Citation: Reymundo Itzá Balam, Francisco Hernandez-Lopez, Joel Trejo-Sánchez, Miguel Uh Zapata. An immersed boundary neural network for solving elliptic equations with singular forces on arbitrary domains[J]. Mathematical Biosciences and Engineering, 2021, 18(1): 22-56. doi: 10.3934/mbe.2021002

| [1] | I. J. Goodfellow, Y. Bengio, A. Courville, Deep Learning, MIT Press, Cambridge, 2016. |
| [2] | G. Shrivastava, S. Karmakar, M. K. Kowar, P. Guhathakurta, Application of artificial neural networks in weather forecasting: a comprehensive literature review, Int. J. Comput. Appl., 51 (2012), 17-29. |
| [3] | Q. Zhong, Y. Liu, X. Ao, B. Hu, J. Feng, J. Tang, et al., Financial Defaulter Detection on Online Credit Payment via Multi-view Attributed Heterogeneous Information Network, Proc. Web Conf. 2020, (2020), 785-795. |
| [4] |
M. Lam, Neural network techniques for financial performance prediction: integrating fundamental and technical analysis, Decis. Support Syst., 37 (2004), 567-581. doi: 10.1016/S0167-9236(03)00088-5

|
| [5] | G. Youyang, COVID-19 Projections Using Machine Learning, 2020. Available from: https: //covid19-projections.com/about. |
| [6] |
J. Han, A. Jentzen, E. Weinan, Solving high-dimensional partial differential equations using deep learning, Proc. Natl. Acad. Sci., 115 (2018), 8505-8510. doi: 10.1073/pnas.1718942115
|
| [7] |
J. Sirignano, K. Spiliopoulos, DGM: A deep learning algorithm for solving partial differential equations, J. Comput. Phys., 375 (2018), 1339-1364. doi: 10.1016/j.jcp.2018.08.029
|
| [8] | K. Xu, E. Darve, The neural network approach to inverse problems in differential equations, preprint, arXiv: 1901.07758. |
| [9] |
M. Raissi, P. Perdikaris, G. E. Karniadakis, Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations, J. Comput. Phys., 378 (2019), 686-707. doi: 10.1016/j.jcp.2018.10.045
|
| [10] | C. Michoski, M. Milosavljevic, T. Oliver, D. Hatch, Solving irregular and data-enriched differential equations using deep neural networks, preprint, arXiv: 1905.04351. |
| [11] | K. Gurney, An introduction to neural networks, CRC press, Boca Raton, 1997. |
| [12] | A.G. Baydin, B.A. Pearlmutter, A.A. Radul, J.M. Siskind, Automatic differentiation in machine learning: a survey, preprint, arXiv: 1502.05767. |
| [13] | S. Marsland, Machine learning: an algorithmic perspective, CRC press, Boca Raton, 2015. |
| [14] | S. Pattanayak, Pro deep learning with tensorflow: A mathematical approach to advanced artificial intelligence in python, Apress, New York, 2017. |
| [15] | G. Zaccone, R. Karim, Deep learning with tensorFlow: Explore neural networks and build intelligent systems with python, Packt Publishing Ltd, Birmingham, 2018. |
| [16] | M. A. Nielsen, Neural networks and deep learning, Determination press, San Francisco, 2015. |
| [17] | Z. Mao, A. D. Jagtap, G. E. Karniadakis, Physics-informed neural networks for high-speed flows, Comput. Methods Appl. Mech. Eng., 360 (2020), 112789. |
| [18] | L. Sun, H. Gao, S. Pan, J. X. Wang, Surrogate modeling for fluid flows based on physics-constrained deep learning without simulation data. Comput. Methods Appl. Mech. Eng., 361 (2020), 112732. |
| [19] |
M. Raissi, A. Yazdani, G. E. Karniadakis, Hidden fluid mechanics: Learning velocity and pressure fields from flow visualizations, Sci., 367 (2020), 1026-1030. doi: 10.1126/science.aaw4741
|
| [20] | J. Berg, K. Nyström, A unified deep artificial neural network approach to partial differential equations in complex geometries, Neurocomputing, 317 (2018), 28-41. |
| [21] |
E. Weinan, B. Yu, The deep Ritz method: a deep learning-based numerical algorithm for solving variational problems, Commun. Math. Stat., 6 (2018), 1-12. doi: 10.1007/s40304-018-0127-z
|
| [22] |
C. Anitescu, E. Atroshchenko, N. Alajlan, T. Rabczuk, Artificial neural network methods for the solution of second order boundary value problems, Comput. Mater. Continua, 59 (2019), 345-359. doi: 10.32604/cmc.2019.06641
|
| [23] | L. Lu, X. Meng, Z. Mao, G. E. Karniadakis, DeepXDE: A deep learning library for solving differential equations, preprint, arXiv: 1907.04502. |
| [24] | A. Koryagin, R. Khudorozkov, S. Tsimfer, PyDEns: A python framework for solving differential equations with neural networks, preprint, arXiv: 1909.11544. |
| [25] | J. Han, M. Nica, A.R. Stinchcombe, A derivative-free method for solving elliptic partial differential equations with deep neural networks, preprint, arXiv: 2001.06145. |
| [26] | Y. Zang, G. Bao, X. Ye, H. Zhou, Weak adversarial networks for high-dimensional partial differential equations, J. Comput. Phys., (2020), 109409. |
| [27] |
C. S. Peskin, Flow patterns around heart valves: a numerical method, J. Comput. Phys., 10 (1972), 252-271. doi: 10.1016/0021-9991(72)90065-4
|
| [28] |
C. S. Peskin, Numerical analysis of blood flow in the heart, J. Comput. Phys., 25 (1977), 220-252. doi: 10.1016/0021-9991(77)90100-0
|
| [29] | Y. Kim, C. S. Peskin, Penalty immersed boundary method for an elastic boundary with mass, Physics of Fluids, 19(5) (2007), 053103. |
| [30] |
Y. Mori, C. S. Peskin, Implicit second-order immersed boundary methods with boundary mass, Comput. Methods Appl. Mech. Eng., 197 (2008), 2049-2067. doi: 10.1016/j.cma.2007.05.028
|
| [31] |
Y. Kim, C. S. Peskin, 2-D parachute simulation by the immersed boundary method, SIAM J. Sci. Comput., 28 (2006), 2294-2312. doi: 10.1137/S1064827501389060
|
| [32] |
S. Lim, A. Ferent, X. S. Wang, C. S. Peskin, Dynamics of a closed rod with twist and bend in fluid, SIAM J. Sci. Comput., 31 (2008), 273-302. doi: 10.1137/070699780
|
| [33] | P. J. Atzberger, C. S. Peskin, A Brownian dynamics model of kinesin in three dimensions incorporating the force-extension profile of the coiled-coil cargo tether, Bull. Math. Biol., 68 (2006), 131. |
| [34] |
P. J. Atzberger, P. R. Kramer, C. S. Peskin, Stochastic immersed boundary method incorporating thermal fluctuations, Proc. Appl. Math. Mech., 7 (2007), 1121401-1121402. doi: 10.1002/pamm.200700197
|
| [35] | T. G. Fai, B. E. Griffith, Y. Mori, C. S. Peskin, Immersed boundary method for variable viscosity and variable density problems using fast constant-coefficient linear solvers I: Numerical method and results, SIAM J. Sci. Comput., 35 (2013), B1132-B1161. |
| [36] | C. S. Peskin, The immersed boundary method, Acta Numerica, 11 (2002), 479-517. |
| [37] | R. Mittal, G. Iaccarino, Immersed boundary methods, Annu. Rev. Fluid Mech., 37 (2005), 239-261. |
| [38] |
R. J. Leveque, Z. Li, The immersed interface method for elliptic equations with discontinuous coefficients and singular sources, SIAM J. Numer. Anal., 31 (1994), 1019-1044. doi: 10.1137/0731054
|
| [39] | D. A. Fournier, H. J. Skaug, J. Ancheta, J. Ianelli, A. Magnusson, M. N. Maunder, et al., Ad model builder: using automatic differentiation for statistical inference of highly parameterized complex nonlinear models, Optim. Methods Software, 27 (2012), 233-249. |
| [40] | M. Abadi, A. Agarwal, P. Barham, E. Brevdo, Z. Chen, C. Citro, et al, Tensorflow: Large-scale machine learning on heterogeneous distributed systems, preprint, arXiv: 1603.04467. |
| [41] | R. Byrd, P. Lu, J. Nocedal, C. Zhu, A limited memory algorithm for bound constrained optimization. SIAM J. Sci. Comput., 16 (1995), 1190-1208. |
| [42] | W. Qi, M. Yue, Z. Kun, T. Yingjie, A Comprehensive Survey of Loss Functions in Machine Learning, Ann. Data Sci., 1 (2020), 1-26. |
| [43] | F. Zhengqing, L. Goulin, G. Lanlan, Sequential quadratic programming method for nonlinear least squares estimation and its application, Math. Probl. Eng., 2019(2019). |
| [44] | J. Alberty, C. Carstensen, S. A. Funken, Remarks around 50 lines of Matlab: short finite element implementation. Numer. algorithms, 20 (1999), 117-137. |
| [45] | F. Civan, C. M. Sliepcevich, Solution of the Poisson equation by differential quadrature. Int. J. Numer. Methods Eng., 19 (1983), 711-724. |
| [46] | J. Hua, J. Lou, Numerical simulation of bubble rising in viscous liquid. J. Comput. Phys., 222 (2007), 769-795. |
| [47] | M. Uh, S. Xu, The immersed interface method for simulating two-fluid flows. Numer. Math. Theory, Methods Appl., 7 (2014), 447-472. |






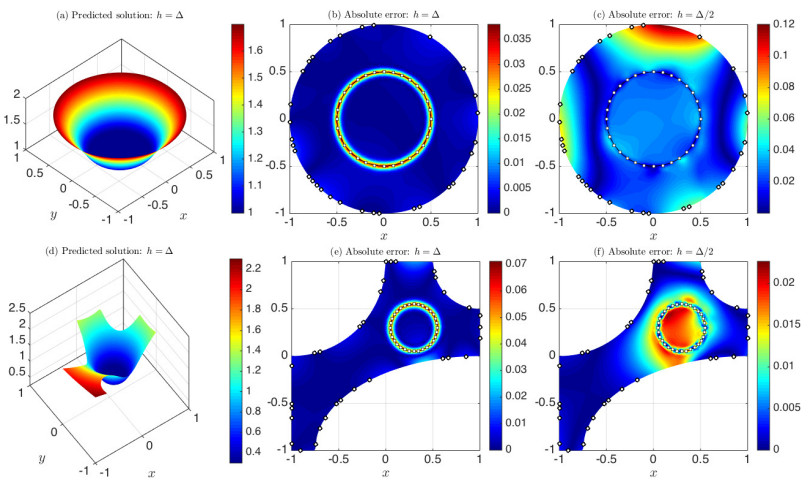
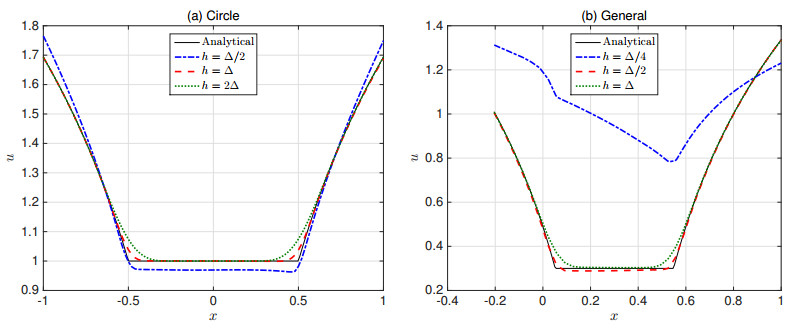
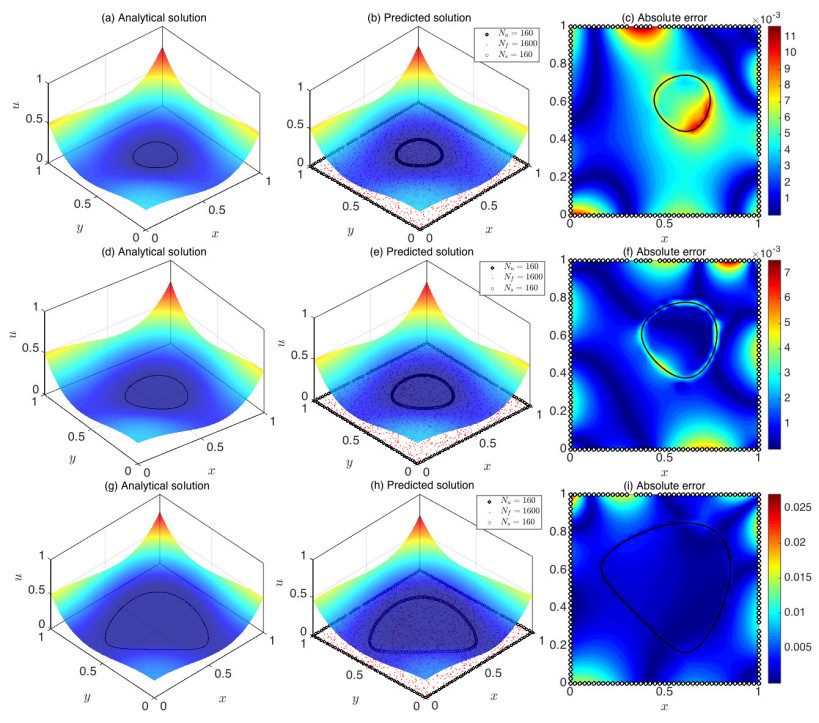
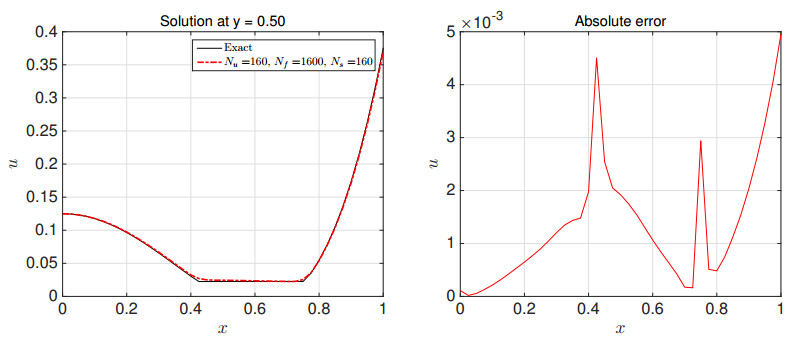
Figures(22) / Tables(18)

Reymundo Itzá Balam, Francisco Hernandez-Lopez, Joel Trejo-Sánchez, Miguel Uh Zapata. An immersed boundary neural network for solving elliptic equations with singular forces on arbitrary domains[J]. Mathematical Biosciences and Engineering, 2021, 18(1): 22-56. doi: 10.3934/mbe.2021002







 DownLoad:
DownLoad: