Citation: Zhongxian Men, Tony S. Wirjanto. A new variant of estimation approach to asymmetric stochastic volatilitymodel[J]. Quantitative Finance and Economics, 2018, 2(2): 325-347. doi: 10.3934/QFE.2018.2.325

| [1] |
Bollerslev T (1986) Generalized autoregressive conditional heteroskedasticity. J Econometrics 31: 307–327. doi: 10.1016/0304-4076(86)90063-1

|
| [2] |
Bauwens L, Lubrano M (1998) Bayesian inference on GARCH models using the Gibbs sampler. Economet J 1: C23–C26. doi: 10.1111/1368-423X.11003
|
| [3] |
Broto C, Ruiz E (2004) Estimation methods for stochastic volatility models: a survey. J Econ Surv 18: 613–649. doi: 10.1111/j.1467-6419.2004.00232.x
|
| [4] | Carnero A, Pena D, Ruiz E (2003) Persistence and kurtosis in GARCH and stochastic volatility models J Financ Economet 2: 319–342. |
| [5] | Chib S, Greenberg E (1995) Understanding the Metropolis-Hastings Algorithm. American Statistician 49: 327–335. |
| [6] |
Chib S, Nardarib F, Shephard N (2006) Analysis of high dimensional multivariate stochastic volatility models. J Econometrics 134: 341–371. doi: 10.1016/j.jeconom.2005.06.026
|
| [7] |
Dobigeon N, Tourneret J (2010) Bayesian orthogonal component analysis for sparse representation. IEEE T Signal Proces 58: 2675–2685. doi: 10.1109/TSP.2010.2041594
|
| [8] |
Diebold FX, Guther TA, Tay AS (1998) Evaluating density forecasts with applications to financial risk management. Int Econ Rev 39: 863–883. doi: 10.2307/2527342
|
| [9] |
Engle RF (1982) Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation. Econometrica 50: 987–1007. doi: 10.2307/1912773
|
| [10] |
Eraker B, Johannes M, Polson N (2003) The Impact ofJumps inVolatility and Returns. J Financ 58: 1269–1300. doi: 10.1111/1540-6261.00566
|
| [11] |
Geweke J (1993) Bayesian treatment of the independent Student-t linear model. J Appl Econom 8: S19–S40. doi: 10.1002/jae.3950080504
|
| [12] | Harvey AC, Shephard N (1996) Estimation of an asymmetric stochastic volatility model for asset returns. J Bus Econ Stat 14: 42-434. |
| [13] |
Jacquier E, Polson NG, Rossi PE (2004) Bayesian analysis of stochastic volatility models with fat-tails and correlated errors. J Econometrics 122: 185–212. doi: 10.1016/j.jeconom.2003.09.001
|
| [14] |
Kawakatsu H (2007) Numerical integration-based Gaussian mixture filters for maximum likelihood estimation of asymmetric stochastic volatility models. Economet 10: 342–358. doi: 10.1111/j.1368-423X.2007.00211.x
|
| [15] |
Kim S, Shephard N, Chib S (1998) Stochastic volatility: Likelihood inference and comparison with ARCH models. Rev Econ Stud 65: 361–393. doi: 10.1111/1467-937X.00050
|
| [16] | Liesenfeld R, Richard J (2003) Univariate and multivariate stochastic volatility models: estimation and diagnostics. J Empiri Financ 45: 505–531. |
| [17] |
Melino A, Turnbull SM (1990) Pricing foreign currencyoptions with stochastic volatility. J Econometrics 45: 239–265. doi: 10.1016/0304-4076(90)90100-8
|
| [18] | Men Z (2012) Bayesian Inference for Stochastic Volatility Models. Ph.D. thesis, Department of Statistics and Actuarial Science at the University of Waterloo. |
| [19] |
Men Z, McLeish D, Kolkiewicz A, et al. (2017) Comparison of Asymmetric Stochastic Volatility Models under Di erent Correlation Structures. J Appl Stat 44: 1350–1368. doi: 10.1080/02664763.2016.1204596
|
| [20] |
Men Z, Kolkiewicz A, Wirjanto TS (2015) Bayesian Analysis of Asymmetric Stochastic Conditional Duration Model. J Forecasting 34: 36–56. doi: 10.1002/for.2317
|
| [21] |
Mira A, Tierney L (2002) E ciency and Convergence Properties of Slice Samplers. Scand J Stat 29: 1–12. doi: 10.1111/1467-9469.00267
|
| [22] |
Neal RN (2003) Slice sampling. Annals Stat 31: 705–767. doi: 10.1214/aos/1056562461
|
| [23] |
Omori Y, Chib S, Shephard N, et al. (2007) Stochastic volatility with leverage: Fast and e cient likelihood inference. J Econometrics 140: 425–449. doi: 10.1016/j.jeconom.2006.07.008
|
| [24] | Pitt MK, Shephard N (1999a) Time varying covariances: A factor stochastic volatility approach. Bayesian Stat 6: 547–570. |
| [25] | Pitt M, Shephard N (1999b) Filtering via simulation: Auxiliary particle filters. J Am Stat Assoc 94: 590–599. |
| [26] |
Roberts GO, Rosenthal JS (1999) Convergence of Slice Sampler Markov Chains. J R Stat Soc B 61: 643–660. doi: 10.1111/1467-9868.00198
|
| [27] |
Shephard N, Pitt MK (1997) Likelihood Analysis of non-Gaussian Measurement Time Series. Biometrika 84: 653–667. doi: 10.1093/biomet/84.3.653
|
| [28] | Taylor SJ (1986) Modelling Financial Time Series, Chichester: Wiley. |
| [29] |
Wirjanto TS, Kolkiewicz A, Men Z (2016) Bayesian Analysis of a Threshold Stochastic Volatility Model. J Forecasting 35: 462–476. doi: 10.1002/for.2397
|
| [30] |
Yu J (2005) On leverage in a stochastic volatility model. J Econometrics 127: 165–178. doi: 10.1016/j.jeconom.2004.08.002
|
| [31] | Yu J, Meyer R (2006) Multivariate stochastic volatility models: Bayesian estimation and model comparison. Economet Rev 51: 2218–2231. |
| [32] |
Zhang X, King L (2008) Box-Cox stochastic volatility models with heavy-tails and correlated errors. J Empiri Financ 15: 549–566. doi: 10.1016/j.jempfin.2007.05.002
|
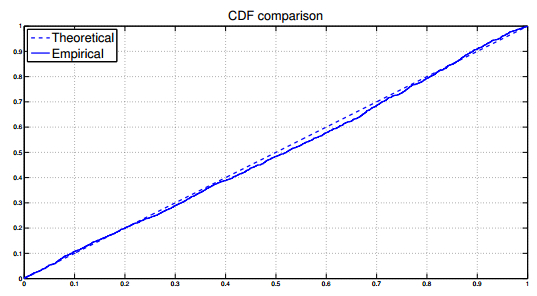
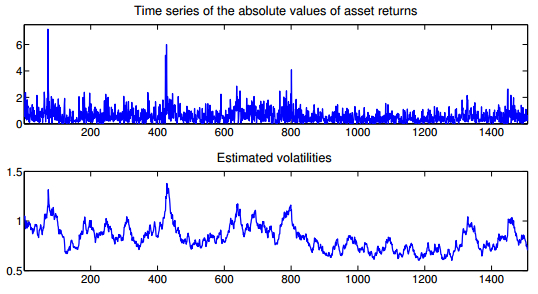
Figures(10) / Tables(4)

Zhongxian Men, Tony S. Wirjanto. A new variant of estimation approach to asymmetric stochastic volatilitymodel







 DownLoad:
DownLoad: