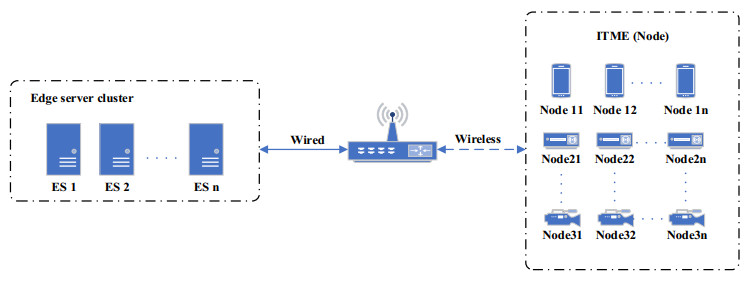
The decision-making process for computational offloading is a critical aspect of mobile edge computing, and various offloading decision strategies are strongly linked to the calculated latency and energy consumption of the mobile edge computing system. This paper proposes an offloading scheme based on an enhanced sine-cosine optimization algorithm (SCAGA) designed for the "edge-end" architecture scenario within edge computing. The research presented in this paper covers the following aspects: (1) Establishment of computational resource allocation models and computational cost models for edge computing scenarios; (2) Introduction of an enhanced sine and cosine optimization algorithm built upon the principles of Levy flight strategy sine and cosine optimization algorithms, incorporating concepts from roulette wheel selection and gene mutation commonly found in genetic algorithms; (3) Execution of simulation experiments to evaluate the SCAGA-based offloading scheme, demonstrating its ability to effectively reduce system latency and optimize offloading utility. Comparative experiments also highlight improvements in system latency, mobile user energy consumption, and offloading utility when compared to alternative offloading schemes.
Citation: Mingchang Ni, Guo Zhang, Qi Yang, Liqiong Yin. Research on MEC computing offload strategy for joint optimization of delay and energy consumption[J]. Mathematical Biosciences and Engineering, 2024, 21(6): 6336-6358. doi: 10.3934/mbe.2024276
The decision-making process for computational offloading is a critical aspect of mobile edge computing, and various offloading decision strategies are strongly linked to the calculated latency and energy consumption of the mobile edge computing system. This paper proposes an offloading scheme based on an enhanced sine-cosine optimization algorithm (SCAGA) designed for the "edge-end" architecture scenario within edge computing. The research presented in this paper covers the following aspects: (1) Establishment of computational resource allocation models and computational cost models for edge computing scenarios; (2) Introduction of an enhanced sine and cosine optimization algorithm built upon the principles of Levy flight strategy sine and cosine optimization algorithms, incorporating concepts from roulette wheel selection and gene mutation commonly found in genetic algorithms; (3) Execution of simulation experiments to evaluate the SCAGA-based offloading scheme, demonstrating its ability to effectively reduce system latency and optimize offloading utility. Comparative experiments also highlight improvements in system latency, mobile user energy consumption, and offloading utility when compared to alternative offloading schemes.

| [1] |
D. Huang, L. Yu, J. Chen, T. Wei, Research on joint computation offloading and resource allocation strategy for mobile edge computing, J. East China Normal Univ., 2021 (2021), 88–99. https://doi.org/10.3969/j.issn.1000-5641.2021.06.010 doi: 10.3969/j.issn.1000-5641.2021.06.010

|
| [2] |
T. X. Tran, D. Pompili, Joint task offloading and resource allocation for multi-server mobile-edge computing networks, IEEE Trans. Veh. Technol., 68 (2018), 856–868. https://doi.org/10.1109/TVT.2018.2881191 doi: 10.1109/TVT.2018.2881191
|
| [3] |
L. Tang, Y. J. Hu, T. Liu, Q. B. Chen, Task offloading and resource allocation algorithm based on Lyapunov in mobile edge computing, Comput. Eng., 47 (2021), 29–36. https://doi.org/10.19678/j.issn.1000-3428.0058268 doi: 10.19678/j.issn.1000-3428.0058268
|
| [4] |
B. Wu, J. Zeng, L. Ge, X. Su, Y. Tang, Energy-latency aware offloading for hierarchical mobile edge computing, IEEE Access, 7 (2019), 121982–121997. https://doi.org/10.1109/ACCESS.2019.2938186 doi: 10.1109/ACCESS.2019.2938186
|
| [5] |
M. Hu, Z. Xie, D. Wu, Y. Zhou, X. Chen, L. Xiao, Heterogeneous edge offloading with incomplete information: A minority game approach, IEEE Trans. Parallel Distrib. Syst., 31 (2020), 2139–2154. https://doi.org/10.1109/TPDS.2020.2988161 doi: 10.1109/TPDS.2020.2988161
|
| [6] |
J. S. Zheng, X. L. Jia, Double-auction-based task offloading and resource allocation strategy for mobile edge computing, Comput. Syst. Appl., 32 (2023), 45–56. https://doi.org/10.15888/j.cnki.csa.009110 doi: 10.15888/j.cnki.csa.009110
|
| [7] |
X. J. Zang, W. G. Wu, C. Zhang, Y. X. Chai, S. Y. Yang, X. Wang, Energy-efficient computing offloading algorithm for mobile edge computing network, J. Software, 34 (2023), 849–867. https://doi.org/10.13328/j.cnki.jos.006417 doi: 10.13328/j.cnki.jos.006417
|
| [8] |
H. Meng, R. Huo, Q. Y. Guo, T. Huang, Y. J. Liu, Machine learning-based stochastic task offloading algorithm in mobile-edge computing, J. Beijing Univ. Posts Telecommun., 42 (2019), 25–30. https://doi.org/10.13190/j.jbupt.2018-078 doi: 10.13190/j.jbupt.2018-078
|
| [9] |
X. Qiu, L. Liu, W. Chen, Z. Hong, Z. Zheng, Online deep reinforcement learning for computation offloading in blockchain-empowered mobile edge computing, IEEE Trans. Veh. Technol., 68 (2019), 8050–8062. https://doi.org/10.1109/TVT.2019.2924015 doi: 10.1109/TVT.2019.2924015
|
| [10] |
S. F. Zhu, M. Y. Zhao, Z. Y. Chai, Computing offloading scheme based on particle swarm optimization algorithm in edge computing scene, J. Jilin Univ., 52 (2022), 2698–2705. https://doi.org/10.13229/j.cnki.jdxbgxb20210328 doi: 10.13229/j.cnki.jdxbgxb20210328
|
| [11] |
Y. L. Cong, W. X. Sun, K. Xue, Z. H. Qian, M. S. Chen, Research on task offloading strategy of Internet of vehicles based on improved hybrid genetic algorithm, J. Commun., 43 (2022), 77–85. https://doi.org/10.11959/j.issn.1000-436x.2022188 doi: 10.11959/j.issn.1000-436x.2022188
|
| [12] |
Z. X. Yang, W. Z. Zhang, P. Cheng, S. H. Xie, Computation offloading decision strategy based on hybrid fruit fly optimization algorithm, J. Chinese Comput. Syst., 44 (2023), 1290–1296. https://doi.org/10.20009/j.cnki.21-1106/TP.2021-0749 doi: 10.20009/j.cnki.21-1106/TP.2021-0749
|
| [13] |
S. Chauhan, G. Vashishtha, L. Abualigah, A. Kumar, Boosting salp swarm algorithm by opposition-based learning concept and sine cosine algorithm for engineering design problems, Soft Comput., 2023 (2023), 1–28. https://doi.org/10.1007/s00500-023-09147-z doi: 10.1007/s00500-023-09147-z
|
| [14] |
M. Zhong, J. Wen, J. Ma, H. Cui, Q. Zhang, M. K. Parizi, A hierarchical multi-leadership sine cosine algorithm to dissolving global optimization and data classification: The COVID-19 case study, Comput. Biol. Med., 164 (2023), 107212. https://doi.org/10.1016/j.compbiomed.2023.107212 doi: 10.1016/j.compbiomed.2023.107212
|
| [15] |
S. Raj, C. K. Shiva, B. Vedik, S. Mahapatra, V. Mukherjee, A novel chaotic chimp sine cosine algorithm Part-Ⅰ: For solving optimization problem, Chaos Solitons Fractals, 173 (2023), 113672. https://doi.org/10.1016/j.chaos.2023.113672 doi: 10.1016/j.chaos.2023.113672
|
| [16] | K. Paul, D. Hati, A novel hybrid Harris hawk optimization and sine cosine algorithm based home energy management system for residential buildings, Building Serv. Eng. Res. Technol., 2023 (2023), 01436244231170387. |
| [17] |
S. K. Gupta, M. K. Kar, L. Kumar, S. Kumar, A simplified sine cosine algorithm for the solution of optimal reactive power dispatch, Int. Trans. Electr. Energy Syst., 2022 (2022). https://doi.org/10.1155/2022/2165966 doi: 10.1155/2022/2165966
|
| [18] |
C. D. Patel, T. K. Tailor, Multi-agent based sine–cosine algorithm for optimal integration of DERs with consideration of existing OLTC in distribution networks, Appl. Soft Comput., 117 (2022), 108387. https://doi.org/10.1016/j.asoc.2021.108387 doi: 10.1016/j.asoc.2021.108387
|
| [19] |
J. Cheng, Z. Feng, Y. Xiong, Transformer fault diagnosis based on an improved sine cosine algorithm and BP neural network, Recent Adv. Electr. Electron. Eng., 15 (2022), 502–510. https://doi.org/10.2174/2352096515666220819141443 doi: 10.2174/2352096515666220819141443
|
| [20] |
S. Karimulla, K. Ravi. Solving multi objective power flow problem using enhanced sine cosine algorithm, Ain Shams Eng. J., 12 (2021), 3803–3817. https://doi.org/10.1016/j.asej.2021.02.037 doi: 10.1016/j.asej.2021.02.037
|
| [21] |
W. Y. Guo, Y. Wang, F. Dai, T. Liu, Alternating sine cosine algorithm based on elite chaotic search strategy, Control Decis., 34 (2019), 1654–1662. https://doi.org/10.13195/j.kzyjc.2018.0006 doi: 10.13195/j.kzyjc.2018.0006
|
| [22] | 3GPP Technical Specification Group Radio Access Network, Further advancements for E-UTRA physical layer aspects (Release 9), 3GPP TR 36.814 V9.0.0, 2010. Available from: https://documents.pub/document/3gpp-tr-36814-v900-2010-03.html?page = 1. |










Figures(11) / Tables(5)

Mingchang Ni, Guo Zhang, Qi Yang, Liqiong Yin. Research on MEC computing offload strategy for joint optimization of delay and energy consumption[J]. Mathematical Biosciences and Engineering, 2024, 21(6): 6336-6358. doi: 10.3934/mbe.2024276







 DownLoad:
DownLoad: