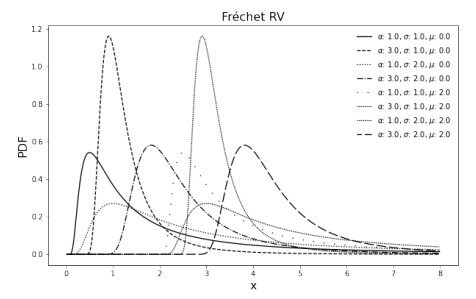
This work aimed to derive new analytical formulas for the stress–strength reliability of the type $ P(X < Y) $ when both $ X $ and $ Y $ follow Fréchet, reversed Weibull or Weibull distributions. The new expressions were given in terms of extreme value $ \mathbb{H} $-functions and have been obtained under fewer parameter restrictions while compared to similar results in the literature of these distributions. The performance of the maximum likelihood estimator was evaluated through Monte-Carlo simulations and the results were compared with a nonparametric estimator. Three real dataset applications were carried out. First, we analyzed the statistical behavior of financial assets' returns, showing how $ P(X < Y) $ can be used to build an interesting approach to perform asset selection. Second, minimum monthly flows of water were analyzed. Finally, we compared failure voltage levels of two types of electrical cable insulation. For all the real case applications, confidence intervals for $ P(X < Y) $ were obtained by Bootstrap methods.
Citation: Tiago A. da Fonseca, Felipe S. Quintino, Luan C. S. M. Ozelim, Pushpa N. Rathie. Estimation of $ P(X < Y) $ for Fréchet, reversed Weibull and Weibull distributions: Analytical expressions, simulations and applications[J]. Networks and Heterogeneous Media, 2024, 19(4): 1424-1447. doi: 10.3934/nhm.2024061
This work aimed to derive new analytical formulas for the stress–strength reliability of the type $ P(X < Y) $ when both $ X $ and $ Y $ follow Fréchet, reversed Weibull or Weibull distributions. The new expressions were given in terms of extreme value $ \mathbb{H} $-functions and have been obtained under fewer parameter restrictions while compared to similar results in the literature of these distributions. The performance of the maximum likelihood estimator was evaluated through Monte-Carlo simulations and the results were compared with a nonparametric estimator. Three real dataset applications were carried out. First, we analyzed the statistical behavior of financial assets' returns, showing how $ P(X < Y) $ can be used to build an interesting approach to perform asset selection. Second, minimum monthly flows of water were analyzed. Finally, we compared failure voltage levels of two types of electrical cable insulation. For all the real case applications, confidence intervals for $ P(X < Y) $ were obtained by Bootstrap methods.

| [1] | L. Haan, A. Ferreira, Extreme Value Theory: An Introduction, Springer, New York, 2006. https://doi.org/10.1007/0-387-34471-3 |
| [2] | R. Fisher, L. Tippett, Limiting forms of the frequency distribution of the largest or smallest member of a sample, in Mathematical Proceedings of the Cambridge Philosophical Society, Cambridge University Press, 1928,180–190. https://doi.org/10.1017/S0305004100015681 |
| [3] | S. Resnick, Extreme Values, Regular Variation, and Point Processes, Springer Science & Business Media, New York, 2008. https://doi.org/10.1007/978-0-387-75953-1 |
| [4] | J. Galambos, The asymptotic theory of extreme order statistics, The Theory and Applications of Reliability with Emphasis on Bayesian and Nonparametric Methods, (1977), 151–164. |
| [5] | P. Embrechts, C. Klüppelberg, T. Mikosch, Modeling Extremal Events: For Insurance and Finance, Springer Berlin, Heidelberg, 2013. https://doi.org/10.1007/978-3-642-33483-2 |
| [6] |
S. Nadarajah, Reliability for extreme value distributions, Math. Comput. Modell., 37 (2003), 915–922. https://doi.org/10.1016/S0895-7177(03)00107-9 doi: 10.1016/S0895-7177(03)00107-9

|
| [7] |
K. Krishnamoorthy, Y. Lin, Confidence limits for stress-strength reliability involving Weibull models, J. Stat. Plann. Inference, 140 (2010), 1754–1764. https://doi.org/10.1016/j.jspi.2009.12.028 doi: 10.1016/j.jspi.2009.12.028
|
| [8] |
D. Kundu, M. Raqab, Estimation of $R = P (Y < X)$ for three-parameter Weibull distribution, Stat. Probab. Lett., 79 (2009), 1839–1846. https://doi.org/10.1016/j.spl.2009.05.026 doi: 10.1016/j.spl.2009.05.026
|
| [9] |
R. Nojosa, P. N. Rathie, Stress-strength reliability models involving generalized gamma and Weibull distributions, Int. J. Qual. Reliab. Manage., 37 (2020), 538–551. https://doi.org/10.1108/IJQRM-06-2019-0190 doi: 10.1108/IJQRM-06-2019-0190
|
| [10] | A. Mathai, R. Saxena, H. Haubold, The H-function: Theory and Applications, Springer, New York, 2009. https://doi.org/10.1007/978-1-4419-0916-9 |
| [11] |
K. Abbas, Y. Tang, Objective Bayesian analysis of the Frechet stress-strength model, Stat. Probab. Lett., 84 (2014), 169–175. https://doi.org/10.1016/j.spl.2013.09.014 doi: 10.1016/j.spl.2013.09.014
|
| [12] |
X. Jia, S. Nadarajah, B. Guo, Bayes estimation of $P(Y < X)$ for the Weibull distribution with arbitrary parameters, Appl. Math. Modell., 47 (2017), 249–259. https://doi.org/10.1016/j.apm.2017.03.020 doi: 10.1016/j.apm.2017.03.020
|
| [13] |
G. K. Bhattacharyya, R. Johnson, Estimation of reliability in a multicomponent stress-strength model, J. Am. Stat. Assoc., 69 (1974), 966–970. https://doi.org/10.1080/01621459.1974.10480238 doi: 10.1080/01621459.1974.10480238
|
| [14] |
J. Jia, Z. Yan, H. Song, Y. Chen, Reliability estimation in multicomponent stress–strength model for generalized inverted exponential distribution, Soft. Comput., 27 (2023), 903–916. https://doi.org/10.1007/s00500-022-07628-1 doi: 10.1007/s00500-022-07628-1
|
| [15] |
R. Lima, F. Quintino, T. da Fonseca, L. Ozelim, P. Rathie, H. Saulo, Assessing the impact of copula selection on reliability measures of type $P (X < Y)$ with generalized extreme value marginals, Modeling, 5 (2024), 180–200. https://doi.org/10.3390/modeling5010010 doi: 10.3390/modeling5010010
|
| [16] |
L. Zhuang, A. Xu, Y. Wang, Y. Tang, Remaining useful life prediction for two-phase degradation model based on reparameterized inverse Gaussian process, Eur. J. Oper. Res., 319 (2024), 877–890. https://doi.org/10.1016/j.ejor.2024.06.032 doi: 10.1016/j.ejor.2024.06.032
|
| [17] |
P. N. Rathie, L. C. S. M. Ozelim, F. Quintino, T. Fonseca, On the extreme value H-function, Stats, 6 (2023), 802–811. https://doi.org/10.3390/stats6030051 doi: 10.3390/stats6030051
|
| [18] |
P. N. Rathie, L. C. S. M. Ozelim, Exact and approximate expressions for the reliability of stable Lévy random variables with applications to stock market modeling, J. Comput. Appl. Math., 321 (2017), 314–322. https://doi.org/10.1016/j.cam.2017.02.043 doi: 10.1016/j.cam.2017.02.043
|
| [19] | P. N. Rathie, S. Freitas, R. Nojosa, A. Mendes, T. Silva, Stress-strength reliability models involving H-function distributions, J. Ramanujan Math. Soc., 9 (2022), 217–234. |
| [20] |
S. Mousavinasr, C. Gonçalves, C. Dorea, Convergence to Frechet distribution via Mallows distance, Stat. Probab. Lett., 163 (2020), 108776. https://doi.org/10.1016/j.spl.2020.108776 doi: 10.1016/j.spl.2020.108776
|
| [21] | B. Efron, The Jackknife, the Bootstrap and other Resampling Plans, Society for Industrial and Applied Mathematics, Philadelphia, 1982. |
| [22] | B. Mandelbrot, The variation of some other speculative prices, J. Bus., 40 (1967), 393–413. |
| [23] | N. N. Taleb, Statistical Consequences of Fat Tails, Technical Incerto, STEM Academic Press, 2020. |
| [24] |
P. Ramos, F. Louzada, E. Ramos, S. Dey, The Fréchet distribution: Estimation and application–An overview, J. Stat. Manage. Syst., 23 (2020), 549–578. https://doi.org/10.1080/09720510.2019.1645400 doi: 10.1080/09720510.2019.1645400
|
| [25] | J. Lawless, Statistical Models and Methods for Lifetime Data, John Wiley & Sons, New York, 2013. https://doi.org/10.1002/9781118033005 |









Figures(10) / Tables(12)
Tiago A. da Fonseca, Felipe S. Quintino, Luan C. S. M. Ozelim, Pushpa N. Rathie. Estimation of $ P(X < Y) $ for Fréchet, reversed Weibull and Weibull distributions: Analytical expressions, simulations and applications[J]. Networks and Heterogeneous Media, 2024, 19(4): 1424-1447. doi: 10.3934/nhm.2024061







 DownLoad:
DownLoad: