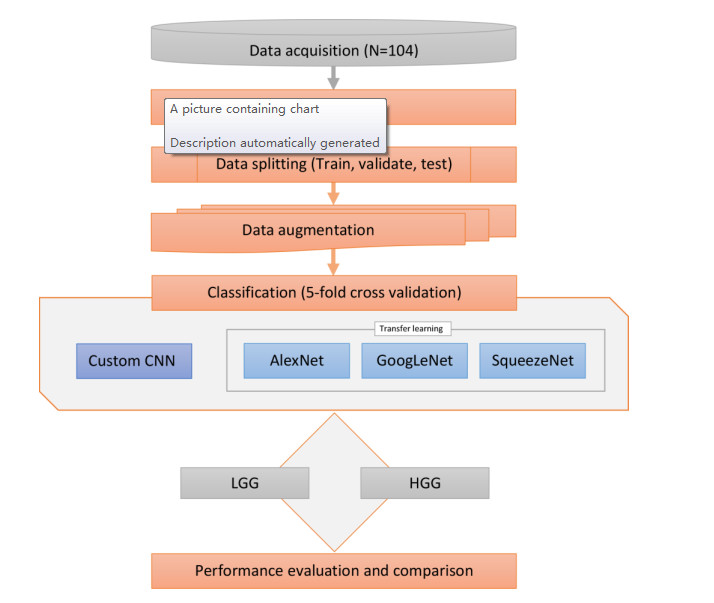
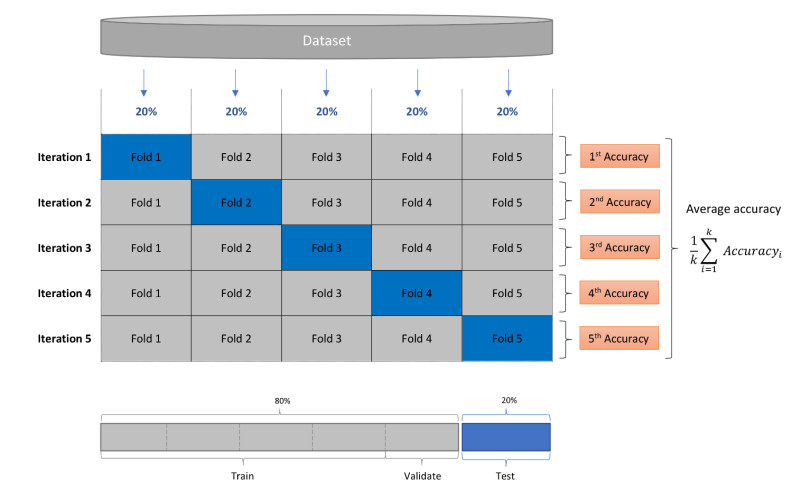
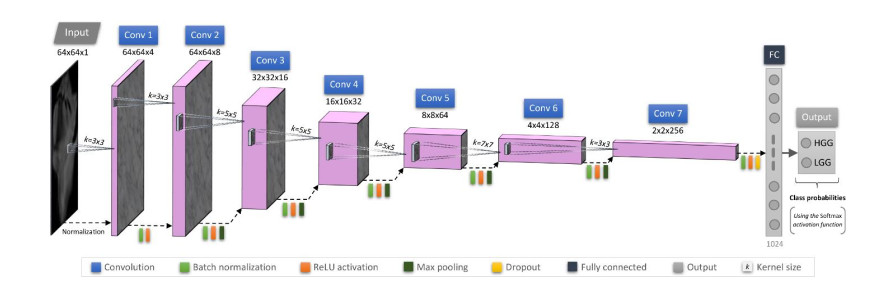
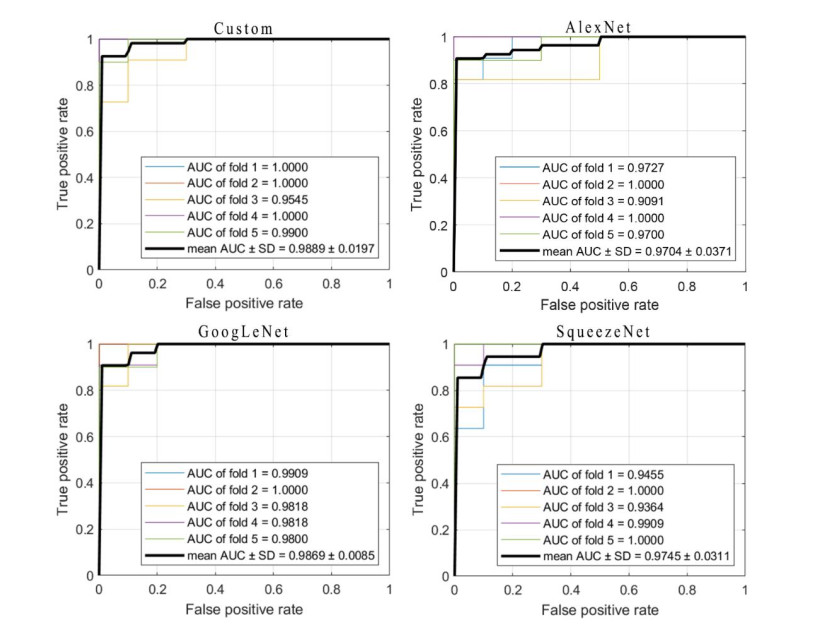
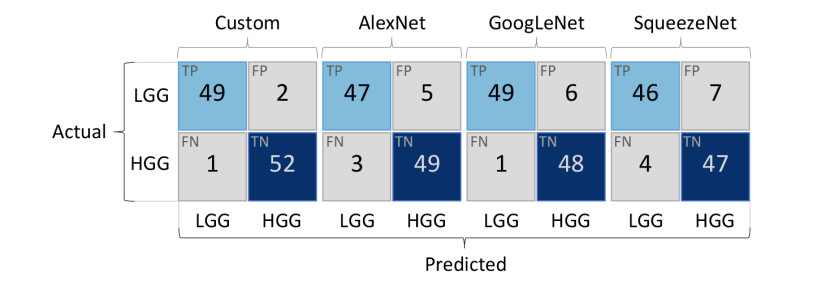
Gliomas are a type of central nervous system (CNS) tumor that accounts for the most of malignant brain tumors. The World Health Organization (WHO) divides gliomas into four grades based on the degree of malignancy. Gliomas of grades I-II are considered low-grade gliomas (LGGs), whereas gliomas of grades III-IV are termed high-grade gliomas (HGGs). Accurate classification of HGGs and LGGs prior to malignant transformation plays a crucial role in treatment planning. Magnetic resonance imaging (MRI) is the cornerstone for glioma diagnosis. However, examination of MRI data is a time-consuming process and error prone due to human intervention. In this study we introduced a custom convolutional neural network (CNN) based deep learning model trained from scratch and compared the performance with pretrained AlexNet, GoogLeNet and SqueezeNet through transfer learning for an effective glioma grade prediction. We trained and tested the models based on pathology-proven 104 clinical cases with glioma (50 LGGs, 54 HGGs). A combination of data augmentation techniques was used to expand the training data. Five-fold cross-validation was applied to evaluate the performance of each model. We compared the models in terms of averaged values of sensitivity, specificity, F1 score, accuracy, and area under the receiver operating characteristic curve (AUC). According to the experimental results, our custom-design deep CNN model achieved comparable or even better performance than the pretrained models. Sensitivity, specificity, F1 score, accuracy and AUC values of the custom model were 0.980, 0.963, 0.970, 0.971 and 0.989, respectively. GoogLeNet showed better performance than AlexNet and SqueezeNet in terms of accuracy and AUC with a sensitivity, specificity, F1 score, accuracy, and AUC values of 0.980, 0.889, 0.933, 0.933, and 0.987, respectively. AlexNet yielded a sensitivity, specificity, F1 score, accuracy, and AUC values of 0.940, 0.907, 0.922, 0.923 and 0.970, respectively. As for SqueezeNet, the sensitivity, specificity, F1 score, accuracy, and AUC values were 0.920, 0.870, 0.893, 0.894, and 0.975, respectively. The results have shown the effectiveness and robustness of the proposed custom model in classifying gliomas into LGG and HGG. The findings suggest that the deep CNNs and transfer learning approaches can be very useful to solve classification problems in the medical domain.
Citation: Hakan Özcan, Bülent Gürsel Emiroğlu, Hakan Sabuncuoğlu, Selçuk Özdoğan, Ahmet Soyer, Tahsin Saygı. A comparative study for glioma classification using deep convolutional neural networks[J]. Mathematical Biosciences and Engineering, 2021, 18(2): 1550-1572. doi: 10.3934/mbe.2021080
Gliomas are a type of central nervous system (CNS) tumor that accounts for the most of malignant brain tumors. The World Health Organization (WHO) divides gliomas into four grades based on the degree of malignancy. Gliomas of grades I-II are considered low-grade gliomas (LGGs), whereas gliomas of grades III-IV are termed high-grade gliomas (HGGs). Accurate classification of HGGs and LGGs prior to malignant transformation plays a crucial role in treatment planning. Magnetic resonance imaging (MRI) is the cornerstone for glioma diagnosis. However, examination of MRI data is a time-consuming process and error prone due to human intervention. In this study we introduced a custom convolutional neural network (CNN) based deep learning model trained from scratch and compared the performance with pretrained AlexNet, GoogLeNet and SqueezeNet through transfer learning for an effective glioma grade prediction. We trained and tested the models based on pathology-proven 104 clinical cases with glioma (50 LGGs, 54 HGGs). A combination of data augmentation techniques was used to expand the training data. Five-fold cross-validation was applied to evaluate the performance of each model. We compared the models in terms of averaged values of sensitivity, specificity, F1 score, accuracy, and area under the receiver operating characteristic curve (AUC). According to the experimental results, our custom-design deep CNN model achieved comparable or even better performance than the pretrained models. Sensitivity, specificity, F1 score, accuracy and AUC values of the custom model were 0.980, 0.963, 0.970, 0.971 and 0.989, respectively. GoogLeNet showed better performance than AlexNet and SqueezeNet in terms of accuracy and AUC with a sensitivity, specificity, F1 score, accuracy, and AUC values of 0.980, 0.889, 0.933, 0.933, and 0.987, respectively. AlexNet yielded a sensitivity, specificity, F1 score, accuracy, and AUC values of 0.940, 0.907, 0.922, 0.923 and 0.970, respectively. As for SqueezeNet, the sensitivity, specificity, F1 score, accuracy, and AUC values were 0.920, 0.870, 0.893, 0.894, and 0.975, respectively. The results have shown the effectiveness and robustness of the proposed custom model in classifying gliomas into LGG and HGG. The findings suggest that the deep CNNs and transfer learning approaches can be very useful to solve classification problems in the medical domain.

| [1] |
R. Chen, M. Smith-Cohn, A. L. Cohen, H. Colman, Glioma subclassifications and their clinical significance, Neurotherapeutics, 14 (2017), 284-297. doi: 10.1007/s13311-017-0519-x

|
| [2] |
Y.-C. Liu, Y. Wang, Role of yes-associated protein 1 in gliomas: Pathologic and therapeutic aspects, Tumor Biol., 36 (2015), 2223-2227. doi: 10.1007/s13277-015-3297-2
|
| [3] | D. Persaud-Sharma, J. Burns, J. Trangle, S. Moulik, Disparities in brain cancer in the united states: A literature review of gliomas, Med. Sci. Basel Switz., 5 (2017), 16. |
| [4] | D. N. Louis, A. Perry, G. Reifenberger, A. von Deimling, D. Figarella-Branger, W. K. Cavenee, et al., The 2016 World Health Organization classification of tumors of the central nervous system: A summary, Acta Neuropathol., 131 (2016), 803-820. |
| [5] | C. Walker, A. Baborie, D. Crooks, S. Wilkins, M. D. Jenkinson, Biology, genetics and imaging of glial cell tumours, Br. J. Radiol., 84 (2011), S90-S106. |
| [6] | F. Dhermain, Radiotherapy of high-grade gliomas: current standards and new concepts, innovations in imaging and radiotherapy, and new therapeutic approaches, Chin. J. Cancer, 33 (2014), 16-24. |
| [7] | E. M. Sizoo, L. Braam, T. J. Postma, H. R. W. Pasman, J. J. Heimans, M. Klein, et al., Symptoms and problems in the end-of-life phase of high-grade glioma patients, Neuro-Oncol., 12 (2010), 1162-1166. |
| [8] | R. Stupp, W. P. Mason, M. J. van den Bent, M. Weller, B. Fisher, M. J. B. Taphoorn, et al., Radiotherapy plus concomitant and adjuvant temozolomide for glioblastoma, N. Engl. J. Med., 352 (2005), 987-996. |
| [9] | Q. T. Ostrom, L. Bauchet, F. G. Davis, I. Deltour, J. L. Fisher, C. E. Langer, et al., The epidemiology of glioma in adults: A "state of the science" review, Neuro-Oncol., 16 (2014), 896-913. |
| [10] | E. B. Claus, K. M. Walsh, J. K. Wiencke, A. M. Molinaro, J. L. Wiemels, J. M. Schildkraut, et al., Survival and low-grade glioma: The emergence of genetic information, Neurosurg. Focus, 38 (2015), E6. |
| [11] |
K. S. Patel, B. S. Carter, C. C. Chen, Role of biopsies in the management of intracranial gliomas, Prog. Neurol. Surg., 30 (2018), 232-243. doi: 10.1159/000464439
|
| [12] | R. J. Jackson, G. N. Fuller, D. Abi-Said, F. F. Lang, Z. L. Gokaslan, W. M. Shi, et al., Limitations of stereotactic biopsy in the initial management of gliomas, Neuro-Oncol., 3 (2001), 193-200. |
| [13] |
M. Preusser, K. Aldape, E. Gerstner, W. Pope, M. Viapiano, Highlights from the literature, Neuro-Oncol., 19 (2017), 1154-1157. doi: 10.1093/neuonc/nox137
|
| [14] | J. Zhang, H. Liu, H. Tong, S. Wang, Y. Yang, G. Liu, et al., Clinical applications of contrast-enhanced perfusion MRI techniques in gliomas: Recent advances and current challenges, Contrast Media Mol. Imaging, 2017 (2017), 1-27. |
| [15] |
E. Moser, A. Stadlbauer, C. Windischberger, H. H. Quick, M. E. Ladd, Magnetic resonance imaging methodology, Eur. J. Nucl. Med. Mol. Imaging, 36 (2009), 30-41. doi: 10.1007/s00259-008-0938-3
|
| [16] | A. Patra, A. Janu, A. Sahu, MR Imaging in neurocritical care, Indian J. Crit. Care Med. Peer-Rev. Off. Publ. Indian Soc. Crit. Care Med., 23 (2019), S104-S114. |
| [17] |
S. Waite, J. Scott, B. Gale, T. Fuchs, S. Kolla, D. Reede, Interpretive error in radiology, Am. J. Roentgenol., 208 (2017), 739-749. doi: 10.2214/AJR.16.16963
|
| [18] | F. Caranci, E. Tedeschi, G. Leone, A. Reginelli, G. Gatta, A. Pinto, et al., Errors in neuroradiology, Radiol. Med., 120 (2015), 795-801. |
| [19] | Y. Kang, S. H. Choi, Y.-J. Kim, K. G. Kim, C.-H. Sohn, J.-H. Kim, et al., Gliomas: Histogram analysis of apparent diffusion coefficient maps with standard- or high-b-value diffusion-weighted MR imaging--correlation with tumor grade, Radiology, 261 (2011), 882-890. |
| [20] |
G. Ranjith, R. Parvathy, V. Vikas, K. Chandrasekharan, S. Nair, Machine learning methods for the classification of gliomas: Initial results using features extracted from MR spectroscopy, Neuroradiol. J., 28 (2015), 106-111. doi: 10.1177/1971400915576637
|
| [21] | F. P. Polly, S. K. Shil, M. A. Hossain, A. Ayman, Y. M. Jang, Detection and classification of HGG and LGG brain tumor using machine learning, Proceedings of the 32nd International Conference on Information Networking, Thailand, 2018. |
| [22] | Q. Tian, L.-F. Yan, X. Zhang, X. Zhang, Y.-C. Hu, Y. Han, et al., Radiomics strategy for glioma grading using texture features from multiparametric MRI: Radiomics approach for glioma grading, J. Magn. Reson. Imaging, 48 (2018), 1518-1528. |
| [23] | X. Bi, J. G. Liu, Y. S. Cao, Classification of low-grade and high-grade glioma using multiparametric radiomics model, Proceedings of the 3rd IEEE Information Technology, Networking, Electronic and Automation Control Conference, China, 2019. |
| [24] | G. Cui, J. Jeong, B. Press, Y. Lei, H.-K. Shu, T. Liu, et al., Machine-learning-based classification of lower-grade gliomas and high-grade gliomas using radiomic features in multi-parametric MRI, preprint, arXiv: 1911.10145. |
| [25] | A. S. Lundervold, A. Lundervold, An overview of deep learning in medical imaging focusing on MRI, Z. Phys., 29 (2019), 102-127. |
| [26] |
K. Fukushima, A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position, Biol. Cybern., 36 (1980), 193-202. doi: 10.1007/BF00344251
|
| [27] |
J. Gao, Q. Jiang, B. Zhou, D. Chen, Convolutional neural networks for computer-aided detection or diagnosis in medical image analysis: an overview, Math. Biosci. Eng., 16 (2019), 6536-6561. doi: 10.3934/mbe.2019326
|
| [28] | J. Yosinski, J. Clune, Y. Bengio, H. Lipson, How transferable are features in deep neural networks?, preprint, arXiv: 1411.1792. |
| [29] | E. I. Zacharaki, S. Wang, S. Chawla, D. Soo Yoo, R. Wolf, E. R. Melhem, et al., Classification of brain tumor type and grade using MRI texture and shape in a machine learning scheme, Magn. Reson. Med., 62 (2009), 1609-1618. |
| [30] | A. Ditmer, B. Zhang, T. Shujaat, A. Pavlina, N. Luibrand, M. Gaskill-Shipley, et al., Diagnostic accuracy of MRI texture analysis for grading gliomas, J. Neurooncol., 140 (2018), 583-589. |
| [31] | S. Banerjee, S. Mitra, F. Masulli, S. Rovetta, Deep radiomics for brain tumor detection and classification from multi-sequence MRI, preprint, arXiv: 1903.09240. |
| [32] | Y. Zhuge, H. Ning, P. Mathen, J. Y. Cheng, A. V. Krauze, K. Camphausen, et al., Automated glioma grading on conventional MRI images using deep convolutional neural networks, Med. Phys., 47 (2020), 3044-3053. |
| [33] |
E. Lotan, R. Jain, N. Razavian, G. M. Fatterpekar, Y. W. Lui, State of the art: Machine learning applications in glioma imaging, Am. J. Roentgenol., 212 (2019), 26-37. doi: 10.2214/AJR.18.20218
|
| [34] |
P. Korfiatis, B. Erickson, Deep learning can see the unseeable: Predicting molecular markers from MRI of brain gliomas, Clin. Radiol., 74 (2019), 367-373. doi: 10.1016/j.crad.2019.01.028
|
| [35] |
R. Takahashi, T. Matsubara, K. Uehara, Data augmentation using random image cropping and patching for deep CNNs, IEEE Trans. Circuits Syst. Video Technol., 30 (2020), 2917-2931. doi: 10.1109/TCSVT.2019.2935128
|
| [36] | J. Ding, X. Li, X. Kang, V. N. Gudivada, A case study of the augmentation and evaluation of training data for deep learning, J. Data Inf. Qual., 11 (2019), 1-22. |
| [37] | O. Fink, Q. Wang, M. Svensén, P. Dersin, W.-J. Lee, M. Ducoffe, Potential, challenges and future directions for deep learning in prognostics and health management applications, Eng. Appl. Artif. Intell., 92 (2020), 103678. |
| [38] | M. D. Bloice, C. Stocker, A. Holzinger, Augmentor: An image augmentation library for machine learning, preprint, arXiv: 1708.04680. |
| [39] | G. Liu, K. J. Shih, T.-C. Wang, F. A. Reda, K. Sapra, Z. Yu, et al., Partial convolution based padding, preprint, arXiv: 1811.11718. |
| [40] | S. Ioffe, C. Szegedy, Batch normalization: Accelerating deep network training by reducing internal covariate shift, preprint, arXiv: 1502.03167. |
| [41] | J. L. Ba, J. R. Kiros, G. E. Hinton, Layer normalization, preprint, arXiv: 1607.06450. |
| [42] | K. He, X. Zhang, S. Ren, J. Sun, Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification, preprint, arXiv: 1502.01852. |
| [43] | B. Xu, N. Wang, T. Chen, M. Li, Empirical evaluation of rectified activations in convolutional network, preprint, arXiv: 1505.00853. |
| [44] | C. Banerjee, T. Mukherjee, E. Pasiliao, An empirical study on generalizations of the ReLU activation function, Proceedings of the 20th ACM Conference on Economics and Computation, USA, 2019. |
| [45] | M. Ranzato, F. J. Huang, Y.-L. Boureau, Y. LeCun, Unsupervised learning of invariant feature hierarchies with applications to object recognition, Proceedings of the 25th IEEE Conference on Computer Vision and Pattern Recognition, USA, 2007. |
| [46] | N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, R. Salakhutdinov, Dropout: A simple way to prevent neural networks from overfitting, J. Mach. Learn. Res., 15 (2014), 1929-1958. |
| [47] | L. Bottou, Stochastic gradient descent tricks, in Neural Networks: Tricks of the Trade, (eds. G. Montavon, G. B. Orr, and K.-R. Müller), Springer Berlin Heidelberg, (2012), 421-436. |
| [48] | J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, L. Fei-Fei, ImageNet: A large-scale hierarchical image database, Proceedings of the 27th IEEE Conference on Computer Vision and Pattern Recognition, USA, 2009. |
| [49] |
A. Krizhevsky, I. Sutskever, G. E. Hinton, ImageNet classification with deep convolutional neural networks, Commun. ACM, 60 (2017), 84-90. doi: 10.1145/3065386
|
| [50] | C. Szegedy, Wei Liu, Yangqing Jia, P. Sermanet, S. Reed, D. Anguelov, et al., Going deeper with convolutions, Proceedings of the 28th IEEE Conference on Computer Vision and Pattern Recognition, USA, 2015. |
| [51] | F. N. Iandola, S. Han, M. W. Moskewicz, K. Ashraf, W. J. Dally, K. Keutzer, SqueezeNet: AlexNet-level accuracy with 50×fewer parameters and < 0.5mb model size, preprint, arXiv: 1602.07360. |
| [52] | G. Raskutti, M. J. Wainwright, B. Yu, Early stopping and non-parametric regression: An optimal data-dependent stopping rule, J. Mach. Learn. Res., 15 (2014), 335-266. |
| [53] | L. Prechelt, Early stopping - but when?, in Neural Networks: Tricks of the Trade, (eds. G. B. Orr and K.-R. Müller), Springer Berlin Heidelberg, (1998), 55-69. |
| [54] |
J. A. Hanley, B. J. McNeil, The meaning and use of the area under a receiver operating characteristic (ROC) curve., Radiology, 143 (1982), 29-36. doi: 10.1148/radiology.143.1.7063747
|



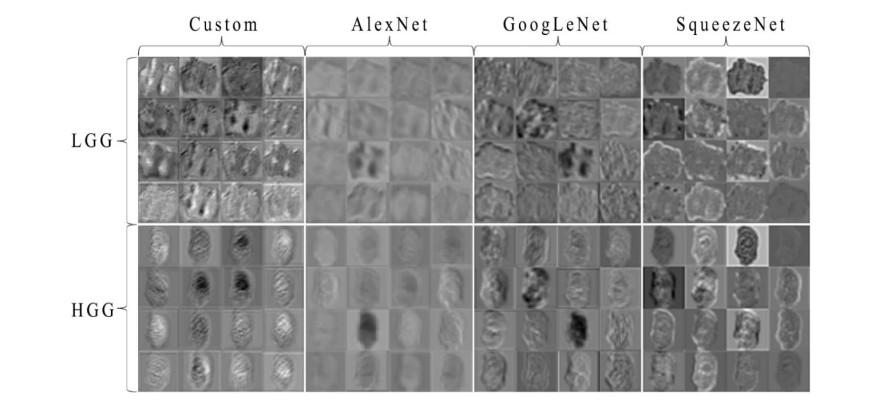
Figures(12) / Tables(6)

Hakan Özcan, Bülent Gürsel Emiroğlu, Hakan Sabuncuoğlu, Selçuk Özdoğan, Ahmet Soyer, Tahsin Saygı. A comparative study for glioma classification using deep convolutional neural networks[J]. Mathematical Biosciences and Engineering, 2021, 18(2): 1550-1572. doi: 10.3934/mbe.2021080







 DownLoad:
DownLoad: