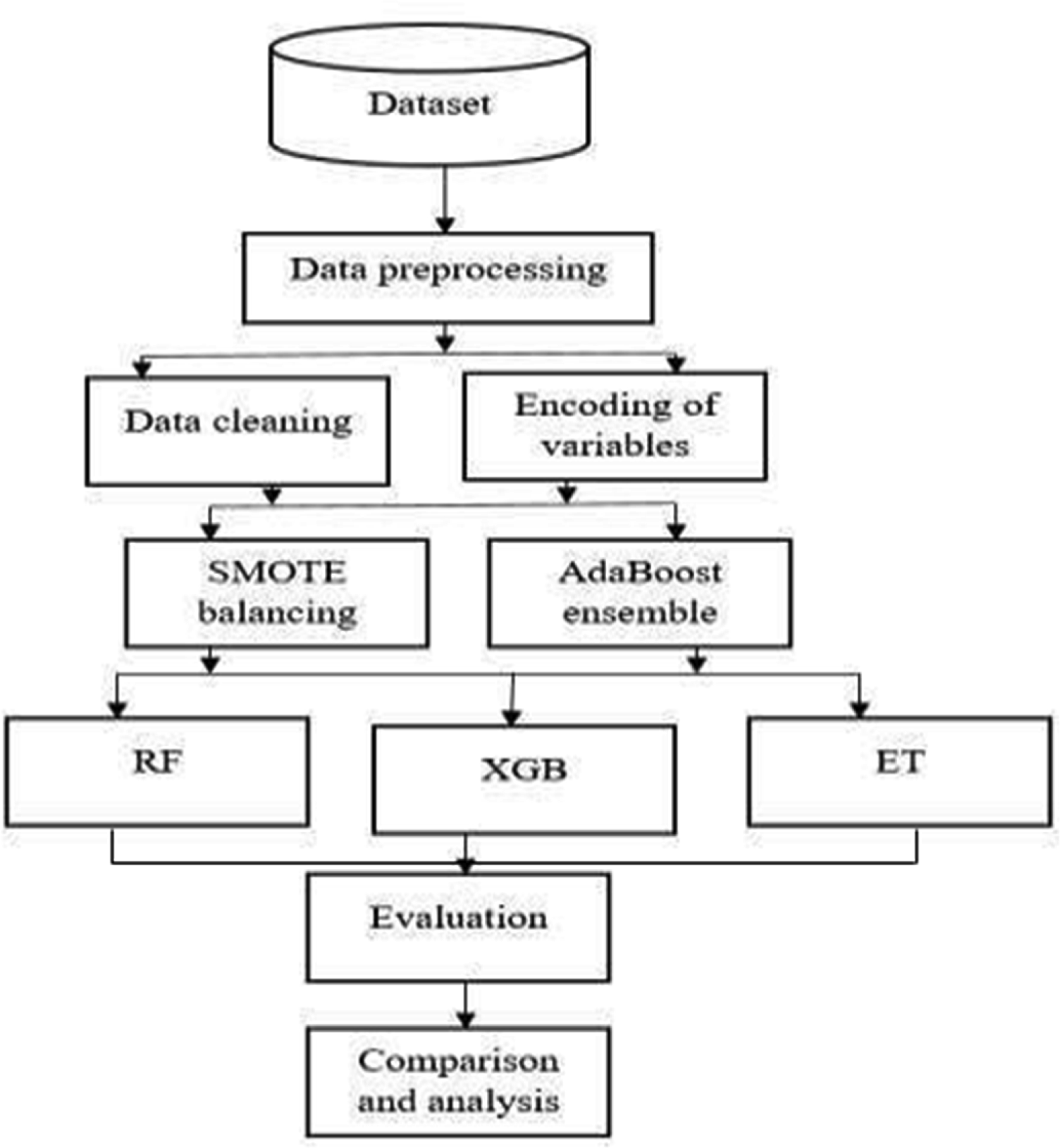
This study presents a novel approach to enhance cardiovascular disease prediction using a hybrid machine learning (ML) model. Leveraging on Synthetic Minority oversampling techniques (SMOTE) and adaptive boosting (AdaBoost), we integrate these methods with prominent classifiers, including Random Forest (RF), Extreme Gradient Boosting (XGBoost), and Extra Tree (ET). Focused on heart rate data as stress level indicators, our objective is to jointly predict cardiovascular disease, thereby addressing the global health challenge of early detection and accurate risk assessments. In response to class imbalance issues in cardiology databases, our hybrid model, which combines SMOTE and AdaBoost, demonstrates promising results. The inclusion of diverse classifiers, such as RF, XGBoost, and ET, enables the model to capture both linear and nonlinear relationships within the heart rate data, significantly enhancing the prediction accuracy. This powerful predictive tool empowers healthcare providers to identify individuals at a high risk for heart disease, thus facilitating timely interventions. This article underscores the pivotal role of ML and hybrid methodologies in advancing health research, particularly in cardiovascular disease prediction. By addressing the class imbalance and incorporating robust algorithms, our research contributes to the ongoing efforts to improve predictive modeling in healthcare. The findings presented here hold significance for medical practitioners and researchers striving for the early detection and prevention of cardiovascular diseases.
Citation: Segun Akinola, Reddy Leelakrishna, Vijayakumar Varadarajan. Enhancing cardiovascular disease prediction: A hybrid machine learning approach integrating oversampling and adaptive boosting techniques[J]. AIMS Medical Science, 2024, 11(2): 58-71. doi: 10.3934/medsci.2024005
This study presents a novel approach to enhance cardiovascular disease prediction using a hybrid machine learning (ML) model. Leveraging on Synthetic Minority oversampling techniques (SMOTE) and adaptive boosting (AdaBoost), we integrate these methods with prominent classifiers, including Random Forest (RF), Extreme Gradient Boosting (XGBoost), and Extra Tree (ET). Focused on heart rate data as stress level indicators, our objective is to jointly predict cardiovascular disease, thereby addressing the global health challenge of early detection and accurate risk assessments. In response to class imbalance issues in cardiology databases, our hybrid model, which combines SMOTE and AdaBoost, demonstrates promising results. The inclusion of diverse classifiers, such as RF, XGBoost, and ET, enables the model to capture both linear and nonlinear relationships within the heart rate data, significantly enhancing the prediction accuracy. This powerful predictive tool empowers healthcare providers to identify individuals at a high risk for heart disease, thus facilitating timely interventions. This article underscores the pivotal role of ML and hybrid methodologies in advancing health research, particularly in cardiovascular disease prediction. By addressing the class imbalance and incorporating robust algorithms, our research contributes to the ongoing efforts to improve predictive modeling in healthcare. The findings presented here hold significance for medical practitioners and researchers striving for the early detection and prevention of cardiovascular diseases.

| [1] |
|
| [2] |
Vogel B, Acevedo M, Appelman Y, et al. (2021) The Lancet women and cardiovascular disease commission: reducing the global burden by 2030. Lancet 397: 2385-2438. https://doi.org/10.1016/S0140-6736(21)00684-X 
|
| [3] |
Benhar H, Idri A, Fernández-Alemán JL (2020) Data preprocessing for heart disease classification: A systematic literature review. Comput Methods Programs Biomed 195: 105635. https://doi.org/10.1016/j.cmpb.2020.105635
|
| [4] |
Aljarah I, Al-Zoubi AM, Faris H, et al. (2018) Simultaneous feature selection and support vector machine optimization using the grasshopper optimization algorithm. Cogn Comput 10: 478-495. https://doi.org/10.1007/s12559-017-9542-9
|
| [5] |
Woźniak M, Grana M, Corchado E (2014) A survey of multiple classifier systems as hybrid systems. Inform Fusion 16: 3-17. https://doi.org/10.1016/j.inffus.2013.04.006
|
| [6] |
Burke LE, Ma J, Azar KMJ, et al. (2015) Current science on consumer use of mobile health for cardiovascular disease prevention: A scientific statement from the American Heart Association. Circulation 132: 1157-1213. https://doi.org/10.1161/CIR.0000000000000232
|
| [7] |
Muhammed SM, Abdul-Majeed G, Mahmoud MS (2023) Prediction of heart diseases by using supervised machine learning algorithms. Wasit J Pure Sci 2: 231-243.
|
| [8] | Singh A, Kumar R, Heart disease prediction using machine learning algorithms. In 2020 International Conference on Electrical and Electronics Engineering (ICE3), Gorakhpur, India (2020) pp. 452-457. https://doi.org/10.1109/ICE348803.2020.9122958 |
| [9] | Memon B, Ghulamani S (2022) A relative study of different machine learning classification algorithms to forecast the heart disease. J Inf Sy Digit Tec 4: 11-27. https://doi.org/10.31436/jisdt.v4i1.305 |
| [10] |
Mohan S, Thirumalai C, Srivastava G (2019) Effective heart disease prediction using hybrid machine learning techniques. IEEE Access 7: 81542-81554. https://doi.org/10.1109/ACCESS.2019.2923707
|
| [11] | Shafique R, Mehmood A, Ullah S, et al. (2019) Cardiovascular disease prediction system using extra trees classifier. https://doi.org/10.21203/rs.2.14454/v1 (unpublished work) |
| [12] | Al Mehedi Hasan M, Shin J, Das U, et al. Identifying prognostic features for predicting heart failure by using machine learning algorithm. In Proceedings of the 2021 11th International Conference on Biomedical Engineering and Technology, Tokyo, Japan, (2021) pp. 40-46. https://doi.org/10.1145/3460238.3460245 |
| [13] |
Goldenberg SL, Nir G, Salcudean SE (2019) A new era: artificial intelligence and machine learning in prostate cancer. Nat Rev Urol 16: 391-403. https://doi.org/10.1038/s41585-019-0193-3
|
| [14] | Shuja M, Mittal S, Zaman M (2018) Decision support predictive model for prognosis of diabetes using SMOTE and decision tree. Int J Appl Eng Res 13: 9277-9282. |
| [15] | Zheng Z, Cai Y, Li Y (2015) Oversampling method for imbalanced classification. Comput Informa 34: 1017-1037. |
| [16] | Ekanayake IU, Meddage DPP, Rathnayake U (2022) A novel approach to explain the black-box nature of machine learning in compressive strength predictions of concrete using Shapley additive explanations (SHAP). Case Stud Constr Mat 16: e01059. https://doi.org/10.1016/j.cscm.2022.e01059 |
| [17] |
Vrieze SI (2012) Model selection and psychological theory: a discussion of the differences between the Akaike information criterion (AIC) and the Bayesian information criterion (BIC). Psychol Methods 17: 228-243. https://doi.org/10.1037/a0027127
|
| [18] |
Wang Z, Mu L, Miao H, et al. (2023) An innovative application of machine learning in prediction of the syngas properties of biomass chemical looping gasification based on extra trees regression algorithm. Energy 275: 127438. https://doi.org/10.1016/j.energy.2023.127438
|
| [19] |
Ricciardi C, Cantoni V, Improta G, et al. (2020) Application of data mining in a cohort of Italian subjects undergoing myocardial perfusion imaging at an academic medical center. Comput Meth Prog Bio 189: 105343. https://doi.org/10.1016/j.cmpb.2020.105343
|
| [20] | Cox R (2015) Hegemonic masculinity and health outcomes in men: A mediational study on the influence of masculinity on diet [Dissertation]. The University of Memphis. |
| [21] |
Rani P, Kumar R, Ahmed NMOS, et al. (2021) A decision support system for heart disease prediction based upon machine learning. J Reliable Intell Environ 7: 263-275. https://doi.org/10.1007/s40860-021-00133-6
|
| [22] |
Adeboye NO, Abimbola OV (2020) An overview of cardiovascular disease infection: A comparative analysis of boosting algorithms and some single based classifiers. Stat J IAOS 36: 1189-1198. https://doi.org/10.3233/SJI-190609
|
| [23] |
Zhang W, Li H, Hun L, et al. (2022) Slope stability prediction using ensemble learning techniques: A case study in Yunyang County, Chongqing, China. J Rock Mech Geotech 14: 1089-1099. https://doi.org/10.1016/j.jrmge.2021.12.011
|
| [24] |
Chawla NV, Bowyer KW, Hall LO, et al. (2002) SMOTE: synthetic minority over-sampling technique. J Artif Intell Res 16: 321-357. https://doi.org/10.1613/jair.953
|
| [25] |
Breiman L (2001) Random forests. Mach Learn 45: 5-32. https://doi.org/10.1023/A:1010933404324
|
| [26] | Kaggle, Heart Failure Prediction Dataset, San Francisco Kaggle, (2021). Available from: https://www.kaggle.com/datasets/fedesoriano/heart-failure-prediction. Accessed June 08, 2023 |
| [27] | Kaggle, HIV AIDS Dataset, San Francisco Kaggle. Available from: https://www.kaggle.com/datasets/imdevskp/hiv-aids-dataset. Accessed June 08, 2023 |
 medsci-11-02-005-s001.pdf medsci-11-02-005-s001.pdf |
 |

Figures(2) / Tables(4)

Segun Akinola, Reddy Leelakrishna, Vijayakumar Varadarajan. Enhancing cardiovascular disease prediction: A hybrid machine learning approach integrating oversampling and adaptive boosting techniques[J]. AIMS Medical Science, 2024, 11(2): 58-71. doi: 10.3934/medsci.2024005







 DownLoad:
DownLoad: