In the past few years, Safe Semi-Supervised Learning (S3L) has received considerable attentions in machine learning field. Different researchers have proposed many S3L methods for safe exploitation of risky unlabeled samples which result in performance degradation of Semi-Supervised Learning (SSL). Nevertheless, there exist some shortcomings: (1) Risk degrees of the unlabeled samples are in advance defined by analyzing prediction differences between Supervised Learning (SL) and SSL; (2) Negative impacts of labeled samples on learning performance are not investigated. Therefore, it is essential to design a novel method to adaptively estimate importance and risk of both unlabeled and labeled samples. For this purpose, we present $ \ell_{1} $-norm based S3L which can simultaneously reach the safe exploitation of the labeled and unlabeled samples in this paper. In order to solve the proposed ptimization problem, we utilize an effective iterative approach. In each iteration, one can adaptively estimate the weights of both labeled and unlabeled samples. The weights can reflect the importance or risk of the labeled and unlabeled samples. Hence, the negative effects of the labeled and unlabeled samples are expected to be reduced. Experimental performance on different datasets verifies that the proposed S3L method can obtain comparable performance with the existing SL, SSL and S3L methods and achieve the expected goal.
Citation: Haitao Gan, Zhi Yang, Ji Wang, Bing Li. $ \ell_{1} $-norm based safe semi-supervised learning[J]. Mathematical Biosciences and Engineering, 2021, 18(6): 7727-7742. doi: 10.3934/mbe.2021383
In the past few years, Safe Semi-Supervised Learning (S3L) has received considerable attentions in machine learning field. Different researchers have proposed many S3L methods for safe exploitation of risky unlabeled samples which result in performance degradation of Semi-Supervised Learning (SSL). Nevertheless, there exist some shortcomings: (1) Risk degrees of the unlabeled samples are in advance defined by analyzing prediction differences between Supervised Learning (SL) and SSL; (2) Negative impacts of labeled samples on learning performance are not investigated. Therefore, it is essential to design a novel method to adaptively estimate importance and risk of both unlabeled and labeled samples. For this purpose, we present $ \ell_{1} $-norm based S3L which can simultaneously reach the safe exploitation of the labeled and unlabeled samples in this paper. In order to solve the proposed ptimization problem, we utilize an effective iterative approach. In each iteration, one can adaptively estimate the weights of both labeled and unlabeled samples. The weights can reflect the importance or risk of the labeled and unlabeled samples. Hence, the negative effects of the labeled and unlabeled samples are expected to be reduced. Experimental performance on different datasets verifies that the proposed S3L method can obtain comparable performance with the existing SL, SSL and S3L methods and achieve the expected goal.

| [1] | O. Chapelle, B. Scholkopf, A. Zien, editors, Semi-Supervised Learning, MIT Press, Cambridge, MA, 2006. |
| [2] |
W. J. Chen, Y. H. Shao, C. N. Li, N. Y. Deng, MLTSVM: A novel twin support vector machine to multi-label learning, Pattern Recognit., 52 (2016), 61–74. doi: 10.1016/j.patcog.2015.10.008

|
| [3] |
I. Cohen, F. G. Cozman, N. Sebe, M. C. Cirelo, T. S. Huang, Semisupervised learning of classifiers: theory, algorithms, and their application to human-computer interaction, IEEE Trans. Pattern Anal. Mach. Intell., 26 (2004), 1553–1566. doi: 10.1109/TPAMI.2004.127
|
| [4] |
X. D. Wang, R. C. Chen, C. Q. Hong, Z. Q. Zeng, Z. L. Zhou, Semi-supervised multi-label feature selection via label correlation analysis with l1-norm graph embedding, Image Vision Comput., 63 (2017), 10–23. doi: 10.1016/j.imavis.2017.05.004
|
| [5] |
H. Gan, N. Sang, R. Huang, X. Tong, Z. Dan, Using clustering analysis to improve semi-supervised classification, Neurocomputing, 101 (2013), 290–298. doi: 10.1016/j.neucom.2012.08.020
|
| [6] | X. Zhu, Semi-supervised learning literature survey, Technical Report 1530, Computer Sciences, University of Wisconsin-Madison, 2005. |
| [7] |
Z. Qi, Y. Xu, L. Wang, Y. Song, Online multiple instance boosting for object detection, Neurocomputing, 74 (2011), 1769–1775. doi: 10.1016/j.neucom.2011.02.011
|
| [8] |
B. Tan, J. Zhang, L. Wang, Semi-supervised elastic net for pedestrian counting, Pattern Recognit., 44 (2011), 2297 – 2304. doi: 10.1016/j.patcog.2010.10.002
|
| [9] |
Y. Cao, H. He, H. H. Huang, Lift: A new framework of learning from testing data for face recognition, Neurocomputing, 74 (2011), 916–929. doi: 10.1016/j.neucom.2010.10.015
|
| [10] | H. Gan, N. Sang, R. Huang, Self-training-based face recognition using semi-supervised linear discriminant analysis and affinity propagation, J. Opt. Soc. Am. A, 31 (2014), 1–6. |
| [11] |
J. Richarz, S. Vajda, R. Grzeszick, G. A. Fink, Semi-supervised learning for character recognition in historical archive documents, Pattern Recognit., 47 (2014), 1011–1020. doi: 10.1016/j.patcog.2013.07.013
|
| [12] |
G. Tur, D. H. Tur, R. E. Schapire, Combining active and semi-supervised learning for spoken language understanding, Speech Commun., 45 (2005), 171 – 186. doi: 10.1016/j.specom.2004.08.002
|
| [13] | B. Varadarajan, D. Yu, L. Deng, A. Acero, Using collective information in semi-supervised learning for speech recognition, in Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, IEEE, (2009), 4633–4636. |
| [14] |
N. V. Chawla, G. Karakoulas, Learning from labeled and unlabeled data: An empirical study across techniques and domains, J. Artif. Intell. Res., 23 (2005), 331–366. doi: 10.1613/jair.1509
|
| [15] |
H. Gan, Z. Luo, Y. Sun, X. Xi, N. Sang, R. Huang, Towards designing risk-based safe laplacian regularized least squares, Expert Syst. Appl., 45 (2016), 1–7. doi: 10.1016/j.eswa.2015.09.017
|
| [16] | H. Gan, N. Sang, X. Chen, Semi-supervised kernel minimum squared error based on manifold structure, in Proceedings of the 10th International Symposium on Neural Networks, Berlin, Heidelberg, 7951 (2013), 265–272. |
| [17] | A. Singh, R. Nowak, X. Zhu, Unlabeled data: Now it helps, now it doesn't, Adv. Neural Inf. Proc. Syst., 21 (2008), 1513–1520. |
| [18] |
T. Yang, C. E. Priebe, The effect of model misspecification on semi-supervised classification, IEEE Trans. Pattern Anal. Mach. Intell., 33 (2011), 2093–2103. doi: 10.1109/TPAMI.2011.45
|
| [19] | Y. F. Li, Z. H. Zhou, Improving semi-supervised support vector machines through unlabeled instances selection, in Proceedings of the Twenty-Fifth AAAI Conference on Artificial Intelligence, AAAI Press, (2011), 500–505. |
| [20] | T. Joachims, Transductive inference for text classification using support vector machines, in Proceedings of the Sixteenth International Conference on Machine Learning, San Francisco, CA, 99 (1999), 200–209. |
| [21] | Y. F. Li, S. B. Wang, Z. H. Zhou, Graph quality judgement: A large margin expedition, in Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, (2016), 1725–1731. |
| [22] |
Y. Wang, S. Chen, Safety-aware semi-supervised classification, IEEE Trans. Neural Networks Learn. Syst., 24 (2013), 1763–1772. doi: 10.1109/TNNLS.2013.2263512
|
| [23] | Y. Wang, Y. Meng, Z. Fu, H. Xue, Towards safe semi-supervised classification: Adjusted cluster assumption via clustering, Neural Process. Lett., 2017. |
| [24] | Y. F. Li, Z. H. Zhou, Towards making unlabeled data never hurt, in Proceedings of the 28th International Conference on Machine Learning, Omnipress, (2011), 1081–1088. |
| [25] | T. F. Covoes, R. C. Barros, T. S. da Silva, E. R. Hruschka, A. C. P. L. F. de Carvalho, Hierarchical bottom-up safe semi-supervised support vector machines for multi-class transductive learning, J. Inf. Data Manage., 4 (2013), 357–373. |
| [26] |
H. Gan, Z. Li, W. Wu, Z. Luo, R. Huang, Safety-aware graph-based semi-supervised learning, Expert Syst. Appl., 107 (2018), 243–254. doi: 10.1016/j.eswa.2018.04.031
|
| [27] | Y. F. Li, H. W. Zha, Z. H. Zhou, Learning safe prediction for semi-supervised regression, in Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, California, (2017), 2217–2223. |
| [28] | H. Gan, Z. Li, Safe semi-supervised learning from risky labeled and unlabeled samples, in 2018 Chinese Automation Congress, IEEE, (2018), 2096–2100. |
| [29] | M. Belkin, P. Niyogi, V. Sindhwani, Manifold regularization: A geometric framework for learning from labeled and unlabeled examples, J. Mach. Learn. Res., 7 (2006), 2399–2434. |
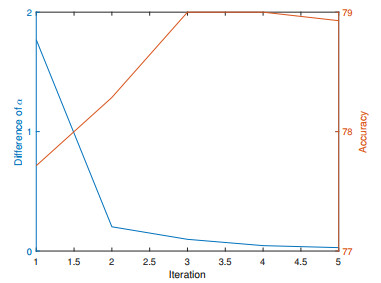
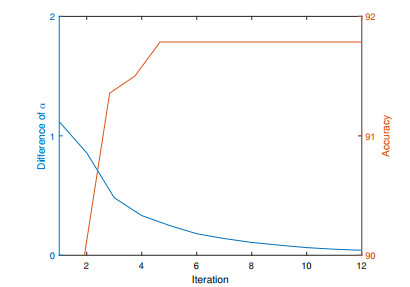

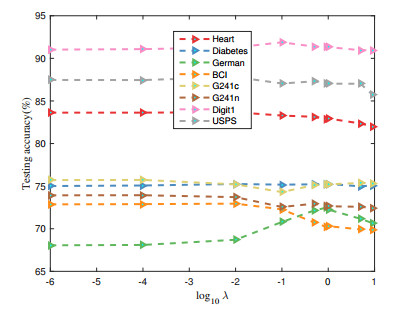
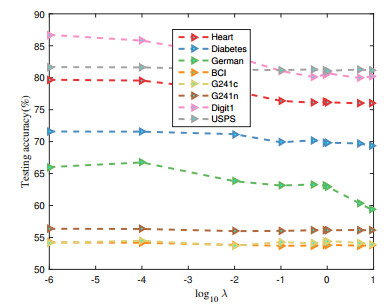
Figures(6) / Tables(3)

Haitao Gan, Zhi Yang, Ji Wang, Bing Li. $ \ell_{1} $-norm based safe semi-supervised learning[J]. Mathematical Biosciences and Engineering, 2021, 18(6): 7727-7742. doi: 10.3934/mbe.2021383







 DownLoad:
DownLoad: