Citation: Souliphone Sivixay, Gaowa Bai, Takeshi Tsuruta, Naoki Nishino. Cecum microbiota in rats fed soy, milk, meat, fish, and egg proteins with prebiotic oligosaccharides[J]. AIMS Microbiology, 2021, 7(1): 1-12. doi: 10.3934/microbiol.2021001

| [1] |
Flint HJ, Scott KP, Louis P, et al. (2012) The role of the gut microbiota in nutrition and health. Nat Rev Gastroenterol Hepatol 9: 577-589. doi: 10.1038/nrgastro.2012.156

|
| [2] | Graf D, Cagno RD, Fak F, et al. (2015) Contribution of diet to the composition of the human gut microbiota. Microb Ecol Health Dis 26: 26164. |
| [3] |
Yang Q, Liang Q, Balakrishnan B, et al. (2020) Role of dietary nutrients in the modulation of gut microbiota: A narrative review. Nutrients 12: 381. doi: 10.3390/nu12020381
|
| [4] |
Beaumont M, Porune KJ, Steuer N, et al. (2017) Quantity and source of dietary protein influence metabolite production by gut microbiota and rectal mucosa gene expression: a randomized, parallel, double-blind trial in overweight humans. Am J Clin Nutr 106: 1005-1019. doi: 10.3945/ajcn.117.158816
|
| [5] | Ma N, Tian Y, Wu Y, et al. (2017) Contributions of the interaction between dietary protein and gut microbiota to intestinal health. Curr Protein Pept Sci 18: 795-808. |
| [6] |
Zhu Y, Lin X, Zhao F, et al. (2015) Meat, dairy and plant proteins alter bacterial composition of rat gut bacteria. Sci Rep 5: 15220. doi: 10.1038/srep15220
|
| [7] |
Bai G, Ni K, Tsuruta T, et al. (2016) Dietary casein and soy protein isolate modulate the effects of raffinose and fructooligosaccharides on the composition and fermentation of gut microbiota in rats. J Food Sci 81: H2093-H2098. doi: 10.1111/1750-3841.13391
|
| [8] |
Zhu Y, Shi X, Lin X, et al. (2017) Beef, chicken, and soy proteins in diets induce different gut microbiota and metabolites in rats. Front Microbiol 8: 1395. doi: 10.3389/fmicb.2017.01395
|
| [9] |
Comerford KB, Pasin G (2016) Emerging evidence for the importance of dietary protein source on glucoregulatory markers and type 2 diabetes: Different effects of dairy, meat, fish, egg, and plant protein foods. Nutrients 8: 446. doi: 10.3390/nu8080446
|
| [10] |
Yu H, Qiu N, Meng Y, et al. (2020) A comparative study of the modulation of the gut microbiota in rats by dietary intervention with different sources of egg-white proteins. J Sci Food Agric 100: 3622-3629. doi: 10.1002/jsfa.10387
|
| [11] |
Xia Y, Fukunaga M, Kuda T, et al. (2020) Detection and isolation of protein susceptible indigenous bacteria affected by dietary milk-casein, albumen and soy-protein in the caecum of ICR mice. Int J Biol Macromol 144: 813-820. doi: 10.1016/j.ijbiomac.2019.09.159
|
| [12] |
Bai G, Tsuruta T, Nishino N (2017) Dietary soy, meat, and fish proteins modulate the effects of prebiotic raffinose on composition and fermentation of gut microbiota in rats. Int J Food Sci Nutr 69: 480-487. doi: 10.1080/09637486.2017.1382454
|
| [13] |
Yu Z, Morrison M (2004) Improved extraction of PCR-quality community DNA from digesta and fecal samples. Biotechniques 36: 808-812. doi: 10.2144/04365ST04
|
| [14] |
Nguyen TT, Miyake A, Tran TTM, et al. (2019) The relationship between uterine, fecal, bedding, and airborne dust microbiota from dairy cows and their environment: A pilot study. Animals 9: 1007. doi: 10.3390/ani9121007
|
| [15] |
Scheppach W (1994) Effects of short chain fatty acids on gut morphology and function. Gut 35: S35-S38. doi: 10.1136/gut.35.1_Suppl.S35
|
| [16] |
Hosseini E, Grootaert C, Verstraete W, et al. (2011) Propionate as a health-promoting microbial metabolite in the human gut. Nutr Rev 69: 245-258. doi: 10.1111/j.1753-4887.2011.00388.x
|
| [17] |
An C, Kuda T, Yazaki T, et al. (2014) Caecal fermentation, putrefaction and microbiotas in rats fed milk casein, soy protein or fish meal. Appl Microbiol Biotechnol 98: 2779-2787. doi: 10.1007/s00253-013-5271-5
|
| [18] |
van Zanten GC, Knudsen A, Röytiö H, et al. (2012) The effect of selected synbiotics on microbial composition and short-chain fatty acid production in a model system of the human colon. PLoS One 7: e47212. doi: 10.1371/journal.pone.0047212
|
| [19] |
Sokol H, Pigneur B, Watterlot L, et al. (2008) Faecalibacterium prausnitzii is an anti-inflammatory commensal bacterium identified by gut microbiota analysis of Crohn disease patients. PNAS 105: 16731-16736. doi: 10.1073/pnas.0804812105
|
| [20] |
Schneeberger M, Everard A, Gómez-Valadés AG, et al. (2015) Akkermansia muciniphila inversely correlates with the onset of inflammation, altered adipose tissue metabolism and metabolic disorders during obesity in mice. Sci Rep 5: 16643. doi: 10.1038/srep16643
|
| [21] |
Martínez I, Perdicaro DJ, Brown AW, et al. (2013) Diet-induced alterations of host cholesterol metabolism are likely to affect the gut microbiota composition in hamsters. Appl Environ Microbiol 79: 516-524. doi: 10.1128/AEM.03046-12
|
| [22] |
Li X, Li Z, He Y, et al. (2020) Regional distribution of Christensenellaceae and its associations with metabolic syndrome based on a population-level analysis. PeerJ 8: e9591. doi: 10.7717/peerj.9591
|
| [23] |
Biagi E, Franceschi C, Rampelli S, et al. (2016) Gut microbiota and extreme longevity. Curr Biol 26: 1480-1485. doi: 10.1016/j.cub.2016.04.016
|
| [24] |
Kim BS, Choi CW, Shin H, et al. (2019) Comparison of the gut microbiota of centenarians in longevity villages of South Korea with those of other age groups. J Microbiol Biotechnol 29: 429-440. doi: 10.4014/jmb.1811.11023
|
| [25] |
Kaakoush NO (2015) Insights into the role of Erysipelotrichaceae in the human host. Front Cell Infect Microbiol 5: 84. doi: 10.3389/fcimb.2015.00084
|
| [26] |
Shastri P, McCarville J, Kalmokoff M, et al. (2015) Sex differences in gut fermentation and immune parameters in rats fed an oligofructose-supplemented diet. Bio Sex Differ 6: 13. doi: 10.1186/s13293-015-0031-0
|
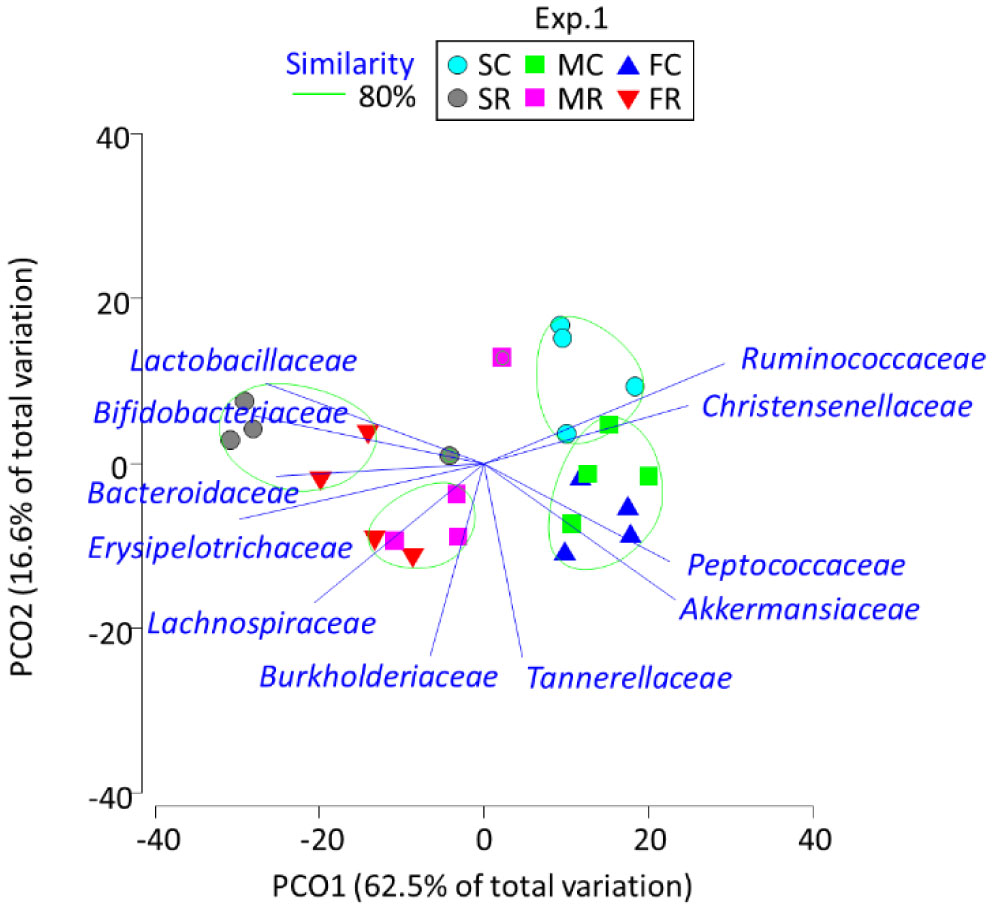
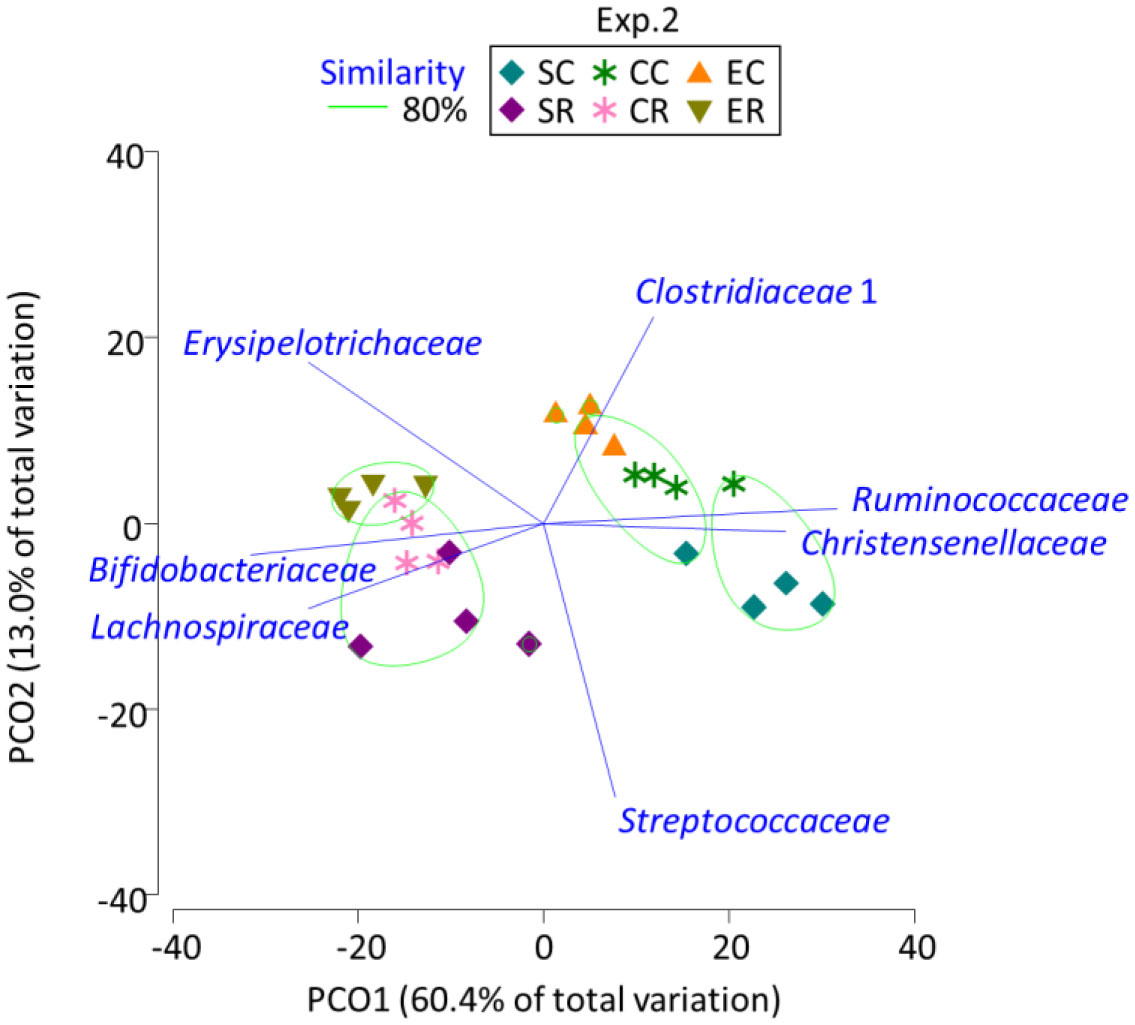
Figures(2) / Tables(2)

Souliphone Sivixay, Gaowa Bai, Takeshi Tsuruta, Naoki Nishino. Cecum microbiota in rats fed soy, milk, meat, fish, and egg proteins with prebiotic oligosaccharides[J]. AIMS Microbiology, 2021, 7(1): 1-12. doi: 10.3934/microbiol.2021001







 DownLoad:
DownLoad: