Due to the lack of prior knowledge of face images, large illumination changes, and complex backgrounds, the accuracy of face recognition is low. To address this issue, we propose a face detection and recognition algorithm based on multi-task convolutional neural network (MTCNN).
In our paper, MTCNN mainly uses three cascaded networks, and adopts the idea of candidate box plus classifier to perform fast and efficient face recognition. The model is trained on a database of 50 faces we have collected, and Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index Measurement (SSIM), and receiver operating characteristic (ROC) curve are used to analyse MTCNN, Region-CNN (R-CNN) and Faster R-CNN.
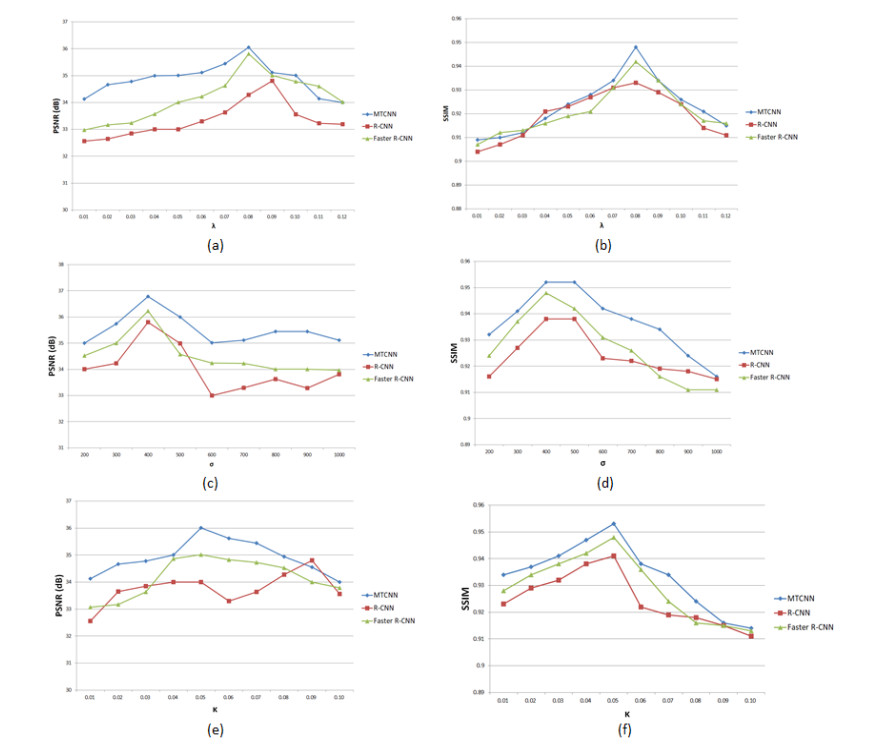
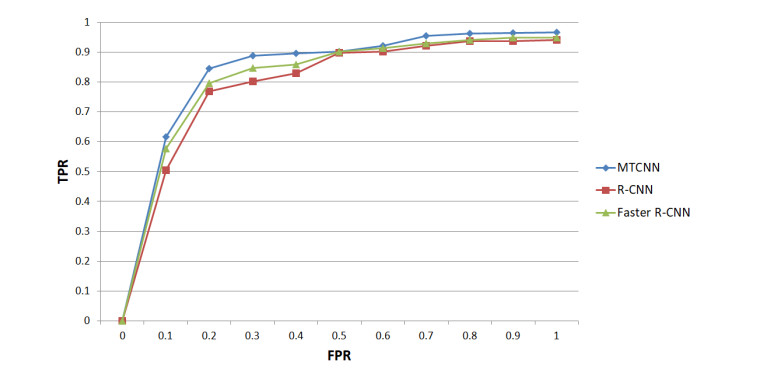
The average PSNR of this technique is 1.24 dB higher than that of R-CNN and 0.94 dB higher than that of Faster R-CNN. The average SSIM value of MTCNN is 10.3% higher than R-CNN and 8.7% higher than Faster R-CNN. The Area Under Curve (AUC) of MTCNN is 97.56%, the AUC of R-CNN is 91.24%, and the AUC of Faster R-CNN is 92.01%. MTCNN has the best comprehensive performance in face recognition. For the face images with defective features, MTCNN still has the best effect.
This algorithm can effectively improve face recognition to a certain extent. The accuracy rate and the reduction of the false detection rate of face detection can not only be better used in key places, ensure the safety of property and security of the people, improve safety, but also better reduce the waste of human resources and improve efficiency.
Citation: Huilin Ge, Yuewei Dai, Zhiyu Zhu, Biao Wang. Robust face recognition based on multi-task convolutional neural network[J]. Mathematical Biosciences and Engineering, 2021, 18(5): 6638-6651. doi: 10.3934/mbe.2021329
Due to the lack of prior knowledge of face images, large illumination changes, and complex backgrounds, the accuracy of face recognition is low. To address this issue, we propose a face detection and recognition algorithm based on multi-task convolutional neural network (MTCNN).
In our paper, MTCNN mainly uses three cascaded networks, and adopts the idea of candidate box plus classifier to perform fast and efficient face recognition. The model is trained on a database of 50 faces we have collected, and Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index Measurement (SSIM), and receiver operating characteristic (ROC) curve are used to analyse MTCNN, Region-CNN (R-CNN) and Faster R-CNN.
The average PSNR of this technique is 1.24 dB higher than that of R-CNN and 0.94 dB higher than that of Faster R-CNN. The average SSIM value of MTCNN is 10.3% higher than R-CNN and 8.7% higher than Faster R-CNN. The Area Under Curve (AUC) of MTCNN is 97.56%, the AUC of R-CNN is 91.24%, and the AUC of Faster R-CNN is 92.01%. MTCNN has the best comprehensive performance in face recognition. For the face images with defective features, MTCNN still has the best effect.
This algorithm can effectively improve face recognition to a certain extent. The accuracy rate and the reduction of the false detection rate of face detection can not only be better used in key places, ensure the safety of property and security of the people, improve safety, but also better reduce the waste of human resources and improve efficiency.

| [1] | C Fernández, M. A. Vicente, M. O. Martínez-Rach, Implementation of a face recognition system as experimental practices in an artificial intelligence and pattern recognition course, Comput. Appl. Eng. Educ., 12 (2020), 48-50. |
| [2] | J. X. Zeng, P. Chen, J. Q. Tian, X. Fu, Fuzzy kernel two-dimensional principal component analysis for face recognition, AICA, 2015. |
| [3] | D. C. Wise, Face recognition under expressions and lighting variations using artificial intelligence and image synthesizing, JCER, 2 (2012), 186-190. |
| [4] | H. Chakraborty, V. Balasubramanian, S. Panchanathan, Generalized batch mode active learning for face-based biometric recognition, Pattern Recognit., 23 (2013), 134-140. |
| [5] | P. M. Shende, M. V. Sarode, M. M. Ghonge, A survey based on fingerprint, face and iris biometric recognition system, image quality assessment and fake biometric, Int. J. Comput. Sci. Eng., 25 (2014), 221-225. |
| [6] | D. Sharma, A. Kumar, An empirical analysis over the four different feature-based face and iris biometric recognition tech, Int. Jrnl. Adv. Comput. Sci. Appl., 3 (2012), 1-13. |
| [7] | F. W. Wheeler, X. Liu, P. H. Tu, R. T. Hoctor, Multi-frame image restoration for face recognition, in IEEE Workshop on Signal Processing Applications for Public Security & Forensics, 2007. |
| [8] | Z. Liu, H. Zhang, S. Wang, W. Hong, J. Ma, Y. He, Reliability evaluation of public security face recognition system based on continuous bayesian network, Math. Probl. Eng., 3 (2020), 1-9. |
| [9] | D. Li, X. Zhang, L. S. Yi, X. Zhao, Multiple-step model training for face recognition, Int. Conf. Appl. Tech. Cyber. Sec. Int., 2017. |
| [10] | B. S. Satari, N. Rahman, Z. Abidin, Face recognition for security efficiency in managing and monitoring visitors of an organization, in 2014 ISBAST, 2014. |
| [11] | Q. Liang, W. Fang, College student attendance system based on face recognition, Iop. Conf., 2018. |
| [12] | S. Kasaei, S. A. Monadjemi, K. Jamshidi, Application of the face recognition procedure in citizenship and immigration management system, Int. J. Electron. Comput. Eng. Syst., (2014), 611-614. |
| [13] | Z. Zhang, Design plan of dormitory name management system based on face recognition, China Commun., 12 (2018), 220-230. |
| [14] |
K. K. L. Wong, G. Fortino, D. Abbott, Deep learning-based cardiovascular image diagnosis: A promising challenge, Future Gener Comput. Syst., 110 (2020), 802-811. doi: 10.1016/j.future.2019.09.047

|
| [15] | W. Wang, J. Yang, J. Xiao, S. Li, D. Zhou, Face recognition based on deep learning, Int. Conf. Pervas. Comput. Appl., 2014. |
| [16] | K. Grm, V. Štruc, A. Artiges, M. Caron, H. K. Ekenel., Strengths and weaknesses of deep learning models for face recognition against image degradations, Iet. Biom., 7 (2018), 81-89. |
| [17] | J. Zhao, Y. Lv, Z. Zhou, F. Cao, A novel deep learning algorithm for incomplete face recognition: Low-rank-recovery network, Neural Netw., 13(2017), 94. |
| [18] |
C. Dong, C. C. Loy, K. He, X. Tang, Image super-resolution using deep convolutional networks, IEEE Trans Pattern Anal. Mach. Int., 38 (2016), 295-307. doi: 10.1109/TPAMI.2015.2439281
|
| [19] | J. Kim, J. K. Lee, K. M. Lee, Accurate image super-resolution using very deep convolutional networks, IEEE Conf. Comp. Vis. Pat. Recognit. IEEE, 2016. |
| [20] | X. Yu, F. Porikli, Face hallucination with tiny unaligned images by transformative discriminative neural networks, 31st AAAI Conf. Art. Int., 2017. |
| [21] | J. Li, F. Fang, K. Mei, G. Zhang, Multi-scale residual network for image super-resolution, ECCV, 2018. |
| [22] | J. Xiang, G, Zhu, Joint face detection and facial expression recognition with Mtcnn, Int. Conf. Infor. Sci. Control Eng. IEEE Comp. Soc., (2017), 424-427. |
| [23] | E. Jose, M. Greeshma, M. T. Haridas, M. H. Supriya, Face recognition based surveillance system using faceNet and Mtcnn on jetson TX2, in 2019 5th ICACCS, IEEE, 2019. |
| [24] |
C. Wu, Y. Zhang, Mtcnn and facenet based access control system for face detection and recognition, Autom. Control. Comput. Sci., 55 (2021), 102-112. doi: 10.3103/S0146411621010090
|
| [25] |
L. H. Ma, H. Y. Fan, Z. M. Lu, D. Tian, Acceleration of multi-task cascaded convolutional networks, IET Image Process., 14 (2020), 2435-2441. doi: 10.1049/iet-ipr.2019.0141
|
| [26] | X. Zhao, S. Lin, X. Chen, C. Ou, C. Liao, Application of face image detection based on deep learning in privacy security of intelligent cloud platform, Multimed. Tools Appl., 79 (2020), 205-210. |
| [27] |
H. Chen, Y. Chen, X. Tian, R. Jiang, A cascade face spoofing detector based on face anti-spoofing R-CNN and improved retinex LBP, IEEE Access, 7 (2019), 170116-170133. doi: 10.1109/ACCESS.2019.2955383
|
| [28] | X. Qin, Y. Zhou, Z. He, Y. Wang, Z. Tang, A faster R-CNN based method for comic characters face detection, in 2017 14th ICDAR IEEE Computer Society, 2017. |
| [29] | L. J. Halawa, A. Wibowo, F. Ernawan, Face recognition using faster R-CNN with inception-V2 architecture for CCTV camera, in 2019 3rd ICICoS, 2019. |
| [30] | T. Hofmann, B. Schölkopf, A. J. Smola, Kernel methods in machine learning, Ann. Stat., (2008), 1171-1220. |
| [31] | Y. Q. Bai, M. E. Ghami, C. Roos, A comparative study of kernel functions for primal-dual interior-point algorithms in linear optimization, SIAM J. Optim., 15 (2014), 101-128. |
| [32] |
A. R. Webb, An approach to non-linear principal components analysis using radially symmetric kernel functions, Stat. Comput., 6 (1996), 159-168. doi: 10.1007/BF00162527
|
| [33] | E. H. Lieb, Gaussian kernels have only gaussian maximizers, Inv. Math., 102 (1990), 9-208. |
| [34] |
L. Jiang, B. Zhu, X. Rao, G. Berney, Y. Tao, Discrimination of black walnut shell and pulp in hyperspectral fluorescence imagery using Gaussian kernel function approach, J. Food Eng., 81 (2007), 108-117. doi: 10.1016/j.jfoodeng.2006.10.023
|
| [35] |
D. S. Turaga, Y. Chen, J. Caviedes, No reference PSNR estimation for compressed pictures, Signal Process. Image Commun., 19 (2004), 173-184. doi: 10.1016/j.image.2003.09.001
|
| [36] | H. Alain, D. Ziou, Image quality metrics: PSNR vs. SSIM, 20th Int. Conf. Pat. Recognit. IEEE, 2010. |
| [37] |
Z. Tang, G. Zhao, T. Ouyang, Two-phase deep learning model for short-term wind direction forecasting, Renew. Energy, 173 (2021), 1005-1016. doi: 10.1016/j.renene.2021.04.041
|
| [38] | K. Lan, S. Fong, L. S. Liu, R. K. Wong, N. Dey, R. C. Millham, et al, A clustering based variable sub-window approach using particle swarm optimisation for biomedical sensor data monitoring, Enterp. Inf. Syst., 15 (2021), 15-35. |
| [39] |
T. Li, S. Fong, K. K. L. Wong, Y. Wu, X. Yang, X. Li, Fusing wearable and remote sensing data streams by fast incremental learning with swarm decision table for human activity recognition, Inf. Fusion, 60 (2020), 41-64. doi: 10.1016/j.inffus.2020.02.001
|

Figures(7) / Tables(2)

Huilin Ge, Yuewei Dai, Zhiyu Zhu, Biao Wang. Robust face recognition based on multi-task convolutional neural network[J]. Mathematical Biosciences and Engineering, 2021, 18(5): 6638-6651. doi: 10.3934/mbe.2021329







 DownLoad:
DownLoad: