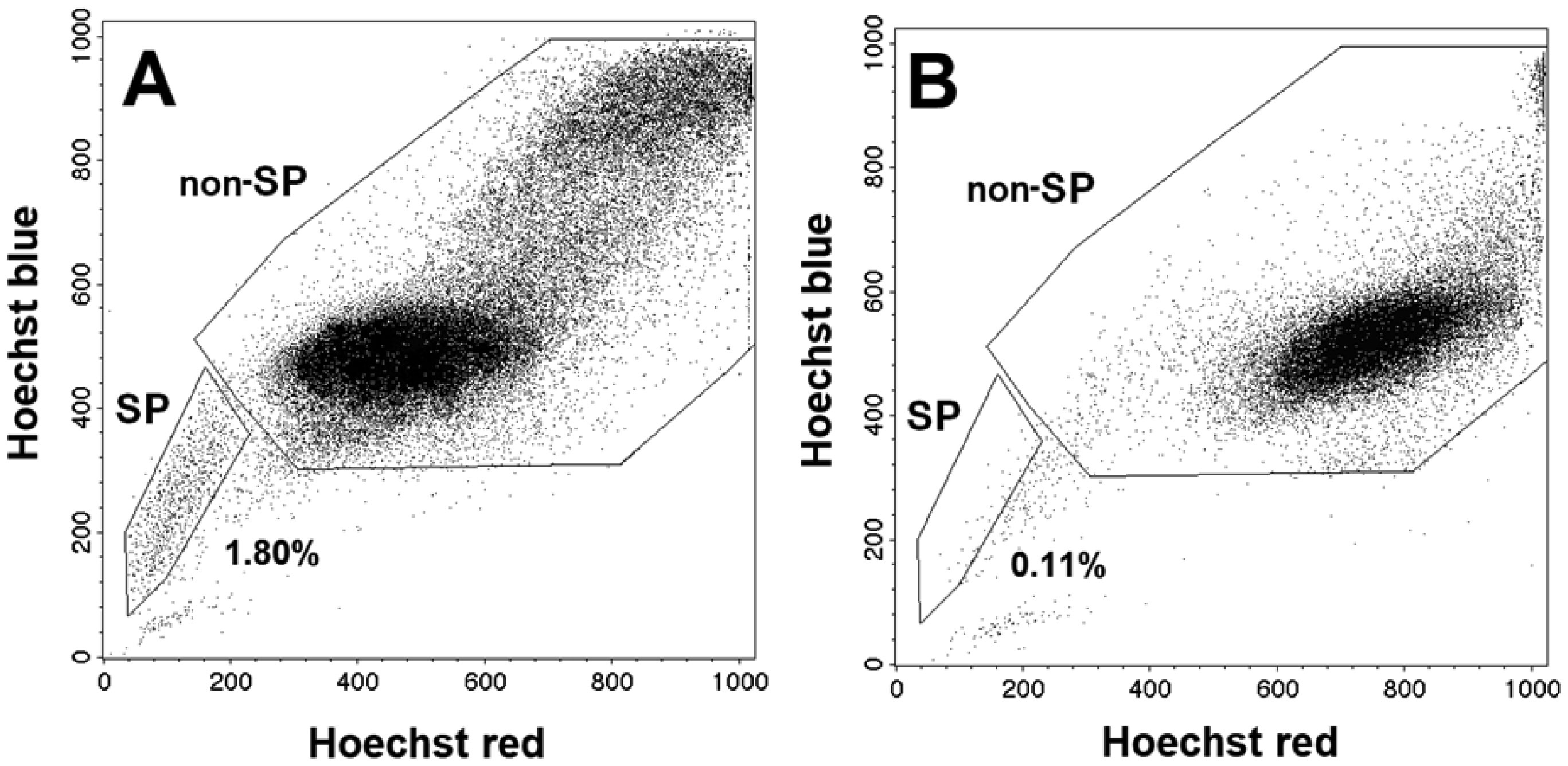
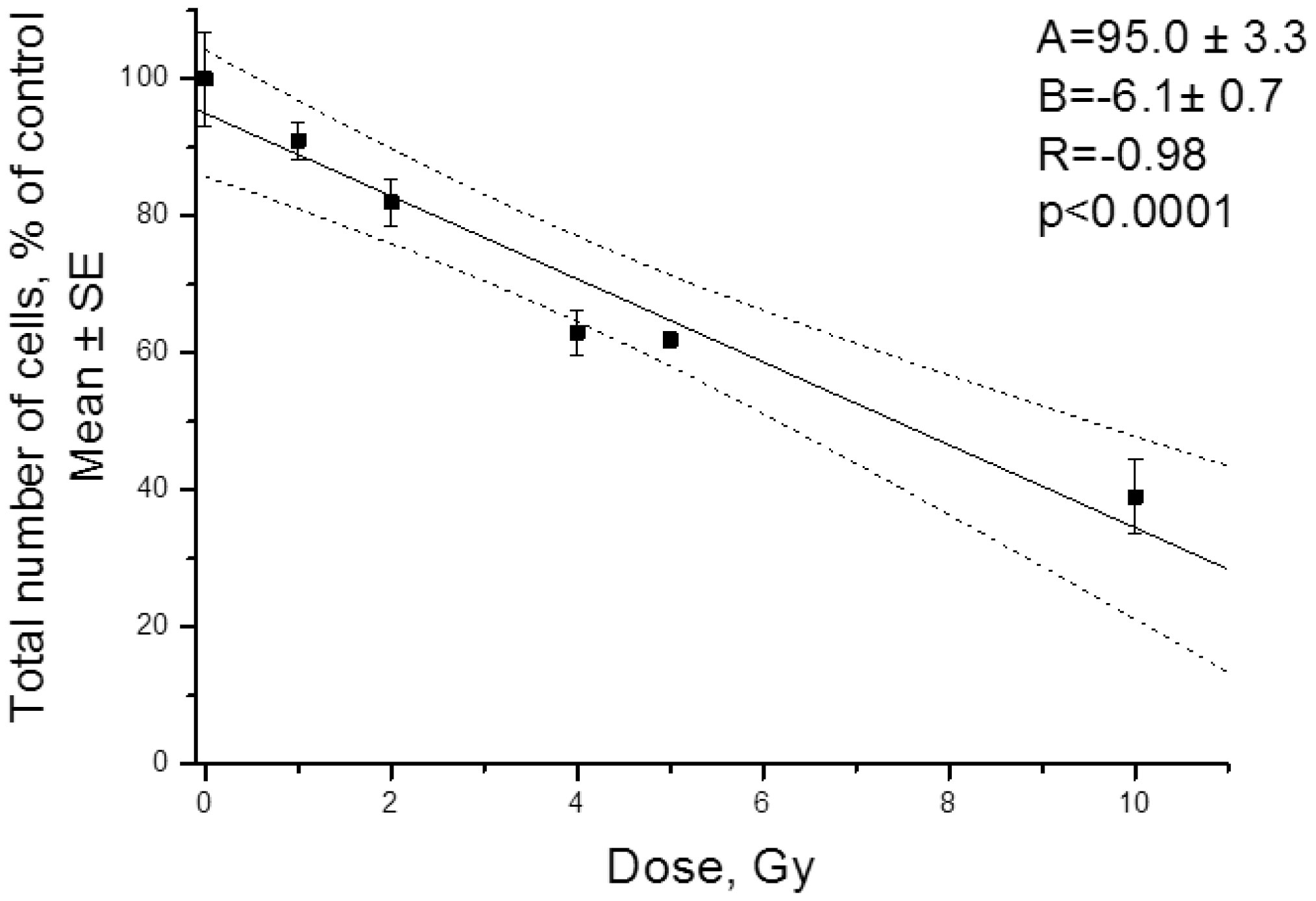
| [43] | Zamulaeva IA, Matchuk ON, Selivanova EI, et al. (2014) Increase in the number of cancer stem cells after exposure to low-LET radiation. Radiats Biol Radioecol 54: 256-264. |
| [44] | Murata K, Saga R, Monzen S, et al. (2019) Understanding the mechanism underlying the acquisition of radioresistance in human prostate cancer cells. Oncol Lett 17: 5830-5838. |
| [45] | Matchuk ON, Zamulaeva IA (2019) Quantitative changes in the stem cell population of cervical cancer cell line HeLa under the influence of fractionated γ-irradiation in vitro. Radiation and Risk 28: 112-123. |
| [46] | Boulding T, McCuaig RD, Tan A, et al. (2018) LSD1 activation promotes inducible EMT programs and modulates the tumour microenvironment in breast cancer. Sci Rep 8: 73. |
| [47] | Ambrosio S, Sacca CD, Majello B (2017) Epigenetic regulation of epithelial to mesenchymal transition by the Lysine-specific demethylase LSD1/KDM1A. Biochim Biophys Acta Gene Regul Mech 1860: 905-910. |
| [48] | Kanamoto A, Ninomiya I, Harada S, et al. (2016) Valproic acid inhibits irradiation-induced epithelial-mesenchymal transition and stem cell-like characteristics in esophageal squamous cell carcinoma. Int J Oncol 49: 1859-1869. |
| [49] | Garg M (2017) Epithelial plasticity and cancer stem cells: Major mechanisms of cancer pathogenesis and therapy resistance. World J Stem Cells 9: 118-126. |
| [50] | Kotiyal S, Bhattacharya S (2014) Breast cancer stem cells, EMT and therapeutic targets. Biochem Biophys Res Commun 453: 112-116. |
| [51] | Miousse IR, Kutanzi KR, Koturbash I (2017) Effects of ionizing radiation on DNA methylation: from experimental biology to clinical applications. Int J Radiat Biol 93: 457-469. |
| [52] | Luczak MW, Jagodzinski PP (2006) The role of DNA methylation in cancer development. Folia Histochem Cytobiol 44: 143-154. |
| [53] | Kwon HM, Kang EJ, Kang K, et al. (2017) Combinatorial effects of an epigenetic inhibitor and ionizing radiation contribute to targeted elimination of pancreatic cancer stem cell. Oncotarget 8: 89005-89020. |



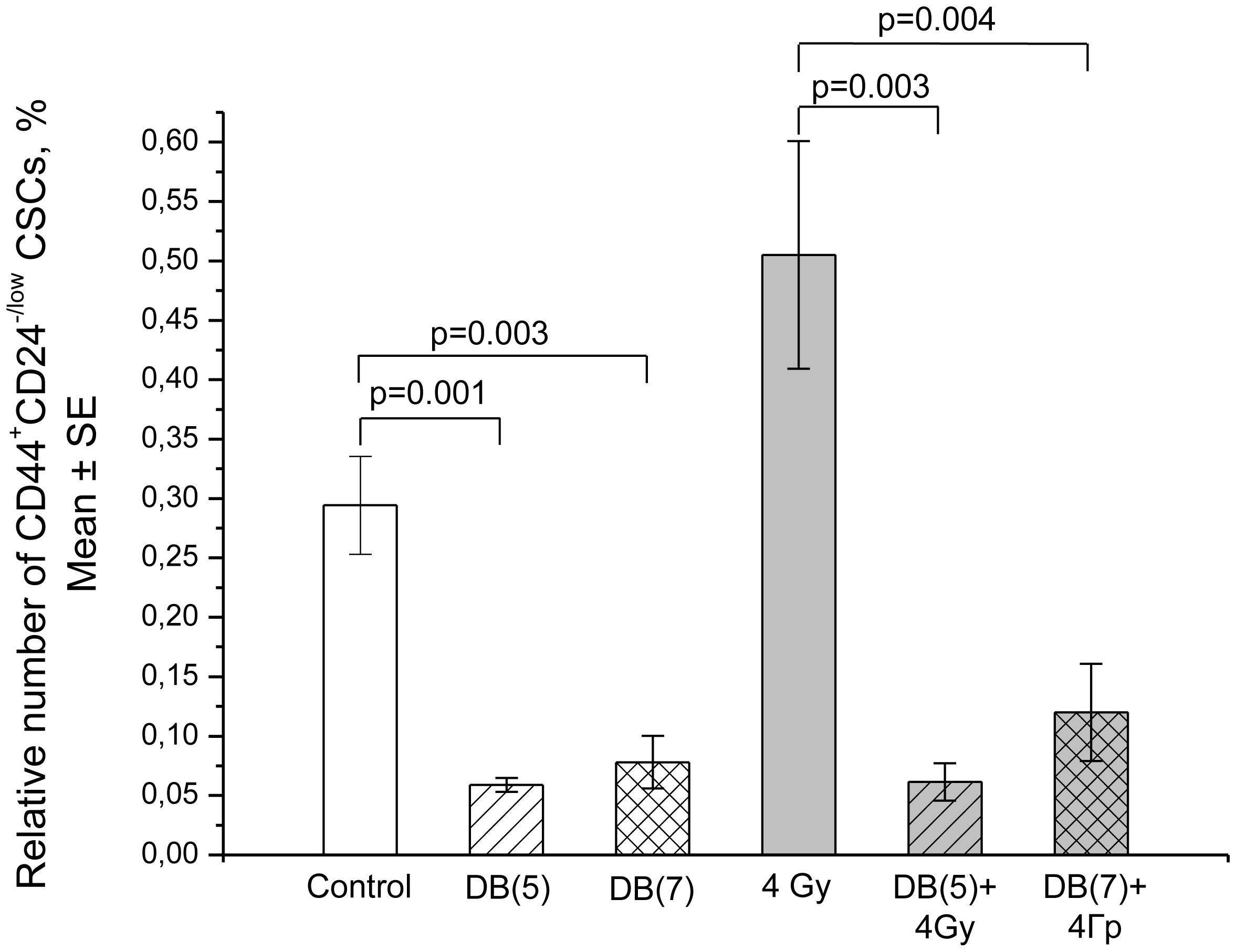
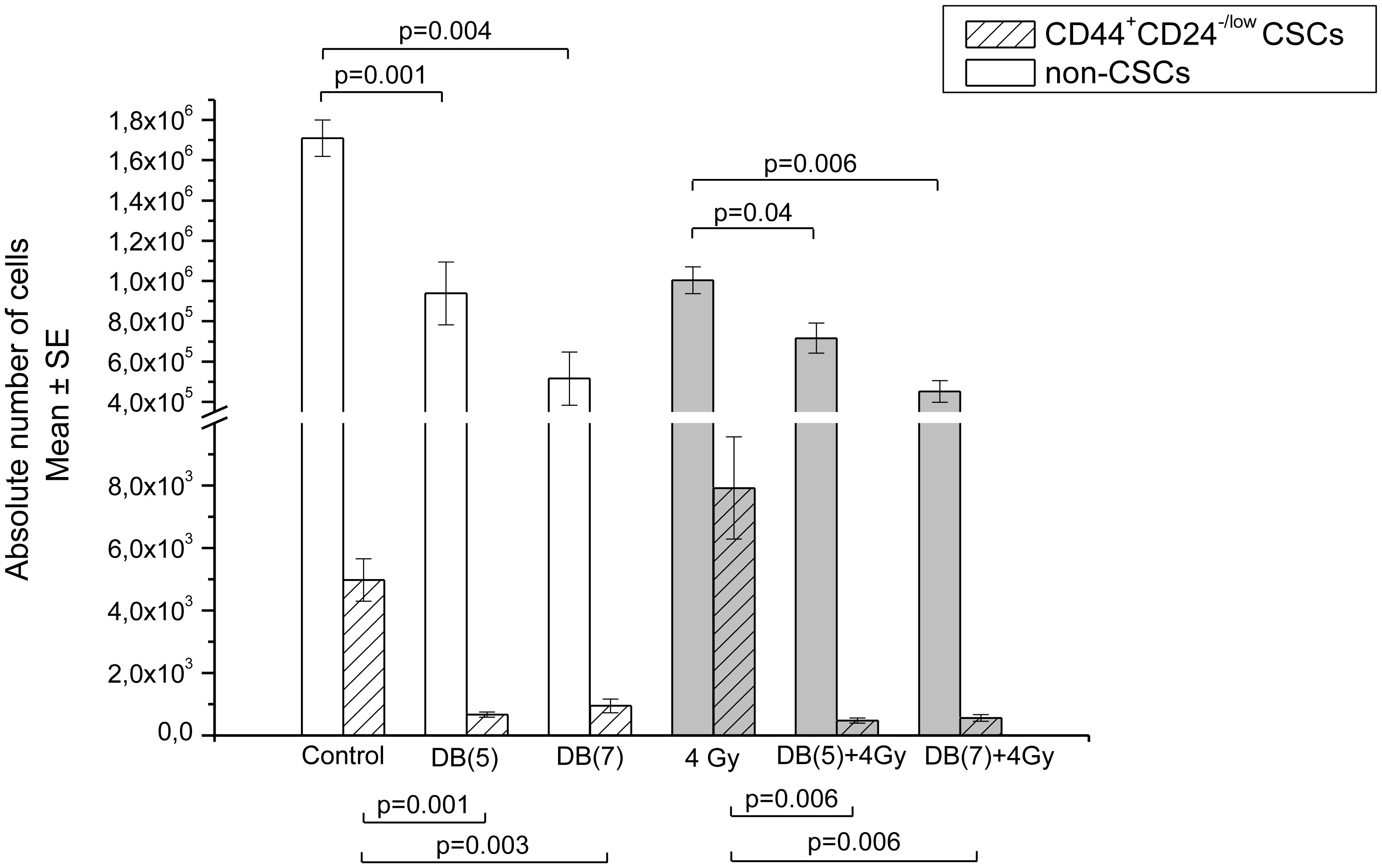
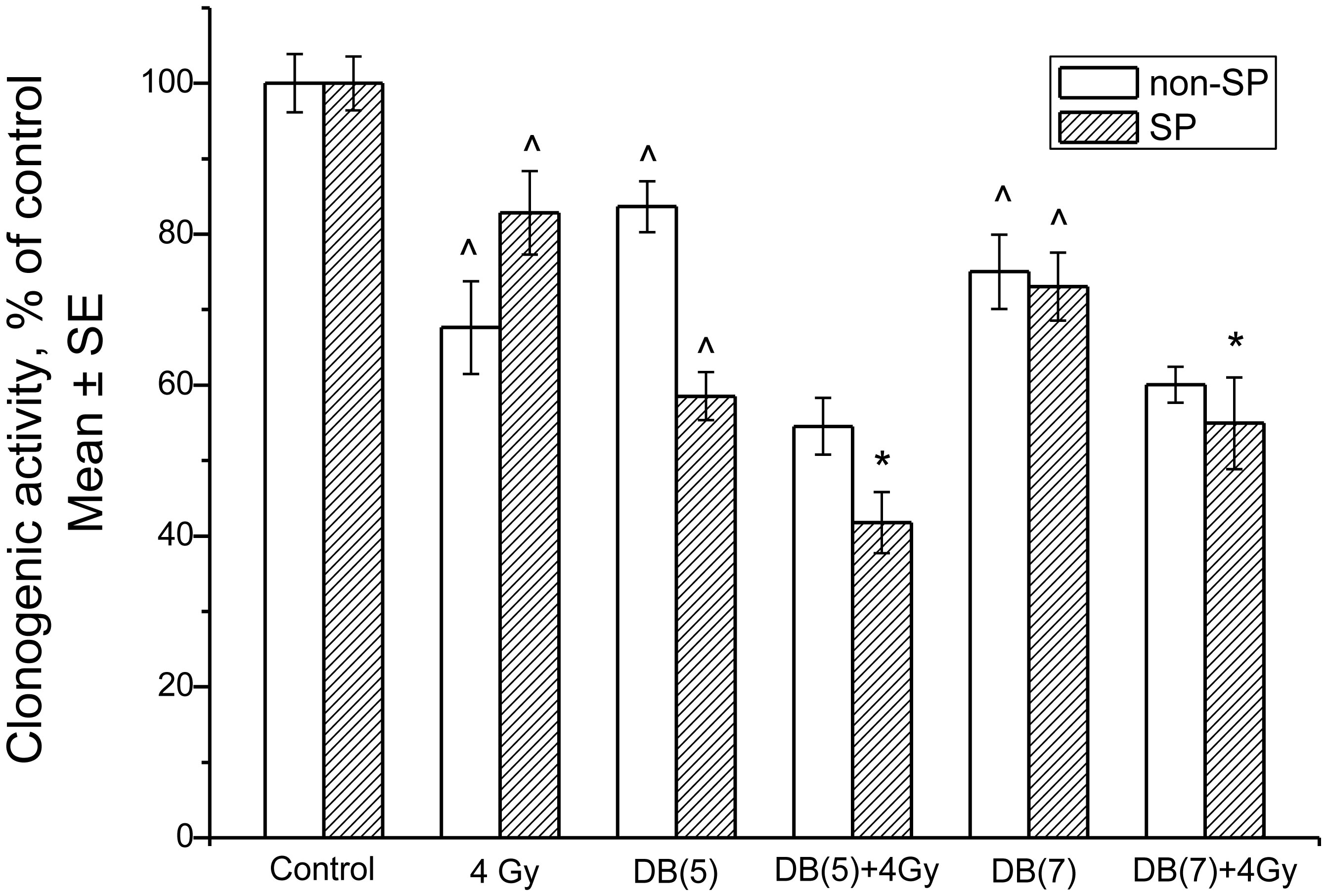

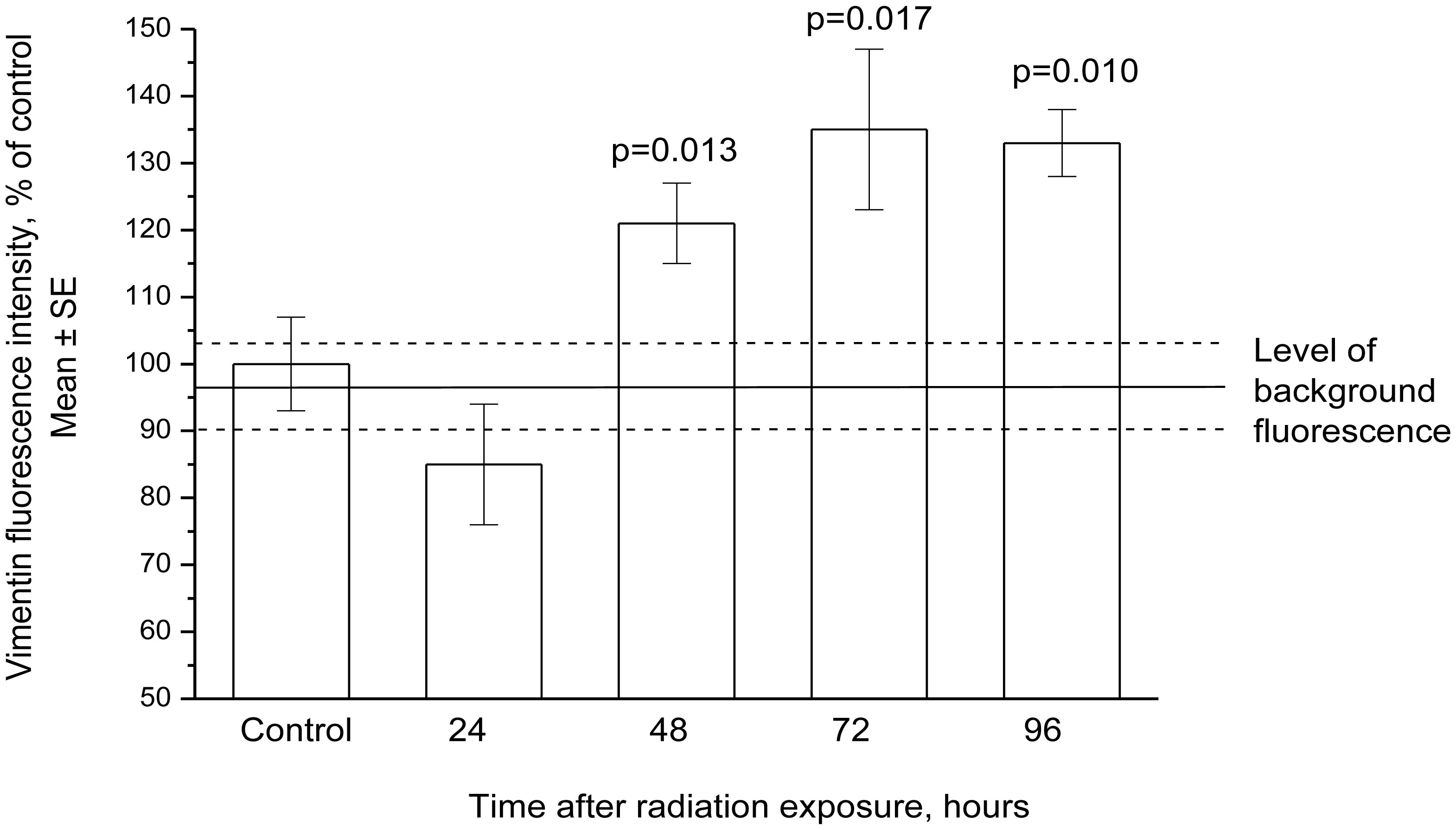
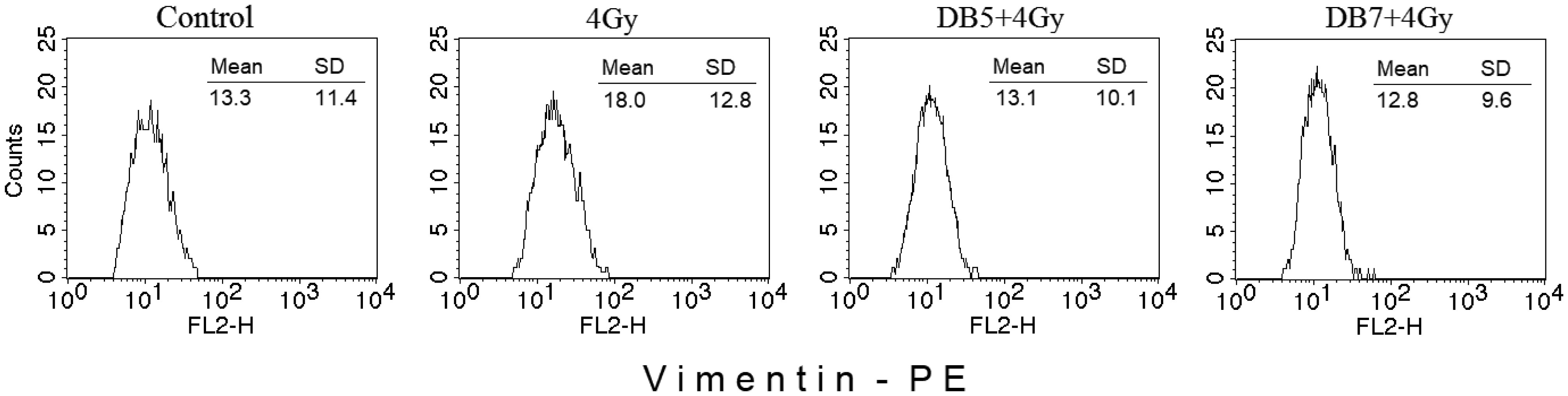
Figures(13) / Tables(3)

Irina A. Zamulaeva, Kristina A. Churyukina, Olga N. Matchuk, Alexander A. Ivanov, Vyacheslav O. Saburov, Alexei L. Zhuze. Dimeric bisbenzimidazoles DB(n) in combination with ionizing radiation decrease number and clonogenic activity of MCF-7 breast cancer stem cells[J]. AIMS Biophysics, 2020, 7(4): 339-361. doi: 10.3934/biophy.2020024







 DownLoad:
DownLoad: