Citation: Oleg S. Sukharev. Structural analysis of income and risk dynamics in models of economic growth[J]. Quantitative Finance and Economics, 2020, 4(1): 1-18. doi: 10.3934/QFE.2020001

| [1] |
Aguirre A (2017) Contracting institutions and economic growth. Rev Econ Dyn 24: 192-217. doi: 10.1016/j.red.2017.01.009

|
| [2] |
Ahmad M (2017) Economic growth and convergence: Do institutional proximity and spillovers matter? J Policy Model 39: 1065-1085. doi: 10.1016/j.jpolmod.2017.07.001
|
| [3] |
Alonso-Carrera J, Raurich X (2018) Labor mobility, structural change and economic growth. J Macroecon 56: 292-310. doi: 10.1016/j.jmacro.2018.03.002
|
| [4] |
Brondino G (2019) Productivity growth and structural change in China (1995-2009): A subsystems analysis. Struct Change Econ Dyn 49: 183-191. doi: 10.1016/j.strueco.2018.09.001
|
| [5] |
Brancaccio E, Garbellini N, Giammetti R (2018) Structural labour market reforms, GDP growth and the functional distribution of income. Struct Change Econ Dyn 44: 34-45. doi: 10.1016/j.strueco.2017.09.001
|
| [6] |
Cutrini E (2019) Economic integration, structural change, and uneven development in the European Union. Struct Change Econ Dyn 50: 102-113. doi: 10.1016/j.strueco.2019.06.007
|
| [7] |
Davanzati GF (2018) Structural change driven by institutions: Thorstein Veblen revised. Struct Change Econ Dyn 45: 105-110. doi: 10.1016/j.strueco.2018.03.002
|
| [8] |
Freire C (2019) Economic diversification: A model of structural economic dynamics and endogenous technological change. Struct Change Econ Dyn 49: 13-28. doi: 10.1016/j.strueco.2019.03.005
|
| [9] |
Gabardo FA, Pereima JB, Einloft P (2017) The incorporation of structural change into growth theory: A historical appraisal. EconomiA 18: 392-410. doi: 10.1016/j.econ.2017.05.003
|
| [10] | Hanusch H, Chakraborty L, Khurana S (2017) Fiscal Policy Economic Growth and Innovation: An Empirical Analysis of G20 Countries. Levy Economics Institute, Working Paper, No. 883, 16. |
| [11] |
Iamsiraroj S (2016) The foreign direct investment-economic growth nexus. Int Rev Econ Financ 42: 116-133. doi: 10.1016/j.iref.2015.10.044
|
| [12] |
North DC (1989) Institutions and economic growth: An historical introduction. World Development 17: 1319-1332. doi: 10.1016/0305-750X(89)90075-2
|
| [13] |
Pi J, Zhang P (2018) Structural change and wage inequality. Int Rev Econ Financ 58: 699-707. doi: 10.1016/j.iref.2018.07.010
|
| [14] | Ravindran A, Ragsdell KM, Reklaitis GV (1983) Engineering optimization: methods and application, New York: Wiley, 681. |
| [15] |
Romano L, Traù F (2017) The nature of industrial development and the speed of structural change. Struct Change Econ Dyn 42: 26-37. doi: 10.1016/j.strueco.2017.05.003
|
| [16] |
Sachse K, Jungermann H, Belting JM (2012) Investment risk-The perspective of individual investors. J Econ Psychol 33: 437-447. doi: 10.1016/j.joep.2011.12.006
|
| [17] |
Samaniego RM, Sun JY (2016) Productivity growth and structural transformation. Rev Econ Dyn 21: 266-285. doi: 10.1016/j.red.2015.06.003
|
| [18] |
Saviotti P, Pyka A, Jun B (2016) Education, structural change and economic development. Struct Change Econ Dyn 38: 55-68. doi: 10.1016/j.strueco.2016.04.002
|
| [19] |
Shinzato T (2018) Maximizing and minimizing investment concentration with constraints of budget and investment risk. Phys A 490: 986-993. doi: 10.1016/j.physa.2017.08.088
|
| [20] |
Sukharev OS (2019) The restructuring of the investment portfolio: the risk and effect of the emergence of new combinations. Quant Financ Econ 3: 390-411. doi: 10.3934/QFE.2019.2.390
|
| [21] |
Vu KM (2017) Structural change and economic growth: Empirical evidence and policy insights from Asian economies. Struct Change Econ Dyn 41: 64-77. doi: 10.1016/j.strueco.2017.04.002
|
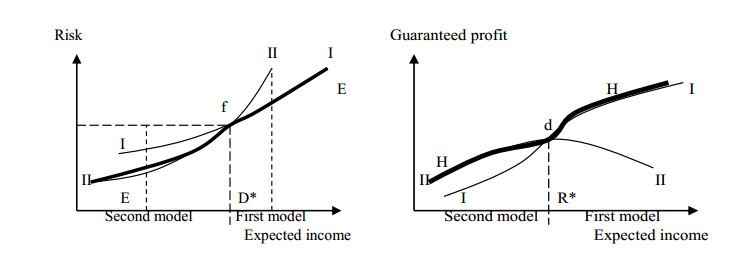
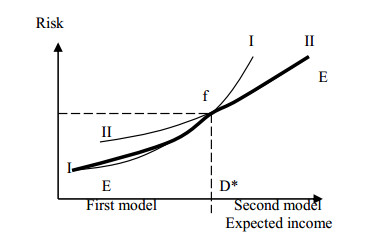


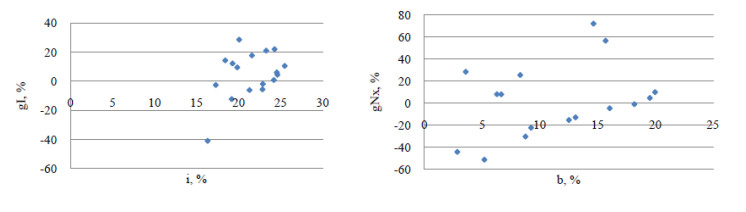
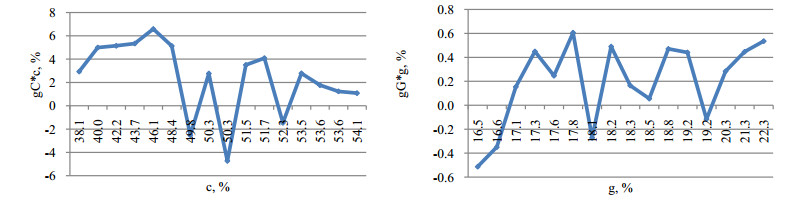
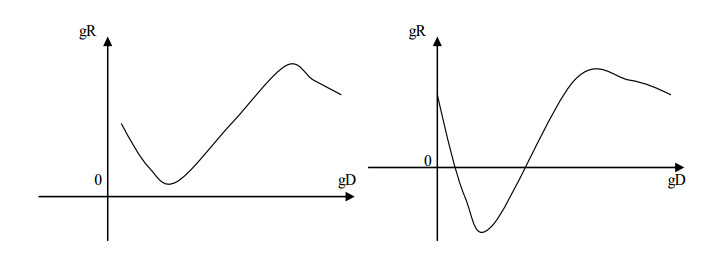
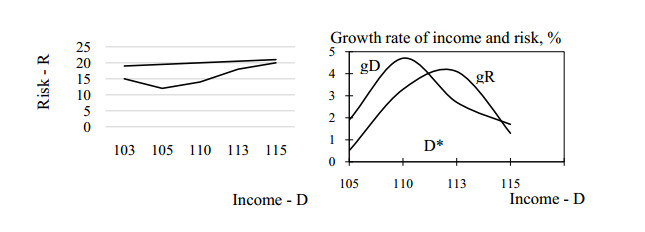
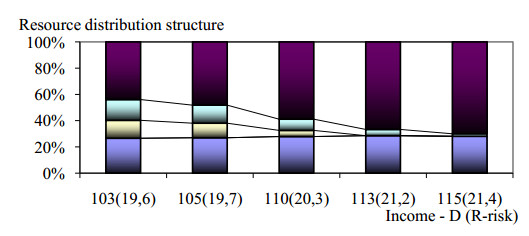
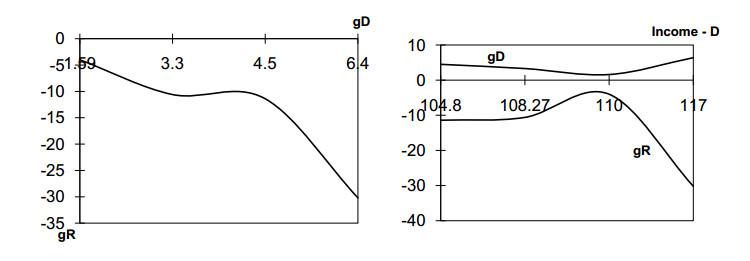
Figures(16)

Oleg S. Sukharev. Structural analysis of income and risk dynamics in models of economic growth[J]. Quantitative Finance and Economics, 2020, 4(1): 1-18. doi: 10.3934/QFE.2020001







 DownLoad:
DownLoad: