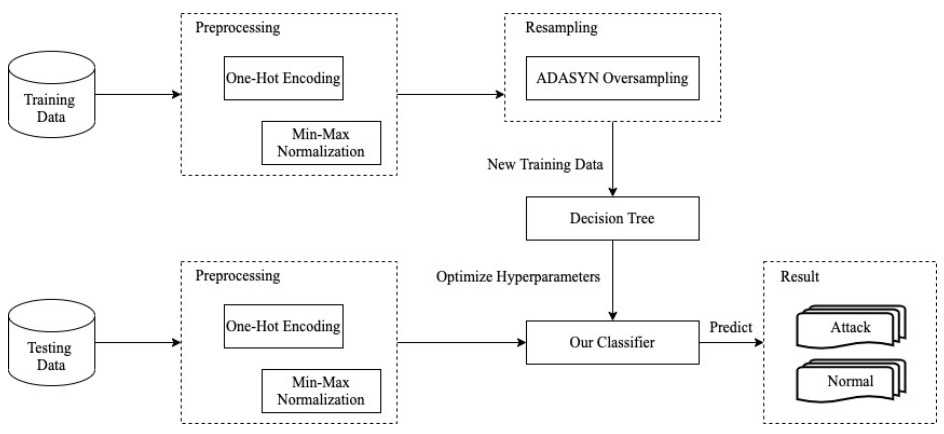
Intrusion detection system plays an important role in network security. Early detection of the potential attacks can prevent the further network intrusion from adversaries. To improve the effectiveness of the intrusion detection rate, this paper proposes a hybrid intrusion detection method that utilizes ADASYN (Adaptive Synthetic) and the decision tree based on ID3 algorithm. At first, the intrusion detection dataset is transformed by coding technology and normalized. Subsequently, the ADASYN algorithm is applied to implement oversampling on the training set, and the ID3 algorithm is employed to build a decision tree model. In addition, the model proposed by the research is evaluated by accuracy, precision, recall, and false alarm rate. Besides, a performance comparison is conducted with other models. Consequently, it is found that the combined model based on ADASYN and ID3 decision tree proposed in this research possesses higher accuracy as well as lower false alarm rate, which is more suitable for intrusion detection tasks.
Citation: Yue Li, Wusheng Xu, Wei Li, Ang Li, Zengjin Liu. Research on hybrid intrusion detection method based on the ADASYN and ID3 algorithms[J]. Mathematical Biosciences and Engineering, 2022, 19(2): 2030-2042. doi: 10.3934/mbe.2022095
Intrusion detection system plays an important role in network security. Early detection of the potential attacks can prevent the further network intrusion from adversaries. To improve the effectiveness of the intrusion detection rate, this paper proposes a hybrid intrusion detection method that utilizes ADASYN (Adaptive Synthetic) and the decision tree based on ID3 algorithm. At first, the intrusion detection dataset is transformed by coding technology and normalized. Subsequently, the ADASYN algorithm is applied to implement oversampling on the training set, and the ID3 algorithm is employed to build a decision tree model. In addition, the model proposed by the research is evaluated by accuracy, precision, recall, and false alarm rate. Besides, a performance comparison is conducted with other models. Consequently, it is found that the combined model based on ADASYN and ID3 decision tree proposed in this research possesses higher accuracy as well as lower false alarm rate, which is more suitable for intrusion detection tasks.

| [1] |
Y. Lu, Industry 4.0: A survey on technologies, applications and open research issues, J. Ind. Inf. Integr., 6 (2017), 1–10. doi: 10.1016/j.jii.2017.04.005. doi: 10.1016/j.jii.2017.04.005

|
| [2] |
P. K. Maddikunta, Q. Pham, P. Deepa, K. Dev, T. R. Gadekallu, R. Ruby, et al., Industry 5.0: A survey on enabling technologies and potential applications, J. Ind. Inf. Integr., 2021 (2021). doi: 10.1016/j.jii.2021.100257. doi: 10.1016/j.jii.2021.100257
|
| [3] |
W. Wang, H. Xu, R. Gadekallu, Z. Han, C. Su, Blockchain-based reliable and efficient certificateless signature for IIoT devices, IEEE Trans. Ind. Inf., 2021 (2021), 1551–3203. doi: 10.1109/TII.2021.3084753. doi: 10.1109/TII.2021.3084753
|
| [4] | H. Xiong, C. Jin, M. Alazab, K. H. Yeh, H. Wang, T. R. R. Gadekallu, et al., On the design of Blockchain-based ECDSA with fault-tolerant batch verication protocol for Blockchain-enabled IoMT, IEEE J. Biomed. Health Inf., 2021 (2021). doi: 10.1109/JBHI.2021.3112693. |
| [5] | W. Wang, C. Qiu, Z. Yin, G. Srivastava, T. R. Gadekallu, F. Alsolami, et al., Blockchain and PUF-based lightweight authentication protocol for wireless medical sensor networks, IEEE Internet Things J., 2021 (2021). doi: 10.1109/JIOT.2021.3117762. |
| [6] | W. Wang, M. H. Memon, Z. Lian, Z. Yin, Q. V. Pham, T. R. Gadekallu, et al., Secure-enhanced federated learning for ai-empowered electric vehicle energy prediction, IEEE Consum. Electron. Mag., 2021 (2021). doi: 10.1109/MCE.2021.3116917. |
| [7] | W. Lee, S. J. Stolfo, K. W. Mok, A data mining framework for building intrusion detection models, in Proceedings of the 1999 IEEE Symposium on Security and Privacy, 1999. doi: 10.1109/SECPRI.1999.766909. |
| [8] |
A. Buczak, E. Guven, A survey of data mining and machine learning methods for cyber security intrusion detection, IEEE Commun. Surv. Tutorials, 18 (2016), 1153–1176. doi: 10.1109/COMST.2015.2494502. doi: 10.1109/COMST.2015.2494502
|
| [9] |
P. Animesh, J. Park, An overview of anomaly detection techniques: Existing solutions and latest technological trends, Comput. Networks, 51 (2007), 3448–3470. doi: 10.1016/j.comnet.2007.02.001. doi: 10.1016/j.comnet.2007.02.001
|
| [10] |
N. Moustafa, J. Slay, The evaluation of network anomaly detection systems: statistical analysis of the UNSW-NB15 data set and the comparison with the KDD99 data set, Inf. Secur. J., 25 (2016), 18–31. doi: 10.1080/19393555.2015.1125974. doi: 10.1080/19393555.2015.1125974
|
| [11] |
V. Kanimozhi, P. Jacob, UNSW-NB15 dataset feature selection and network intrusion detection using deep learning, Int. J. Recent Technol. Eng., 7 (2019), 443–446. doi: 10.1080/19393555.2015.1125974. doi: 10.1080/19393555.2015.1125974
|
| [12] |
X. P. Tan, S. J. Su, Z. P. Huang, X. J. Guo, Z. Zuo, X. Sun, et al. Wireless sensor networks intrusion detection based on SMOTE and the random forest algorithm, Sensors, 19 (2020), 203. doi: 10.3390/s19010203. doi: 10.3390/s19010203
|
| [13] |
A. Muniyandi, R. Rajeswari, R. Rajaram, Network anomaly detection by cascading k-Means clustering and C4.5 decision tree algorithm, Proc. Eng., 30 (2012), 174–182. doi: 10.1016/j.proeng.2012.01.849. doi: 10.1016/j.proeng.2012.01.849
|
| [14] |
G. Kim, S. Lee, S. Kim, A novel hybrid intrusion detection method integrating anomaly detection with misuse detection, Expert Syst. Appl., 41 (2014), 1690–1700. doi: 10.1016/j.eswa.2013.08.066. doi: 10.1016/j.eswa.2013.08.066
|
| [15] | S. Miller, C. Busby-Earle, Multi-perspective machine learning a classifier ensemble method for intrusion detection, in Proceedings of the 2017 international conference on machine learning and soft computing, 2017 (2017), 7–12. doi: 10.1145/3036290.3036303. |
| [16] | N. Moustafa, J. Slay, UNSW-NB15: a comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set), in 2015 Military Communications and Information Systems Conference, MilCIS 2015-Proceedings, 2015. doi: 10.1109/MilCIS.2015.7348942. |
| [17] | Australian Centre for Cyber Security (ACCS), The UNSW-NB15 Dataset Description. Available from: https://www.unsw.adfa.edu.au/unsw-canberra-cyber/cybersecurity/ADFA-NB15-Datasets/. |
| [18] | T. Janarthanan, S. Zargari, Feature selection in UNSW-NB15 and KDDCUP'99 datasets, in 2017 IEEE 26th International Symposium on Industrial Electronics (ISIE), (2017), 1881–1886. doi: 10.1109/ISIE.2017.8001537. |
| [19] | H. He, Y. Bai, E. A. Garcia, S. Li, ADASYN: Adaptive synthetic sampling approach for imbalanced learning, in 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), (2008), 1322–1328. doi: 10.1109/IJCNN.2008.4633969. |
| [20] | P. Liu, M. Hong, D. Huang, Y. Luo, S. Wang, Joint ADASYN and AdaBoostSVM for imbalanced learining, J. Beijing Univ. Technol., 43 (2017), 368–375. |
| [21] |
J. R. Quinlan, Induction of Decision Tree, Machine Learning, 1 (1986), 81–106. doi: 10.1007/BF00116251. doi: 10.1007/BF00116251
|
| [22] |
X. Wang, L. Wang, N. Li, An application of decision tree based on ID3, Phys. Procedia, 25 (2012), 1017–1021. doi: 10.1016/j.phpro.2012.03.193. doi: 10.1016/j.phpro.2012.03.193
|
| [23] | J. R. Quinlan, C4.5: Programs for Machine Learning, Morgan Kaufmann Publishers Inc., 1992. |
| [24] |
J. R. Quinlan, Decision tree and decision-making, IEEE Trans. Syste. Man Cybern., 20 (1990), 339–346. doi: 10.1109/21.52545. doi: 10.1109/21.52545
|
| [25] | R. Susmaga, Confusion matrix visualizatio, in Intelligent Information Processing and Web Mining, Springer, Berlin, Heidelberg, (2004), 107–116. doi: 10.1007/978-3-540-39985-8_12. |
| [26] |
M. Salem, U. Buehler, Mining techniques in network security to enhance intrusion detection systems, Int. J. Network Secur. Its Appl., 2012 (2012), 167–172. doi: 10.5121/ijnsa. doi: 10.5121/ijnsa
|
| [27] |
F. A. Khan, A. Gumaei, A. Derhab, A. Hussain, A novel two-stage deep learning model for efficient network intrusion detection, IEEE Access, 7 (2019), 30373–30385. doi: 10.1109/ACCESS.2019.2899721. doi: 10.1109/ACCESS.2019.2899721
|
| [28] |
A. L. H. Muna, N. Moustafa, E. Sitnikova, Identification of malicious activities in industrial Internet of things based on deep learning models, J. Inf. Secur. Appl., 41 (2018), 1–11. doi: 10.1016/j.jisa.2018.05.002. doi: 10.1016/j.jisa.2018.05.002
|
| [29] | M. Guerroumi, A. Derhab, NSNAD: negative selection-based network anomaly detection approach with relevant feature subset, Neural Comput. Appl., 32 (2020), 3475–3501. doi: 0.1007/s00521-019-04396-2. |
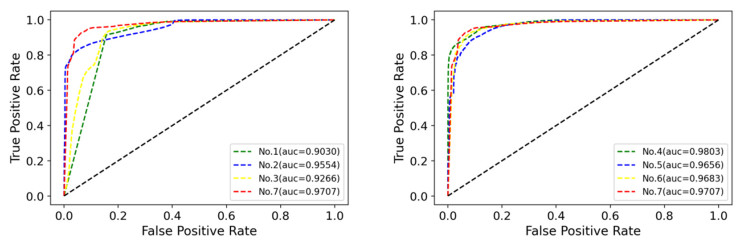
Figures(5) / Tables(4)

Yue Li, Wusheng Xu, Wei Li, Ang Li, Zengjin Liu. Research on hybrid intrusion detection method based on the ADASYN and ID3 algorithms[J]. Mathematical Biosciences and Engineering, 2022, 19(2): 2030-2042. doi: 10.3934/mbe.2022095







 DownLoad:
DownLoad: