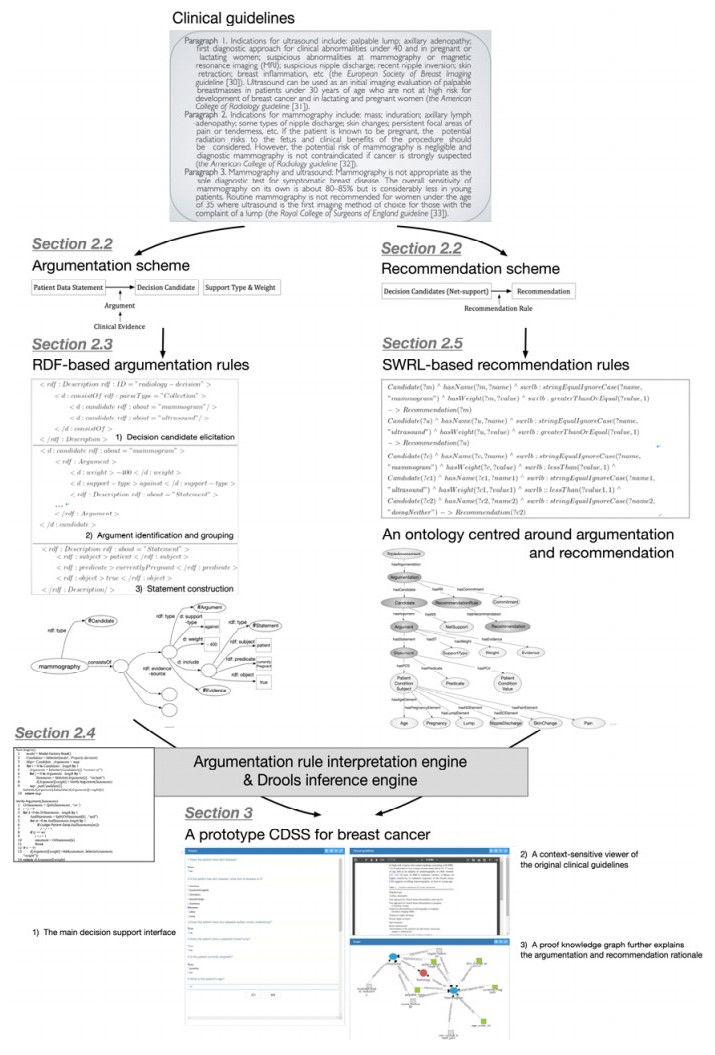
In clinical decision support, argumentation plays a key role while alternative reasons may be available to explain a given set of signs and symptoms, or alternative plans to treat a diagnosed disease. In literature, this key notion usually has closed boundary across approaches and lacks of openness and interoperability in Clinical Decision Support Systems (CDSSs) been built. In this paper, we propose a systematic approach for the representation of argumentation, their interpretation towards recommendation, and finally explanation in clinical decision support. A generic argumentation and recommendation scheme lays the foundation of the approach. On the basis of this, argumentation rules are represented using Resource Description Framework (RDF) for clinical guidelines, a rule engine developed for their interpretation, and recommendation rules represented using Semantic Web Rule Language (SWRL). A pair of proof knowledge graphs are made available in an integrated clinical decision environment to explain the argumentation and recommendation rationale, so that decision makers are informed of not just what are recommended but also why. A case study of triple assessment, a common procedure in the National Health Service of UK for women suspected of breast cancer, is used to demonstrate the feasibility of the approach. In conducting hypothesis testing, we evaluate the metrics of accuracy, variation, adherence, time, satisfaction, confidence, learning, and integration of the prototype CDSS developed for the case study in comparison with a conventional CDSS and also human clinicians without CDSS. The results are presented and discussed.
Citation: Liang Xiao, Hao Zhou, John Fox. Towards a systematic approach for argumentation, recommendation, and explanation in clinical decision support[J]. Mathematical Biosciences and Engineering, 2022, 19(10): 10445-10473. doi: 10.3934/mbe.2022489
In clinical decision support, argumentation plays a key role while alternative reasons may be available to explain a given set of signs and symptoms, or alternative plans to treat a diagnosed disease. In literature, this key notion usually has closed boundary across approaches and lacks of openness and interoperability in Clinical Decision Support Systems (CDSSs) been built. In this paper, we propose a systematic approach for the representation of argumentation, their interpretation towards recommendation, and finally explanation in clinical decision support. A generic argumentation and recommendation scheme lays the foundation of the approach. On the basis of this, argumentation rules are represented using Resource Description Framework (RDF) for clinical guidelines, a rule engine developed for their interpretation, and recommendation rules represented using Semantic Web Rule Language (SWRL). A pair of proof knowledge graphs are made available in an integrated clinical decision environment to explain the argumentation and recommendation rationale, so that decision makers are informed of not just what are recommended but also why. A case study of triple assessment, a common procedure in the National Health Service of UK for women suspected of breast cancer, is used to demonstrate the feasibility of the approach. In conducting hypothesis testing, we evaluate the metrics of accuracy, variation, adherence, time, satisfaction, confidence, learning, and integration of the prototype CDSS developed for the case study in comparison with a conventional CDSS and also human clinicians without CDSS. The results are presented and discussed.

| [1] |
J. Y. Yang, L. Xiao, K. N. Li, Modelling clinical experience data as an evidence for patient-oriented decision support, BMC Med. Inf. Decis. Making, 20 (2020), 1-11. https://doi.org/10.1186/s12911-020-1121-4 doi: 10.1186/s12911-020-1121-4

|
| [2] |
G. Hripcsak, P. Ludemann, T. A. Pruor, O. B. Wigertz, P. B. Clayton, Rationale for the Arden Syntax, Comput. Biomed. Res., 27 (1994), 291-324. https://doi.org/10.1006/cbmr.1994.1023 doi: 10.1006/cbmr.1994.1023
|
| [3] | M. Peleg, A. A. Boxwala, O. Ogunyemi, Q. Zeng, S. Tu, R. Lacson, et al., GLIF3: The evolution of a guideline representation format, in Proceedings of the AMIA Symposium, (2000), 645-649. |
| [4] |
D. R. Sutton, J. Fox, The syntax and semantics of the PROforma guideline modeling language, J. Am. Med. Inf. Assoc., 10 (2003), 433-443. https://doi.org/10.1197/jamia.m1264 doi: 10.1197/jamia.m1264
|
| [5] | L. Xiao, J. Fox, H. Zhu, An agent-oriented approach to support multidisciplinary care decisions, in Proceedings of the 3rd Eastern European Regional Conference on the Engineering of Computer Based Systems, (2013), 8-17. https://doi.org/10.1109/ECBS-EERC.2013.10 |
| [6] | F. H. Eemeren, R. Grootendorst, R. H. Johnson, C. Plantin, C. A. Willard, Fundamentals of Argumentation Theory: A Handbook of Historical Backgrounds and Contemporary Developments, Routledge, 2013. https://doi.org/10.4324/9780203811306 |
| [7] | J. Conklin, Chapter 4 IBIS: A tool for all reasons, in Dialogue Mapping: Building Shared Understanding of Wicked Problem, Wiley, 2005. |
| [8] | H. W. J. Rittel, Second generation design methods, in Developments in Design Methodology (eds. N. Cross), Wiley & Sons, Chichester, UK, (1984), 317-327. |
| [9] | J. Conklin, Dialogue Mapping, Wiley & Sons, Chichester, 2006. |
| [10] |
J. Fox, D. Glasspool, D. Grecu, S. Modgil, M. South, V. Patkar, Argumentation-based inference and decision making-a medical perspective, IEEE Intell. Syst., 22 (2007), 34-41. https://doi.org/10.1109/MIS.2007.102 doi: 10.1109/MIS.2007.102
|
| [11] | M. Klein, P. Spada, R. Calabretta, Enabling deliberations in a political party using large-scale argumentation: A preliminary report, in Proceedings of the 10th International Conference on the Design of Cooperative Systems, (2012), 17. |
| [12] | S. B. Shum, M. Sierhuis, J. Park, M. Brown, Software agents in support of human argument mapping, in Frontiers in Artificial Intelligence and Applications Series, IOS Press, Amsterdam, 216 (2010), 123-134. http://doi.org/10.3233/978-1-60750-619-5-123 |
| [13] |
M. Klein, Enabling large-scale deliberation using attention-mediation metrics, Comput. Supported Collab. Work, 21 (2012), 449-473. https://doi.org/10.1007/s10606-012-9156-4 doi: 10.1007/s10606-012-9156-4
|
| [14] |
A. Bernstein, M. Klein, T. Malone, Programming the global brain, Commun. ACM, 55 (2012), 41-43. http://doi.org/10.1145/2160718.2160731 doi: 10.1145/2160718.2160731
|
| [15] | T. W. Malone, Superminds: The Surprising Power of People and Computers Thinking Together, Little, Brown Spark, 2018. |
| [16] |
I. Rahwan, F. Zablith, C. Reed, Laying the foundations for a world wide argument web, Artif. Intell., 171 (2007), 897-921. https://doi.org/10.1016/j.artint.2007.04.015 doi: 10.1016/j.artint.2007.04.015
|
| [17] |
F. Bex, J. Lawrence, M. Snaith, C. Reed, Implementing the argument web, Commun. ACM, 56 (2013), 66-73. https://doi.org/10.1145/2500891 doi: 10.1145/2500891
|
| [18] | R. Duthie, J. Lawrence, C. Reed, J. Visser, D. Zografistou, Navigating arguments and hypotheses at scale, in Frontiers in Artificial Intelligence and Applications, IOS Press, 326 (2020), 459-460. https://doi.org/10.3233/FAIA200533 |
| [19] |
C. Chesnevar, J. McGinnis, S. Modgil, I. Rahwan, C. Reed, G. Simari, et al., Towards an argument interchange format, Knowl. Eng. Rev., 21 (2006), 293-316. https://doi.org/10.1017/S0269888906001044 doi: 10.1017/S0269888906001044
|
| [20] | S. Hawke (W3C), Rule Interchange Format Working Group Charter, Available from: https://www.w3.org/2005/rules/wg/charter, last accessed in 2022/5. |
| [21] | I. Rahwan, P. V. Sakeer, Towards representing and querying arguments on the semantic web, in Proceedings of COMMA 2006, (2006), 3-14. |
| [22] |
L. Marco-Ruiz, C. Pedrinaci, J. A. Maldonado, L. Panziera, R. Chen, J. G. Bellika, Publication, discovery and interoperability of clinical decision support systems: A linked data approach, J. Biomed. Inf., 62 (2016), 243-264. https://doi.org/10.1016/j.jbi.2016.07.011 doi: 10.1016/j.jbi.2016.07.011
|
| [23] |
R. S. Gonçalves, S. W. Tu, C. I. Nyulas, M. J. Tierney, M. A. Musen, An ontology-driven tool for structured data acquisition using Web forms, J. Biomed. Semant., 8 (2017), 1-14. https://doi.org/10.1186/s13326-017-0133-1 doi: 10.1186/s13326-017-0133-1
|
| [24] |
F. Sadki, J. Bouaud, G. Guézennec, B. Séroussi, Semantically structured web form and data storage: A generic ontology-driven approach applied to breast cancer, Stud. Health Technol. Inf., 255 (2018), 205-209. https://doi.org/10.3233/978-1-61499-921-8-205 doi: 10.3233/978-1-61499-921-8-205
|
| [25] |
M. Martínez-Romero, J. M. Vázquez-Naya, J. Pereira, M. Pereira, A. Pazos, G. Baños, The iOSC3 system: Using ontologies and SWRL rules for intelligent supervision and care of patients with acute cardiac disorders, Comput. Math. Methods Med., (2013), 650671. https://doi.org/10.1155/2013/650671 doi: 10.1155/2013/650671
|
| [26] |
G. Fischer, A. C. Lemke, R. McCall, A. I. Morch, Making argumentation serve design, Hum. Comput. Interact., 6 (1991), 393-419. http://doi.org/10.1207/s15327051hci0603&4_7 doi: 10.1207/s15327051hci0603&4_7
|
| [27] |
V. Lully, P. Laublet, M. Stankovic, F. Radulovic, Enhancing explanations in recommender systems with knowledge graphs, Procedia Comput. Sci., 137 (2018), 211-222. https://doi.org/10.1016/j.procs.2018.09.020 doi: 10.1016/j.procs.2018.09.020
|
| [28] |
I. Segal, Y. Shahar, A distributed system for support and explanation of shared decision-making in the prenatal testing domain, J. Biomed. Inf., 42 (2009), 272-286. https://doi.org/10.1016/j.jbi.2008.09.004 doi: 10.1016/j.jbi.2008.09.004
|
| [29] | S. E. Toulmin, The Uses of Argument, Cambridge University Press, 2003. https://doi.org/10.1017/CBO9780511840005 |
| [30] | The European Society of Breast Imaging (EUSOBI), Breast ultrasound: Recommendations for information to women and referring physicians by the European society of breast imaging, Insights Imaging, 9 (2018), 449-461. https://doi.org/10.1007%2Fs13244-018-0636-z |
| [31] | The American College of Radiology (ACR), ACR Practice Parameter for the Performance of a Breast Ultrasound Examination, 2016. Available from: https://www.acr.org/-/media/ACR/Files/Practice-Parameters/us-breast.pdf?la=en. |
| [32] | The American College of Radiology (ACR), ACR Practice Guideline for the Performance of Diagnostic Mammography, 2008 (Resolution 24). Available from: https://wiki.radiology.wisc.edu/images/a/a8/SOG_Outreach_ACRattachment.pdf. |
| [33] |
Association of Breast Surgery at BASO, Royal College of Surgeons of England, Guidelines for the management of symptomatic breast disease, Eur. J. Surg. Oncol., 31 (2005), 1-21. https://doi.org/10.1016/j.ejso.2005.02.006 doi: 10.1016/j.ejso.2005.02.006
|
| [34] | J. Siwek, Getting medicine right: Overcoming the problem of overscreening, overdiagnosis, and overtreatment, Am. Fam. Phys., 91 (2015), 18-20. |
| [35] | Choosing Wisely Search Tool Sponsored by American Family Physician, Available from: http://www.aafp.org/afp/recommendations/search.htm, last accessed in 2022/5. |
| [36] |
D. Saslow, C. Boetes, W. Burke, S. Harms, M. O. Leach, C. D. Lehman, et al., American Cancer Society guidelines for breast screening with MRI as an adjunct to mammography, CA Cancer J. Clin., 57 (2007), 75-89. https://doi.org/10.3322/canjclin.57.2.75 doi: 10.3322/canjclin.57.2.75
|
| [37] |
J. L. Khatcheressian, Breast cancer follow-up and management after primary treatment: An American Society of Clinical Oncology clinical practice guideline update, J. Clin. Oncol., 31 (2013), 961-965. https://doi.org/10.1200/jco.2012.45.9859 doi: 10.1200/jco.2012.45.9859
|
| [38] | R. H. Sprague, E. Carlson, Building Effective Decision Support Systems, Prentice-Hall, 1982. |
| [39] |
H. J. Watson, Revisiting ralph sprague's framework for developing decision support systems, Commun. Assoc. Inf. Syst., 42 (2018), 363-385. https://doi.org/10.17705/1CAIS.04213 doi: 10.17705/1CAIS.04213
|
| [40] |
Y. J. Ru, X. H. Qiu, X. Y. Tan, B. Chen, Y. B. Gao, Y. C. Jin, Sparse-attentive meta temporal point process for clinical decision support, Neurocomputing, 485 (2022), 114-123. https://doi.org/10.1016/j.neucom.2022.02.028 doi: 10.1016/j.neucom.2022.02.028
|
| [41] |
X. H. Qiu, X. Y. Tan, Q. Li, S. T. Chen, Y. J. Ru, Y. C. Jin, A latent batch-constrained deep reinforcement learning approach for precision dosing clinical decision support, Knowl. Based Syst., 237 (2022), 107689. https://doi.org/10.1016/j.knosys.2021.107689 doi: 10.1016/j.knosys.2021.107689
|
| [42] |
E. M. Cahan, T. Hernandez-Boussard, S. Thadaney-Israni, D. L. Rubin, Putting the data before the algorithm in big data addressing personalized healthcare, npj Digital Med., 2 (2019), 1-6. https://doi.org/10.1038/s41746-019-0157-2 doi: 10.1038/s41746-019-0157-2
|















Figures(16) / Tables(4)

Liang Xiao, Hao Zhou, John Fox. Towards a systematic approach for argumentation, recommendation, and explanation in clinical decision support[J]. Mathematical Biosciences and Engineering, 2022, 19(10): 10445-10473. doi: 10.3934/mbe.2022489







 DownLoad:
DownLoad: