Citation: Donatien Hainaut. Continuous Mixed-Laplace Jump Diffusion Models for Stocks and Commodities[J]. Quantitative Finance and Economics, 2017, 1(2): 145-173. doi: 10.3934/QFE.2017.2.145

| [1] |
Bessembinder, Hendrik, et al. (1995) Mean Reversion in Equilibrium Asset Prices: Evidence from the Futures Term Structure. J Finance 50: 361-75. doi: 10.1111/j.1540-6261.1995.tb05178.x

|
| [2] |
Levendorskii SZ (2004) Pricing of the American Put Under Lévy Processes. Int J Theor Appl Finance 7: 303-336. doi: 10.1142/S0219024904002463
|
| [3] | Boyarchenko SI, Levendorskii SZ (2002) Barrier Options and Touch-and-Out Options Under Regular Lévy Processes of Exponential Type. Ann Appl Probab 12: 1261-1298. |
| [4] |
Barndorff-Nielsen OE, Shephard N (2001) Non Gaussian Ornstein-Uhlenbeck Based Models and Some of Their Uses in Financial Economics. J R Stat Soc, Ser B, 63: 167-241. doi: 10.1111/1467-9868.00282
|
| [5] |
Cortazar G, Schwartz E (1994) The Valuation of Commodity Contingent Claims. J Deriv 1: 27-29. doi: 10.3905/jod.1994.407896
|
| [6] | Davies B (2002) Integr Transforms Their Appl, 3 Ed., Springer. |
| [7] |
Eberlein E, Raible S (1999) Term Structure Models Driven by General Lévy Processes. Math Finance 9: 31-53. doi: 10.1111/1467-9965.00062
|
| [8] |
Gibson R, Schwartz E (1990) Stochastic Convenience Yield and the Pricing of Oil Contingent Claims. J Finance 45: 959-976. doi: 10.1111/j.1540-6261.1990.tb05114.x
|
| [9] |
Hainaut D, Le Courtois O (2014) An Intensity Model for Credit Risk with Switching Lévy Processes. Quant Finance 14: 1453-1465. doi: 10.1080/14697688.2012.756583
|
| [10] | Hainaut D, Colwell D (2016) a. A Structural Model for Credit Risk with Switching Processes and Synchronous Jumps. Eur J Finance 22: 1040-1062. |
| [11] | Hainaut D (2016) b. Clustered Lévy Processes and Their Financial Applications. SSRN Working Paper. |
| [12] | Heyde CC (2000) A Risky Asset Model With Strong Dependence Through Fractal Activity Time. J Appl Probab 36: 1234-1239. |
| [13] | Jackson KR, Jaimungal S, Surkov V (2008) Fourier Space Time-Stepping for Option Pricing With Levy Models. J Comput Finance 12: 1-29. |
| [14] |
Jaimungal KR, Surkov V (2011) Levy Based Cross-Commodity Models and Derivative Valuation. SIAM J Financ Math 2: 464-487. doi: 10.1137/100791609
|
| [15] | Kaas R, Goovaerts M, Dhaene J, Denuit M (2008) Mod Actuar Risk Theory, Using R, 2 Ed., Springer. |
| [16] |
Kou SG (2002) A Jump Diffusion Model for Option Pricing. Manage Sci 48: 1086-1101. doi: 10.1287/mnsc.48.8.1086.166
|
| [17] |
Kou SG, Wang H (2003) First Passage Times of a Jump Diffusion Process. Adv Appl Probab 35: 504-531. doi: 10.1017/S0001867800012350
|
| [18] |
Kou SG,Wang H (2004) Option Pricing Under a Double Exponential Jump Diffusion Model. Manage Sci 50: 1178-1192. doi: 10.1287/mnsc.1030.0163
|
| [19] |
Cai N, Kou SG (2011) Option Pricing Under a Mixed-Exponential Jump Diffusion Model. Manage Sci 57: 2067-2081. doi: 10.1287/mnsc.1110.1393
|
| [20] | Lipton A (2002) Assets With Jumps. Risk, September, 149-153. |
| [21] |
Madan DB, Seneta E (1990) The Variance Gamma Model for Share Market Returns. J Bus 63: 511-524. doi: 10.1086/296519
|
| [22] |
Merton RC (1976) Option Pricing When Underlying Stock Returns are Discontinuous. J Financ Econ 3: 125-144. doi: 10.1016/0304-405X(76)90022-2
|
| [23] |
Schwartz E (1997) The Stochastic Behavior of Commodity Prices: Implications for Valuation and Hedging. J Finance 52: 923-973. doi: 10.1111/j.1540-6261.1997.tb02721.x
|
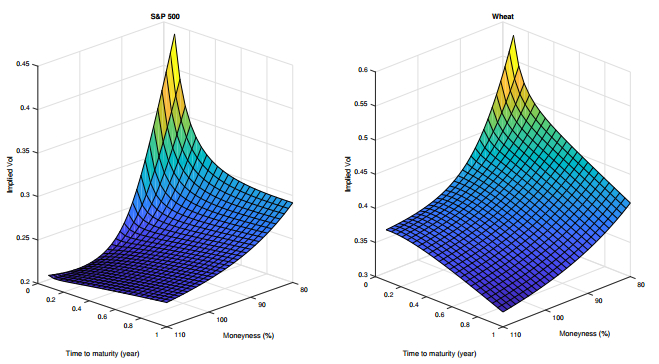
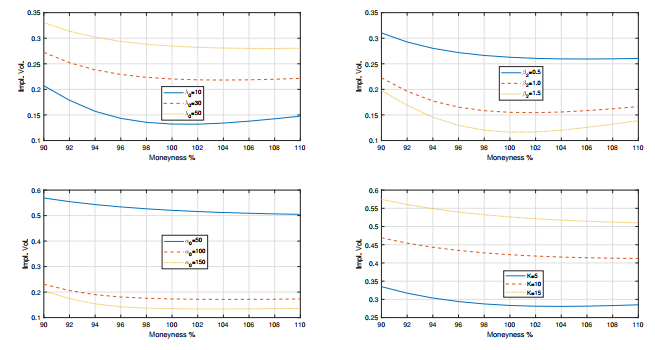
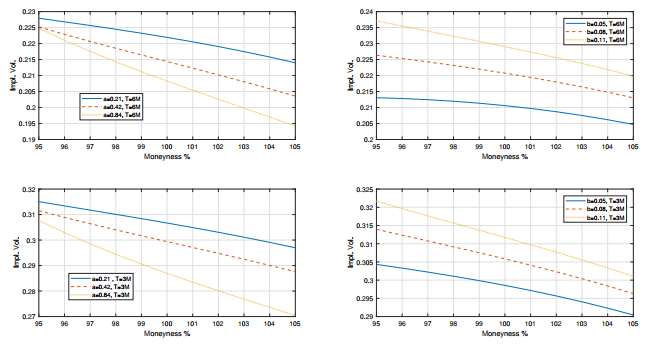
Figures(3) / Tables(4)

Donatien Hainaut. Continuous Mixed-Laplace Jump Diffusion Models for Stocks and Commodities[J]. Quantitative Finance and Economics, 2017, 1(2): 145-173. doi: 10.3934/QFE.2017.2.145







 DownLoad:
DownLoad: