Citation: Sisi Qi, Youyu Sheng, Ruiming Hu, Feng Xu, Ying Miao, Jun Zhao, Qinping Yang. Genome-wide expression profiling of long non-coding RNAs and competing endogenous RNA networks in alopecia areata[J]. Mathematical Biosciences and Engineering, 2021, 18(1): 696-711. doi: 10.3934/mbe.2021037

| [1] | L. C. Strazzulla, E. H. C. Wang, L. Avila, K. Lo Sicco, N. Brinster, A. M. Christiano, et al., Alopecia areata: Disease characteristics, clinical evaluation, and new perspectives on pathogenesis, J. Am. Acad. Derm., 78 (2018), 1–12. |
| [2] | J. H. Lee, H. J. Kim, K. D. Han, J. H. Han, C. H. Bang, Y. M. Park, et al., Incidence and prevalence of alopecia areata according to subtype: A nationwide, population-based study in South Korea (2006–2015), Brit. J. Derm., (2019). |
| [3] |
E. Tan, Y. K. Tay, C. L. Goh, Y. Chin Giam, The pattern and profile of alopecia areata in Singapore--a study of 219 Asians, Int. J. Derm., 41 (2002), 748–753. doi: 10.1046/j.1365-4362.2002.01357.x

|
| [4] |
F. L. Xiao, S. Yang, J. B. Liu, P. P. He, J. Yang, Y. Cui, et al., The epidemiology of childhood alopecia areata in China: A study of 226 patients, Pediat. Derm., 23 (2006), 13–18. doi: 10.1111/j.1525-1470.2006.00161.x
|
| [5] |
S. Yang, J. Yang, J. B. Liu, H. Y. Wang, Q. Yang, M. Gao, et al., The genetic epidemiology of alopecia areata in China, Brit. J. Derm., 151 (2004), 16–23. doi: 10.1111/j.1365-2133.2004.05915.x
|
| [6] | L. Petukhova, A. V. Patel, R. K. Rigo, L. Bian, M. Verbitsky, S. S. Cherchi, et al., Integrative analysis of rare copy number variants and gene expression data in Alopecia Areata implicates an etiological role for autophagy, Exp. Dermatol., (2019). |
| [7] | Z. X. Lei, W. J. Chen, J. Q. Liang, Y. J. Wang, L. Jin, C. Xu, et al., The association between rs2476601 polymorphism in PTPN22 gene and risk of alopecia areata: A meta-analysis of case-control studies, Medicine (Baltimore), 98 (2019), e15448. |
| [8] |
T. R. Mercer, M. E. Dinger, J. S. Mattick, Long non-coding RNAs: Insights into functions, Nat. Rev. Genet., 10 (2009), 155–159. doi: 10.1038/nrg2521
|
| [9] |
V. Simion, S. Haemmig, M. W. Feinberg, LncRNAs in vascular biology and disease, Vascul. Pharmacol., 114 (2019), 145–156. doi: 10.1016/j.vph.2018.01.003
|
| [10] | L. Bao, A. Yu, Y. Luo, T. Tian, Y. Dong, H. Zong, et al., Genomewide differential expression profiling of long non-coding RNAs in androgenetic alopecia in a Chinese male population, J. Eur. Acad. Dermatol. Venereol., 31 (2017), 1360–1371. |
| [11] |
Y. Sheng, J. Ma, J. Zhao, S. Qi, R. Hu, Q. Yang, Differential expression patterns of specific long noncoding RNAs and competing endogenous RNA network in alopecia areata, J. Cell Biochem., 120 (2019), 10737–10747. doi: 10.1002/jcb.28365
|
| [12] |
S. Ghosh, C. K. Chan, Analysis of RNA-Seq data using TopHat and Cufflinks, Methods Mol. Biol., 1374 (2016), 339–361. doi: 10.1007/978-1-4939-3167-5_18
|
| [13] |
Y. Liao, G. K. Smyth, W. Shi, featureCounts: an efficient general purpose program for assigning sequence reads to genomic features, Bioinformatics, 30 (2014), 923–930. doi: 10.1093/bioinformatics/btt656
|
| [14] |
O. Nikolayeva, M. D. Robinson, edgeR for differential RNA-seq and ChIP-seq analysis: An application to stem cell biology, Methods Mol. Biol., 1150 (2014), 45–79. doi: 10.1007/978-1-4939-0512-6_3
|
| [15] |
M. D. Robinson, D. J. McCarthy, G. K. Smyth, edgeR: A Bioconductor package for differential expression analysis of digital gene expression data, Bioinformatics, 26 (2010), 139–140. doi: 10.1093/bioinformatics/btp616
|
| [16] |
G. Yu, L. G. Wang, Y. Han, Q. Y. He, clusterProfiler: An R package for comparing biological themes among gene clusters, OMICS, 16 (2012), 284–287. doi: 10.1089/omi.2011.0118
|
| [17] | M. Ashburner, C. A. Ball, J. A. Blake, D. Botstein, H. Butler, J. M. Cherry, et al., Gene ontology: Tool for the unification of biology. The Gene Ontology Consortium, Nat.Genet., 25 (2000), 25–29. |
| [18] |
M. Kanehisa, S. Goto, KEGG: Kyoto encyclopedia of genes and genomes, Nucl. Acids Res., 28 (2000), 27–30. doi: 10.1093/nar/28.1.27
|
| [19] | P. Shannon, A. Markiel, O. Ozier, N. S. Baliga, J. T. Wang, D. Ramage, et al., Cytoscape: A software environment for integrated models of biomolecular interaction networks, Genome Res., 13 (2003), 2498–2504. |
| [20] | H. Dweep, N. Gretz, miRWalk2.0: A comprehensive atlas of microRNA-target interactions, Nat. Methods, 12 (2015), 697. |
| [21] | S. Das, S. Ghosal, R. Sen, J. Chakrabarti, lnCeDB: Database of human long noncoding RNA acting as competing endogenous RNA, PLoS One, 9 (2014), e98965. |
| [22] |
Y. Tang, M. Li, J. Wang, Y. Pan, F. X. Wu, CytoNCA: A cytoscape plugin for centrality analysis and evaluation of protein interaction networks, Biosystems, 127 (2015), 67–72. doi: 10.1016/j.biosystems.2014.11.005
|
| [23] | T. Barrett, T. O. Suzek, D. B. Troup, S. E. Wilhite, W.-C. Ngau, P. Ledoux, et al., NCBI GEO: Mining millions of expression profiles—database and tools, Nucl. Acids Res., 33 (2005), D562–D566. |
| [24] | L. C. Tsoi, M. K. Iyer, P. E. Stuart, W. R. Swindell, J. E. Gudjonsson, T. Tejasvi, et al., Analysis of long non-coding RNAs highlights tissue-specific expression patterns and epigenetic profiles in normal and psoriatic skin, Genome Biol., 16 (2015), 24. |
| [25] | K. R. Sigdel, A. Cheng, Y. Wang, L. Duan, Y. Zhang, The emerging functions of Long Noncoding RNA in immune cells: Autoimmune diseases, J. Immunol. Res., 2015 (2015), 848790. |
| [26] | Y. M. Han, Y. Y. Sheng, F. Xu, S. S. Qi, X. J. Liu, R. M. Hu, et al., Imbalance of T-helper 17 and regulatory T cells in patients with alopecia areata, J. Dermatol., 42 (2015), 981–988. |
| [27] |
M. Hordinsky, D. H. Kaplan, Low-dose interleukin 2 to reverse alopecia areata, JAMA Dermatol., 150 (2014), 696–697. doi: 10.1001/jamadermatol.2014.510
|
| [28] |
H. Guo, Y. Cheng, J. Shapiro and K. McElwee, The role of lymphocytes in the development and treatment of alopecia areata, Expert Rev. Clin. Immunol., 11 (2015), 1335–1351. doi: 10.1586/1744666X.2015.1085306
|
| [29] | H. Chen, Z. Xu, X. Liu, Y. Gao, J. Wang, P. Qian, et al., Increased expression of Lncrna RP11-397A15.4 in gastric cancer and its clinical significance, Ann. Clin. Lab. Sci., 48 (2018), 707–711. |
| [30] | R. Huang, W. Nie, K. Yao, J. Chou, Depletion of the lncRNA RP11-567G11.1 inhibits pancreatic cancer progression, Biomed. Pharmacother., 112 (2019), 108685. |
| [31] | Y. Wu, X. Yang, Z. Chen, L. Tian, G. Jiang, F. Chen, et al., m(6)A-induced lncRNA RP11 triggers the dissemination of colorectal cancer cells via upregulation of Zeb1, Mol. Cancer, 18 (2019), 87. |
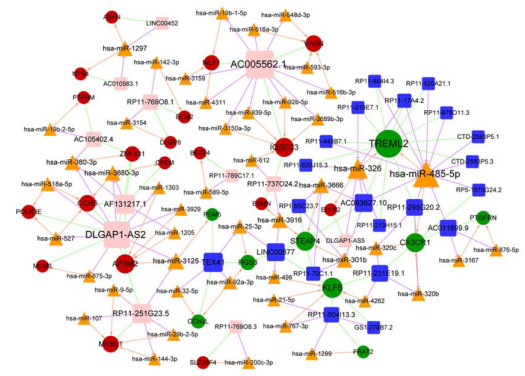
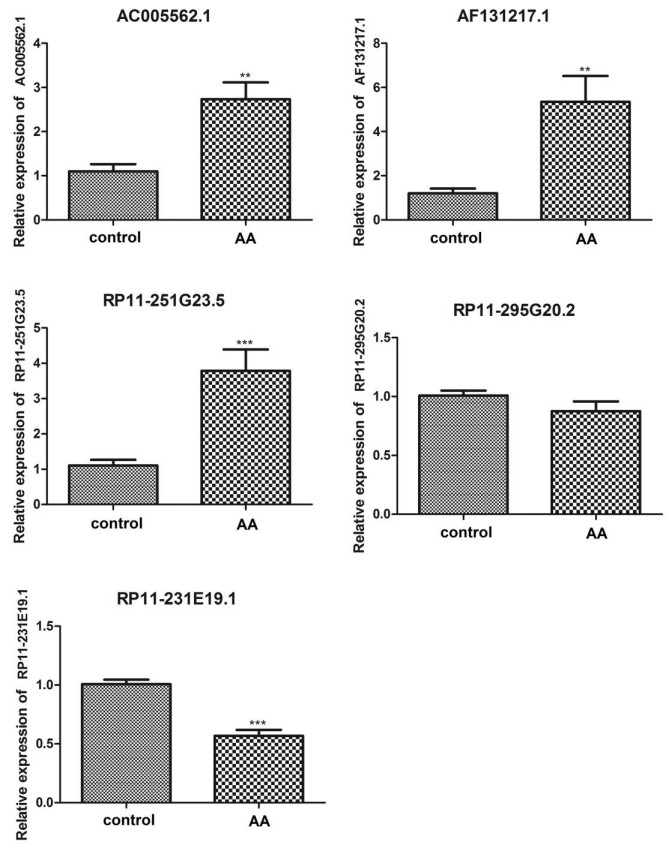
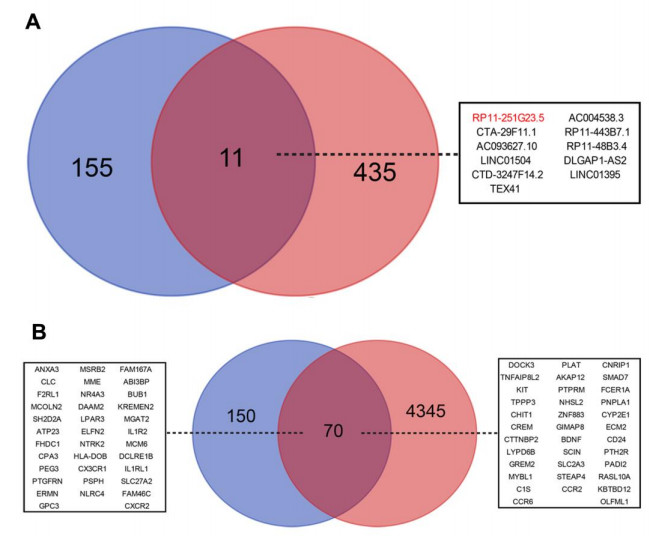
Figures(7) / Tables(3)

Sisi Qi, Youyu Sheng, Ruiming Hu, Feng Xu, Ying Miao, Jun Zhao, Qinping Yang. Genome-wide expression profiling of long non-coding RNAs and competing endogenous RNA networks in alopecia areata[J]. Mathematical Biosciences and Engineering, 2021, 18(1): 696-711. doi: 10.3934/mbe.2021037







 DownLoad:
DownLoad: