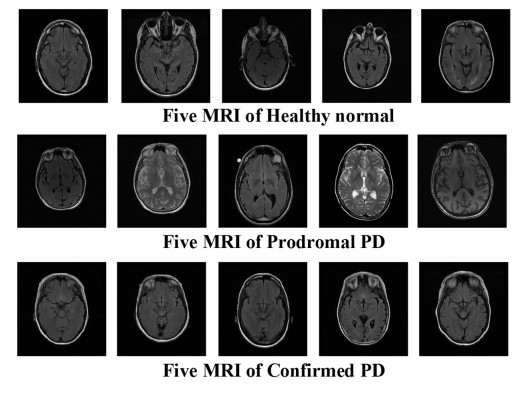
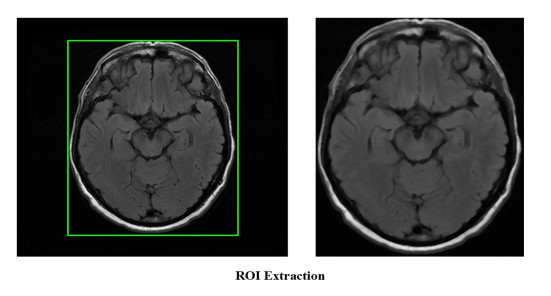
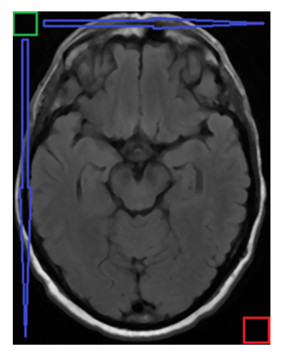
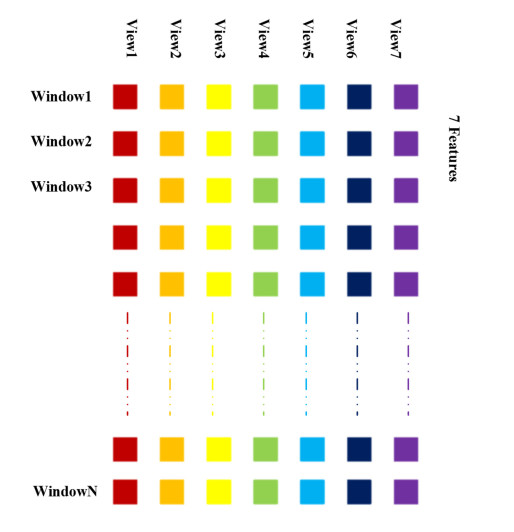
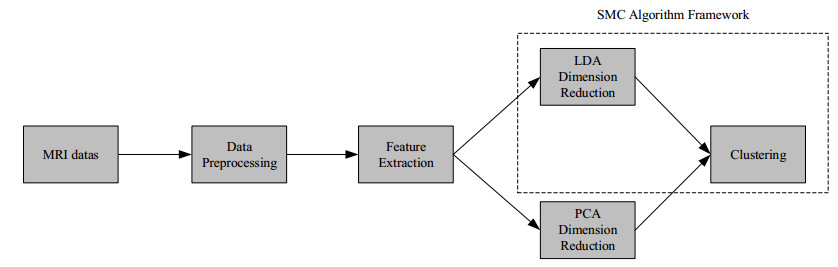
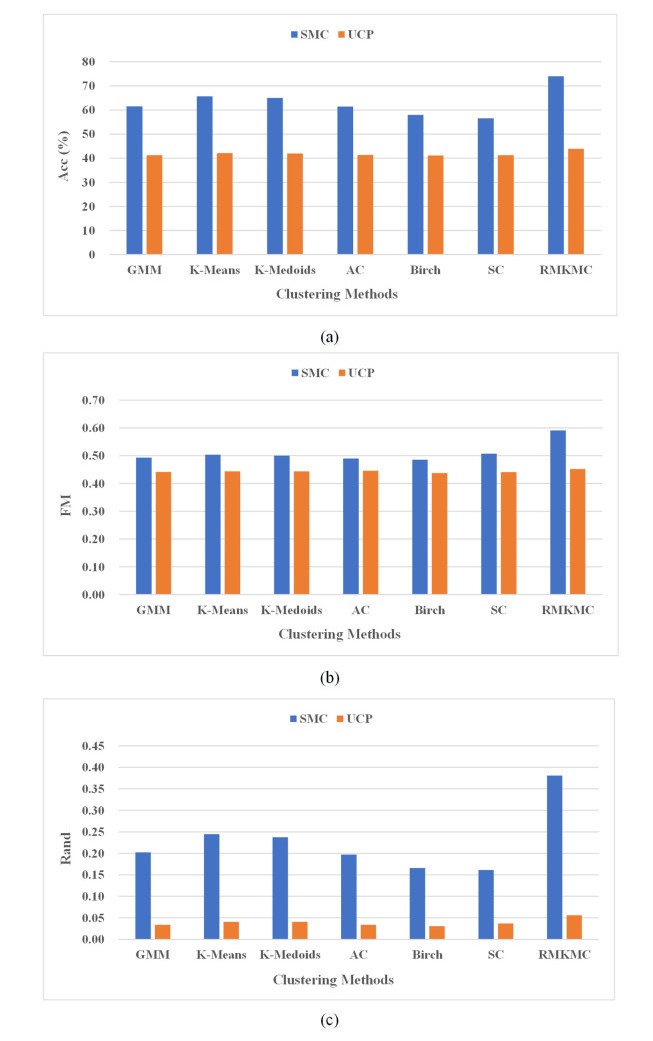
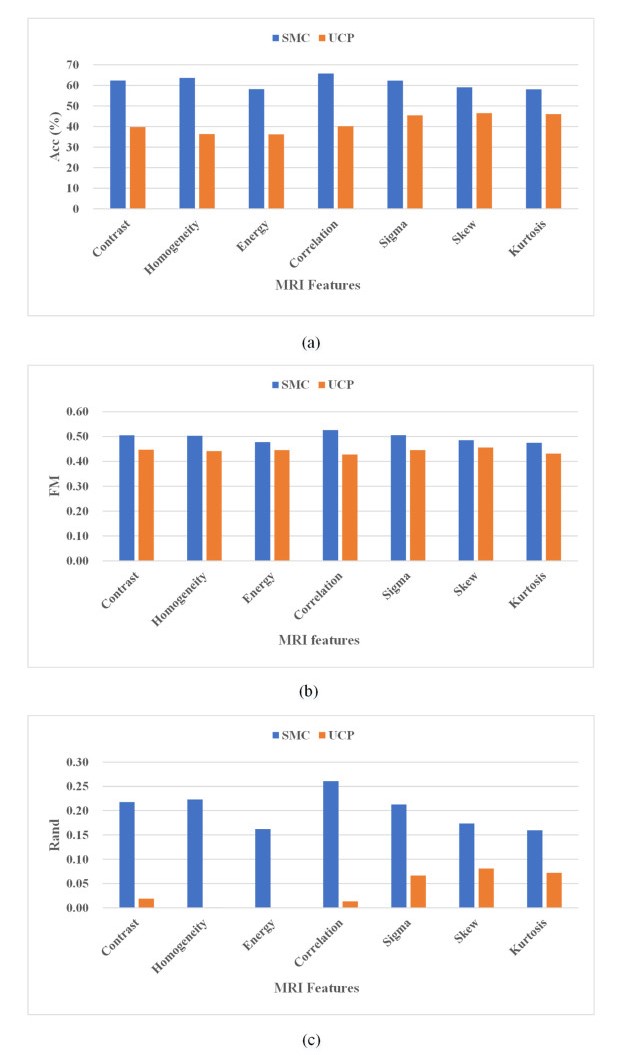
In recent years, there are many research cases for the diagnosis of Parkinson's disease (PD) with the brain magnetic resonance imaging (MRI) by utilizing the traditional unsupervised machine learning methods and the supervised deep learning models. However, unsupervised learning methods are not good at extracting accurate features among MRIs and it is difficult to collect enough data in the field of PD to satisfy the need of training deep learning models. Moreover, most of the existing studies are based on single-view MRI data, of which data characteristics are not sufficient enough. In this paper, therefore, in order to tackle the drawbacks mentioned above, we propose a novel semi-supervised learning framework called Semi-supervised Multi-view learning Clustering architecture technology (SMC). The model firstly introduces the sliding window method to grasp different features, and then uses the dimensionality reduction algorithms of Linear Discriminant Analysis (LDA) to process the data with different features. Finally, the traditional single-view clustering and multi-view clustering methods are employed on multiple feature views to obtain the results. Experiments show that our proposed method is superior to the state-of-art unsupervised learning models on the clustering effect. As a result, it may be noted that, our work could contribute to improving the effectiveness of identifying PD by previous labeled and subsequent unlabeled medical MRI data in the realistic medical environment.
Citation: Xiaobo Zhang, Donghai Zhai, Yan Yang, Yiling Zhang, Chunlin Wang. A novel semi-supervised multi-view clustering framework for screening Parkinson's disease[J]. Mathematical Biosciences and Engineering, 2020, 17(4): 3395-3411. doi: 10.3934/mbe.2020192
In recent years, there are many research cases for the diagnosis of Parkinson's disease (PD) with the brain magnetic resonance imaging (MRI) by utilizing the traditional unsupervised machine learning methods and the supervised deep learning models. However, unsupervised learning methods are not good at extracting accurate features among MRIs and it is difficult to collect enough data in the field of PD to satisfy the need of training deep learning models. Moreover, most of the existing studies are based on single-view MRI data, of which data characteristics are not sufficient enough. In this paper, therefore, in order to tackle the drawbacks mentioned above, we propose a novel semi-supervised learning framework called Semi-supervised Multi-view learning Clustering architecture technology (SMC). The model firstly introduces the sliding window method to grasp different features, and then uses the dimensionality reduction algorithms of Linear Discriminant Analysis (LDA) to process the data with different features. Finally, the traditional single-view clustering and multi-view clustering methods are employed on multiple feature views to obtain the results. Experiments show that our proposed method is superior to the state-of-art unsupervised learning models on the clustering effect. As a result, it may be noted that, our work could contribute to improving the effectiveness of identifying PD by previous labeled and subsequent unlabeled medical MRI data in the realistic medical environment.

| [1] | C. W. Tsai, R. T. Tsai, S. P. Liu, C. S. Chen, M. C. Tasi, S. H. Chien, et al., Neuroprotective effects of betulin in pharmacological and transgenic Caenorhabditis elegans models of parkinsons disease, Cell Transplant., 26 (2018), 1903-1918. |
| [2] |
R. E. Burke, K. O'Malley, Axon degeneration in parkinson's disease, Exp. Neurol., 246 (2013), 72-83. doi: 10.1016/j.expneurol.2012.01.011

|
| [3] |
C. P. Weingarten, M. H. Sundman, P. Hickey, N. K. Chen, Neuroimaging of parkinson's disease: Expanding views, Neurosci. Biobehav. Rev., 59 (2015), 16-52. doi: 10.1016/j.neubiorev.2015.09.007
|
| [4] |
Y. Kim, S. M. Cheon, C. Youm, M. Son, J. W. Kim, Depression and posture in patients with parkinsons disease, Gait Posture, 61 (2018), 81-85. doi: 10.1016/j.gaitpost.2017.12.026
|
| [5] |
R. Martínez-Fernández, R. Rodríguez-Rojas, M. del Álamo, F. Hernández-Fernández, J. A. Pineda-Pardo, M. Dileone, et al., Focused ultrasound subthalamotomy in patients with asymmetric Parkinson's disease: A pilot study, Lancet Neurol., 17 (2018), 54-63. doi: 10.1016/S1474-4422(17)30403-9
|
| [6] |
D. Frosini, M. Cosottini, D. Volterrani, R. Ceravolo, Neuroimaging in parkinson's disease: Focus on substantia nigra and nigro-striatal projection, Curr. Opin. Neurol., 30 (2017), 416-426. doi: 10.1097/WCO.0000000000000463
|
| [7] |
K. Marek, D. Jennings, S. Lasch, A. Siderowf, C. Tanner, T Simuni, et al., The Parkinson progression marker initiative (PPMI), Prog. Neurobiol., 95 (2011), 629-635. doi: 10.1016/j.pneurobio.2011.09.005
|
| [8] | J. Shi, Z. Xue, Y. Dai, B. Peng, Y. Dong, Q. Zhang, et al., Cascaded multi-column RVFL+ classifier for single-modal neuroimaging-based diagnosis of Parkinson's disease, IEEE Trans. Biomed. Eng., 66 (2018), 2362-2371. |
| [9] |
B. Peng, S. Wang, Z. Zhou, Y. Liu, B. Tong, T. Zhang, et al., A multilevel-roi-features-based machine learning method for detection of morphometric biomarkers in parkinsons disease, Neurosci. Lett., 651 (2017), 88-94. doi: 10.1016/j.neulet.2017.04.034
|
| [10] |
R. Prashanth, S. D. Roy, P. K. Mandal, S. Ghosh, High-accuracy classification of parkinson's disease through shape analysis and surface fitting in 123I-Ioflupane SPECT imaging, IEEE J. Biomed. Health Inf., 21 (2017), 794-802. doi: 10.1109/JBHI.2016.2547901
|
| [11] |
F. P. Oliveira, M. Castelo-Branco, Computer-aided diagnosis of Parkinson's disease based on [123I] FP-CIT SPECT binding potential images, using the voxels-as-features approach and support vector machines, J. Neural Eng., 12 (2015), 026008. doi: 10.1088/1741-2560/12/2/026008
|
| [12] |
G. Garraux, C. Phillips, J. Schrouff, A. Kreisler, C. Lemaire, C. Degueldre, et al., Multiclass classification of FDG PET scans for the distinction between Parkinson's disease and atypical parkinsonian syndromes, NeuroImage Clin., 2 (2013), 883-893. doi: 10.1016/j.nicl.2013.06.004
|
| [13] |
D. Long, J. Wang, M. Xuan, Q Gu, X. Xu, D. Kong, et al., Automatic classification of early Parkinson's disease with multi-modal MR imaging, Plos One, 7 (2012), e47714. doi: 10.1371/journal.pone.0047714
|
| [14] |
A. Abos, H. C. Baggio, B. Segura, A. I. García-Díaz, Y. Compta, M. J. Martí, et al., Discriminating cognitive status in Parkinson's disease through functional connectomics and machine learning, Sci. Rep., 7 (2017), 45347. doi: 10.1038/srep45347
|
| [15] |
H. Lei, Z. Huang, F. Zhou, A. Elazab, E. Tan, H. Li, et al., Parkinson's disease diagnosis via joint learning from multiple modalities and relations, IEEE J. Biomed. Health Inf., 23 (2019), 1437-1449. doi: 10.1109/JBHI.2018.2868420
|
| [16] |
E. Adeli, F. Shi, L. An, C. Y. Wee, G. Wu, T. Wang, et al., Joint feature-sample selection and robust diagnosis of Parkinson's disease from MRI data, NeuroImage, 141 (2016), 206-219. doi: 10.1016/j.neuroimage.2016.05.054
|
| [17] |
E. Adeli, G. Wu, B. Saghafi, L. An, F. Shi, D. Shen, Kernel-based joint feature selection and max-margin classification for early diagnosis of parkinsons disease, Sci. Rep., 7 (2017), 41069. doi: 10.1038/srep41069
|
| [18] | X. Cai, F. Nie, H. Huang, Multi-view k-means clustering on big data, Proceedings of the 23rd International Joint Conference on Artificial Intelligence, 2013. Available from: https://www.aaai.org/ocs/index.php/IJCAI/IJCAI13/paper/viewPaper/6979. |
| [19] | R. Kohavi, A study of cross-validation and bootstrap for accuracy estimation and model selection, Proceedings of the 14th International Joint conference on Artificial Intelligence, 1995, 1137-1143. Available from: https://www.researchgate.net/profile/Ron_Kohavi/publication/2352264_A_Study_of_Cross-Validation_and_Bootstrap_for_Accuracy_Estimation_and_Model_Selection/links/02e7e51bcc14c5e91c000000.pdf. |
| [20] | S. Balakrishnama, A. Ganapathiraju, Linear discriminant analysis-a brief tutorial, Inst. Signal Inf. Process., 18 (1998), 1-8. |
| [21] | F. Samaria, F. Fallside, Face identification and feature extraction using hidden markov models, Olivetti Research Limited, (1993). |
| [22] |
N. Vlassis, A. Likas, A greedy EM algorithm for Gaussian mixture learning, Neural Process. Lett., 15 (2002), 77-87. doi: 10.1023/A:1013844811137
|
| [23] |
D. Steinley, K-means clustering: A half-century synthesis, Br. J. Math. Stat. Psychol., 59 (2006), 1-34. doi: 10.1348/000711005X48266
|
| [24] |
H. S. Park, C. H. Jun, A simple and fast algorithm for K-medoids clustering, Expert Syst. Appl., 36 (2009), 3336-3341. doi: 10.1016/j.eswa.2008.01.039
|
| [25] |
T. Kurita, An efficient agglomerative clustering algorithm using a heap, Pattern Recognit., 24 (1991), 205-209. doi: 10.1016/0031-3203(91)90062-A
|
| [26] |
T. Zhang, R. Ramakrishnan, M. Livny, BIRCH: An efficient data clustering method for very large databases, ACM Sigmod Rec., 25 (1996), 103-114. doi: 10.1145/235968.233324
|
| [27] |
U. Von Luxburg, A tutorial on spectral clustering, Stat. Comput., 17 (2007), 395-416. doi: 10.1007/s11222-007-9033-z
|
| [28] |
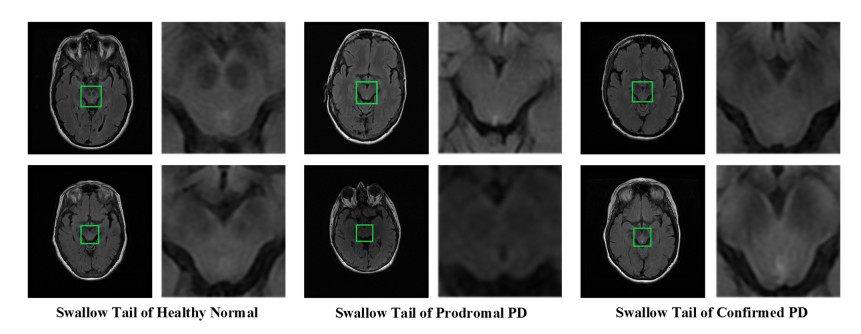
N. Wang, H. Yang, C. Li, G. Fan, X. Luo, Using 'swallow-tail' sign and putaminal hypointensity as biomarkers to distinguish multiple system atrophy from idiopathic Parkinson's disease: A susceptibility-weighted imaging study, Eur. Radiol., 27 (2017), 3174-3180. doi: 10.1007/s00330-017-4743-x
|
| [29] | K. Machhale, H. B. Nandpuru, V Kapuret, L. Kosta, MRI brain cancer classification using hybrid classifier (SVM-KNN), 2015 International Conference on Industrial Instrumentation and Control (ICIC), 2015, 60-65. Available from: https://ieeexplore.ieee.org/abstract/document/7150592. |
| [30] | P. Refaeilzadeh, L. Tang, H. Liu, Cross-validation, E. Database Sys., 5 (2009), 532-538. |
| [31] | M. Kirby, Geometric data analysis: An empirical approach to dimensionality reduction and the study of patterns, John Wiley Sons, Inc., New York, NY, USA, 2001. |
| [32] |
K. Honda, H. Ichihashi, Fuzzy local independent component analysis with external criteria and its application to knowledge discovery in databases, Int. J. Approximate Reasoning, 42 (2006), 159-173. doi: 10.1016/j.ijar.2005.10.011
|
| [33] | D. Donoho, V. Stodden, When does non-negative matrix factorization give a correct decomposition into parts?, Proceedings of the 16th International Conference on Neural Information Processing Systems, 2003, 1141-1148. Available from: http://papers.nips.cc/paper/2463-when-does-non-negative-matrix-factorization-give-a-correct-decomposition-into-parts.pdf. |
| [34] | A. Tharwat, Principal component analysis-a tutorial, Inderscience Enterprises Ltd, 3 (2016), 197-240. |
| [35] | T. Hastie, R. Tibshirani, Discriminant analysis by Gaussian mixtures, J. R. Stat. Soc. Series B, 58 (1996), 155-176. |
| [36] |
G. E. Hinton, R. R. Salakhutdinov, Reducing the dimensionality of data with neural networks, Science, 313 (2006), 504-507. doi: 10.1126/science.1127647
|
| [37] | S. Mika, G. Ratsch, J. Weston, B. Scholkopf, K. R. Mullers, Fisher discriminant analysis with kernels, Proceedings of the 1999 IEEE Signal Processing Society Workshop, Madison, 1999, 41-48. Available from: https://ieeexplore.ieee.org/abstract/document/788121. |
| [38] |
Y. Yang, H. Wang, Multi-view clustering: A survey, Big Data Mining Anal., 1 (2018), 83-107. doi: 10.26599/BDMA.2018.9020003
|
| [39] |
U. Maulik, S. Bandyopadhyay, Performance evaluation of some clustering algorithms and validity indices, IEEE Trans. Pattern Anal. Mach. Intell., 24 (2002), 1650-1654. doi: 10.1109/TPAMI.2002.1114856
|
Figures(8) / Tables(4)

Xiaobo Zhang, Donghai Zhai, Yan Yang, Yiling Zhang, Chunlin Wang. A novel semi-supervised multi-view clustering framework for screening Parkinson's disease[J]. Mathematical Biosciences and Engineering, 2020, 17(4): 3395-3411. doi: 10.3934/mbe.2020192







 DownLoad:
DownLoad: