Citation: Araya Ranok, Chanida Kupradit. Effect of whey protein and riceberry flour on quality and antioxidant activity under gastrointestinal transit of gluten-free cookies[J]. AIMS Agriculture and Food, 2020, 5(3): 434-448. doi: 10.3934/agrfood.2020.3.434

| [1] |
Tumbas Saponjac V, Cetkovic G, Canadanovic-Brunet J, et al. (2016) Sour cherry pomace extract encapsulated in whey and soy proteins: Incorporation in cookies. Food Chem 207: 27-33. doi: 10.1016/j.foodchem.2016.03.082

|
| [2] |
Reilly NR, Green PHR (2012) Epidemiology and clinical presentations of celiac disease. Semin Immunopathol 34: 473-478. doi: 10.1007/s00281-012-0311-2
|
| [3] |
Marcoa C, Rosell C (2008) Effect of different protein isolate and transglutaminase on rice flour properties. J Food Eng 84: 132-139. doi: 10.1016/j.jfoodeng.2007.05.003
|
| [4] |
Leardkamolkarn V, Thongthep W, Suttiarporn P, et al. (2011) Chemopreventive properties of the bran extracted from a newly-developed Thai rice: The Riceberry. Food Chem 125: 978-985. doi: 10.1016/j.foodchem.2010.09.093
|
| [5] |
Min SW, Ryu SN, Kim DH (2010) Anti-inflammatory effects of black rice, cyanidin-3-O-β-d-glycoside, and its metabolites, cyanidin and protocatechuic acid. Int Immunopharmacol 10: 959-966. doi: 10.1016/j.intimp.2010.05.009
|
| [6] |
Chiang AN, Wu HL, Yeh HI, et al. (2006) Antioxidant effects of black rice extract through the induction of superoxide dismutase and catalase activities. Lipids 41: 797-803. doi: 10.1007/s11745-006-5033-6
|
| [7] |
Yawadio R, Tanimori S, Morita N (2007) Identification of phenolic compounds isolated from pigmented rice and their aldose reductase inhibitory activities. Food Chem 101: 1616-1625. doi: 10.1016/j.foodchem.2006.04.016
|
| [8] | Klunklin W, Savage G (2018) Biscuits: A Substitution of Wheat Flour with Purple Rice Flour. Adv Food Sci Eng 2: 81-97. |
| [9] | Parate V, Dilip J, Kawadkar K, et al. (2011) Study of Whey Protein Concentrate Fortification in Cookies Variety Biscuits. Int J Food Eng 7: 1-12. |
| [10] |
Gani A, Broadway AA, Ahmad M, et al. (2015) Effect of whey and casein protein hydrolysates on rheological, textural and sensory properties of cookies. J Food Sci Technol 52: 5718-5726. doi: 10.1007/s13197-014-1649-3
|
| [11] | Tamime AY, Robinson RK (2007) Tamime and Robinson's Yoghurt: Science and Technology: Third Edition, 1-791. |
| [12] |
Peng X, Kong B, Xia X, et al. (2010) Reducing and radical-scavenging activities of whey protein hydrolysates prepared with Alcalase. Int Dairy J 20: 360-365. doi: 10.1016/j.idairyj.2009.11.019
|
| [13] |
Lin S, Tian W, Li H, et al. (2012) Improving antioxidant activities of whey protein hydrolysates obtained by thermal preheat treatment of pepsin, trypsin, alcalase and flavourzyme. Int J Food Sci 47: 1-7. doi: 10.1111/j.1365-2621.2011.02800.x
|
| [14] |
Secchi N, Stara G, Anedda R, et al. (2011) Effectiveness of sweet ovine whey powder in increasing the shelf life of Amaretti cookies. LWT-Food Sci Technol 44: 1073-1078. doi: 10.1016/j.lwt.2010.09.018
|
| [15] |
Pareyt B, Delcour JA (2008) The role of wheat flour constituents, sugar, and fat in low moisture cereal based products: a review on sugar-snap cookies. Crit Rev Food Sci Nutr 48: 824-839. doi: 10.1080/10408390701719223
|
| [16] |
Matthäus B (2002) Antioxidant Activity of Extracts Obtained from Residues of Different Oilseeds. J Agric Food Chem 50: 3444-3452. doi: 10.1021/jf011440s
|
| [17] |
Karladee D, Suriyong S (2012) γ-Aminobutyric acid (GABA) content in different varieties of brown rice during germination. ScienceAsia 38: 13-17. doi: 10.2306/scienceasia1513-1874.2012.38.013
|
| [18] |
Helal A, Tagliazucchi D (2018) Impact of in-vitro gastro-pancreatic digestion on polyphenols and cinnamaldehyde bioaccessibility and antioxidant activity in stirred cinnamon-fortified yogurt. LWT-Food Sci Technol 89: 164-170. doi: 10.1016/j.lwt.2017.10.047
|
| [19] |
Adler-Nissen J (1979) Determination of the degree of hydrolysis of food protein hydrolysates by trinitrobenzenesulfonic acid. J Agric Food Chem 27: 1256-1262. doi: 10.1021/jf60226a042
|
| [20] |
Wiriyaphan C, Chitsomboon B, Yongsawadigul J (2012) Antioxidant activity of protein hydrolysates derived from threadfin bream surimi byproducts. Food Chem 132: 104-111. doi: 10.1016/j.foodchem.2011.10.040
|
| [21] |
Conway V, Gauthier SF, Pouliot Y (2013) Antioxidant activities of buttermilk proteins, whey proteins, and their enzymatic hydrolysates. J Agric Food Chem 61: 364-372. doi: 10.1021/jf304309g
|
| [22] |
Sompong R, Siebenhandl-Ehn S, Linsberger-Martin G, et al. (2011) Physicochemical and antioxidative properties of red and black rice varieties from Thailand, China and Sri Lanka. Food Chem 124: 132-140. doi: 10.1016/j.foodchem.2010.05.115
|
| [23] |
Jiamyangyuen S, Nuengchamnong N, Ngamdee P (2017) Bioactivity and chemical components of Thai rice in five stages of grain development. J Cereal Sci 74: 136-144. doi: 10.1016/j.jcs.2017.01.021
|
| [24] | Settapramote N, Laokuldilok T, Boonyawan D, et al. (2018) Physiochemical, Antioxidant Activities and Anthocyanin of Riceberry Rice from Different Locations in Thailand. Fab J 6: 84-94. |
| [25] | Thao N, Niwat C (2017) Effect of Germinated Colored Rice on Bioactive Compounds and Quality of Fresh Germinated Colored Rice Noodle. KMUTNB: IJAST 11: 27-37. |
| [26] |
Mau JL, Lee CC, Chen YP, et al. (2017) Physicochemical, antioxidant and sensory characteristics of chiffon cake prepared with black rice as replacement for wheat flour. LWT-Food Sci Technol 75: 434-439. doi: 10.1016/j.lwt.2016.09.019
|
| [27] |
Chung HJ, Cho A, Lim ST (2014) Utilization of germinated and heat-moisture treated brown rices in sugar-snap cookies. LWT-Food Sci Technol 57: 260-266. doi: 10.1016/j.lwt.2014.01.018
|
| [28] | Mir SA, Bosco SJD, Shah MA, et al. (2017) Effect of apple pomace on quality characteristics of brown rice based cracker. J Saudi Soc 16: 25-32. |
| [29] |
Gallagher E, Gormley TR, Arendt EK (2003) Crust and crumb characteristics of gluten free breads. J Food Eng 56: 153-161. doi: 10.1016/S0260-8774(02)00244-3
|
| [30] | Sarabhai S, Indrani D, Vijaykrishnaraj M, et al. (2015) Effect of protein concentrates, emulsifiers on textural and sensory characteristics of gluten free cookies and its immunochemical validation. J Food Sci Technol 52: 3763-3772. |
| [31] |
Chung HJ, Cho A, Lim ST (2012) Effect of heat-moisture treatment for utilization of germinated brown rice in wheat noodle. LWT-Food Sci Technol 47: 342-347. doi: 10.1016/j.lwt.2012.01.029
|
| [32] |
Corrochano AR, Sariçay Y, Arranz E, et al. (2019) Comparison of antioxidant activities of bovine whey proteins before and after simulated gastrointestinal digestion. J Dairy Sci 102: 54-67. doi: 10.3168/jds.2018-14581
|
| [33] |
Shao Y, Hu Z, Yu Y, et al. (2018) Phenolic acids, anthocyanins, proanthocyanidins, antioxidant activity, minerals and their correlations in non-pigmented, red, and black rice. Food Chem 239: 733-741. doi: 10.1016/j.foodchem.2017.07.009
|
| [34] |
Kong B, Xiong YL (2006) Antioxidant Activity of Zein Hydrolysates in a Liposome System and the Possible Mode of Action. J Agric Food Chem 54: 6059-6068. doi: 10.1021/jf060632q
|
| [35] |
Elias RJ, Kellerby SS, Decker EA (2008) Antioxidant activity of proteins and peptides. Crit Rev Food Sci Nutr 48: 430-441. doi: 10.1080/10408390701425615
|
| [36] |
Março PH, Poppi RJ, Scarminio IS, et al. (2011) Investigation of the pH effect and UV radiation on kinetic degradation of anthocyanin mixtures extracted from Hibiscus acetosella. Food Chem 125: 1020-1027. doi: 10.1016/j.foodchem.2010.10.005
|
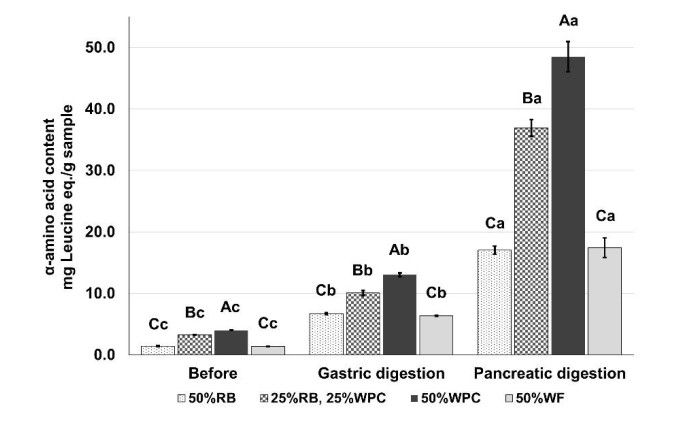
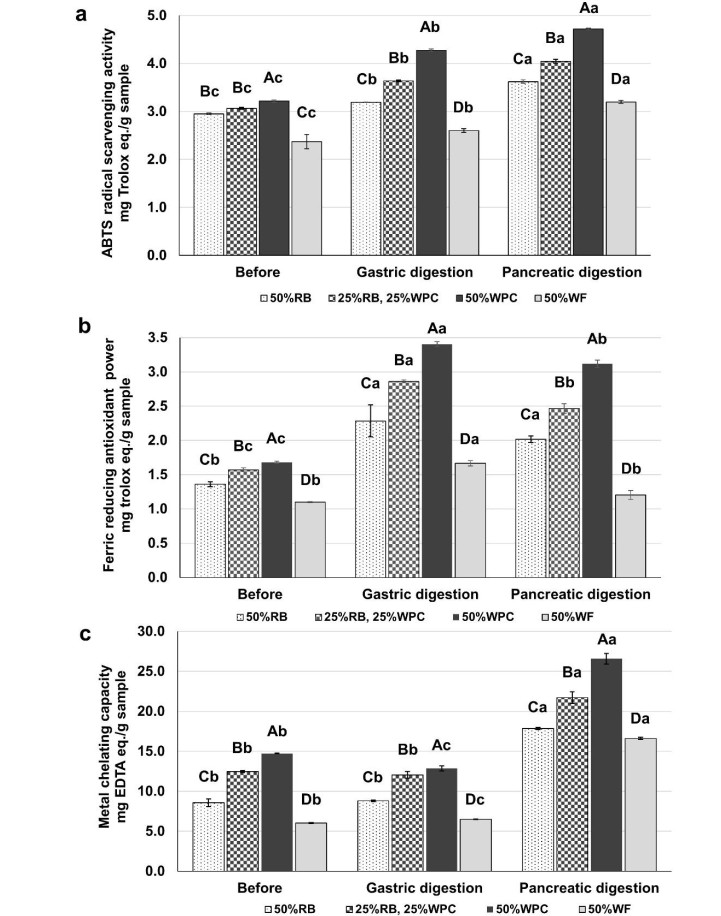
Figures(2) / Tables(3)

Araya Ranok, Chanida Kupradit. Effect of whey protein and riceberry flour on quality and antioxidant activity under gastrointestinal transit of gluten-free cookies[J]. AIMS Agriculture and Food, 2020, 5(3): 434-448. doi: 10.3934/agrfood.2020.3.434







 DownLoad:
DownLoad: